合约升级模式分析
- aisiji
- 发布于 2021-12-20 15:49
- 阅读 8912
在这篇文章中,我们将详细分析现有的智能合约升级策略,描述我们在实践中观察到的弱点,并为需要升级的合约提供建议。
对两种合约升级模式的分析
编者注: 原文发表于 2018 年 9 月,当时没有成熟的库或工具来实现升级。现在有了 upgrades-plugins 让升级变得简单很多。 不过文中提到的很多关于合约升级的问题,在今天来看依旧非常有价值,也是社区选择翻译它的原因。
智能合约设计的一个流行趋势是促进可升级合约的发展。在 Trail of Bits ,我们已经审查了很多可升级合约,并认为这一趋势的方向是错误的。现有的升级合约的技术有缺陷,大大增加了合约的复杂性,容易产生 bug 。为了强调这一点,我们发布了 Zeppelin 合约升级策略中一个以前不为人知的缺陷,这也是最常见的升级方法之一。
在这篇文章中,我们将详细分析现有的智能合约升级策略,描述我们在实践中观察到的弱点,并为需要升级的合约提供建议。在后续的博文中,我们将详细介绍一种方法,即合约迁移,它可以实现同样的好处,而少有缺点。
可升级合约的概述
可升级的智能合约已经出现了两种模式:
数据分离:逻辑和数据被保存在不同的合约中。逻辑合约拥有并调用数据合约。
基于delegatecall的代理,逻辑和数据也被保存在不同的合约中,但数据合约(代理)通过 delegatecall调用逻辑合约。
数据分离模式的优点是简单。它不需要像 delegatecall模式那样的底层的专业知识。不过,最近delegatecall模式受到了广泛的关注。开发人员可能倾向于选择这种解决方案,因为文档和例子更容易找到。
这两种模式都有相当大的风险,但在趋势之下,这种风险并未被重视。
数据分离模式
数据分离模式将逻辑和数据保持在不同的合约中。拥有数据合约的逻辑合约可以在需要时进行升级。数据合约是不可以升级的。只有所有者可以改变其内容。
 图1:数据分离升级模式
图1:数据分离升级模式
在考虑这种模式时,要特别注意这两个方面:如何存储数据,以及如何进行升级。
数据存储策略
如果在整个升级过程中需要的变量保持不变,你可以使用一个简单的设计,即让数据合约持有这些变量,以及它们的getters和setters。只有合约所有者能够调用setters。
contract DataContract is Owner {
uint public myVar;
function setMyVar(uint new_value) onlyOwner public {
myVar = new_value;
}
}图2:数据存储实例
你必须清楚地确定所需的状态变量。这种方法适用于基于 ERC20 代币的合约,因为它们只需要存储余额。
如果未来的升级需要新的存储变量,它们可以被存储在第二个数据合约中。你可以在不同的合约中分割数据,但代价是额外的逻辑合约调用和授权。如果你不打算经常升级合约,额外的成本可能是可以接受的。
这并不阻止将状态变量添加到逻辑合约中。这些变量在升级过程中不会被保留,但对于实现逻辑来说是有用的。如果你想保留它们,你也可以把它们迁移到新的逻辑合约中。
key-value pair
键值对系统是上述简单数据存储方案的一个替代方案。它更适应变化,但也更复杂。如你可以声明一个从bytes32键值到每个基本变量类型的映射:
contract DataContract is Owner {
mapping(bytes32 => uint) uIntStorage;
function getUint(bytes32 key) view public returns(uint) {
return uintStorage[key];
}
function setUint(bytes32 key, uint new_val) onlyOwner public {
uintStorage[key] = new_val;
}
}图3:键值存储示例(使用 onlyOwner )。
这种解决方案通常被称为永恒存储模式。
如何进行升级
这种模式提供了几种不同的策略,取决于数据的存储方式。
最简单的方法之一是将数据合约的所有权转移到一个新的逻辑合约,然后禁用原来的逻辑合约。要禁用之前的逻辑合约,需要将旧的逻辑合约暂停或者将旧的逻辑合约指向数据合约的0X0 。
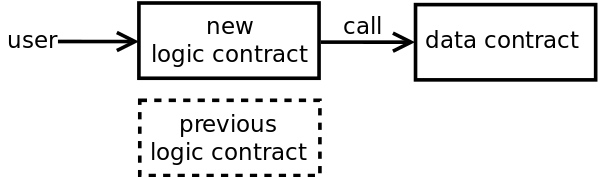
图4:通过部署新的逻辑合约和禁用旧的逻辑合约进行升级
另一个解决方案是将旧逻辑合约的调用转移到新逻辑合约。
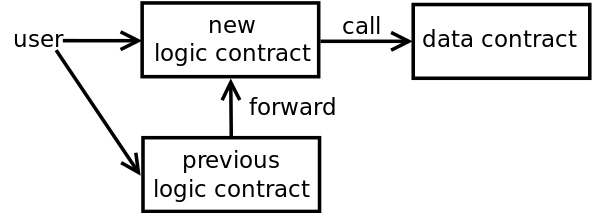
图5:部署一个新逻辑合约并从旧逻辑合约调用转移到新的逻辑合约
如果你只想让用户调用第一个合约,这个解决方案是有用的。然而,它增加了复杂性;你必须维护更多的合约。
最后,一个更复杂的方法,用第三个合约作为一个切入点,它由一个可变指针来指向逻辑合约。
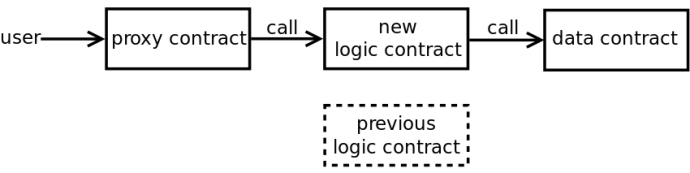
图6:部署一个代理合约来调用新的逻辑合约
代理合约为用户提供了一个固定的入口,并对责任进行了区分,比调用转移方案更清晰。然而,它也带来了额外的Gas成本。
Cardstack和Rocket-pool有数据分离模式的详细实现。
数据分离模式的风险
数据分离模式看似简单,但其实不是这样的。这种模式增加了代码的复杂性,并且需要更复杂的授权模式。我们已经很多次看到客户错误地部署了这种模式。例如,有一个客户还实现了相反的效果,根本无法升级,因为他的一些逻辑是在数据合约中的。
根据我们的经验,开发者也知道永恒存储模式非常具有挑战。我们看到开发者将值存储为bytes32,然后用类型转换来获取原来的值。这增加了数据模型的复杂性,以及出现细微缺陷的可能性,不熟悉复杂数据结构的开发者可能会容易犯错。
基于delegatecall的代理模式
像数据分离模式一样,代理模式将合约一分为二:一个逻辑合约,一个代理合约(持有数据)。有什么不同?在这种模式中,代理合约用delegatecall调用逻辑合约(与之前调用次序相反)。

图7:代理模式
在这种模式下,用户与代理合约交互,合约逻辑是可以升级。这个解决方案需要掌握delegatecall,以允许一个合约使用另一个合约的代码。
让我们回顾一下delegatecall是如何工作的。
delegatecall背景知识
delegatecall允许一个合约执行另一个合约的代码,同时保持调用者的上下文(包括存储)不会变。delegatecall操作码的一个典型使用场景是实现library。如:
pragma solidity ^0.4.24;
library Lib {
struct Data { uint val; }
function set(Data storage self, uint new_val) public {
self.val = new_val;
}
}
contract C {
Lib.Data public myVal;
function set(uint new_val) public {
Lib.set(myVal, new_val);
}
}图8:基于 delegatecall 操作码的库实例
这里,将部署两个合约: Lib 和 C。在 C 中对 Lib 的调用将通过delegatecall完成。
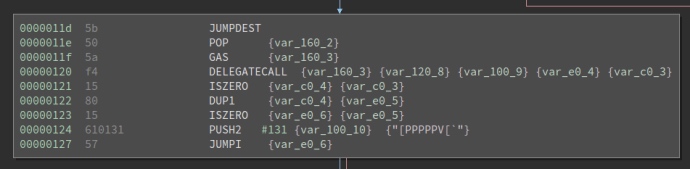
图9:调用 Lib.set 的 EVM 操作码(Ethersplay)
因此,当Lib.set改变self.val时,它改变了存储在 C 的myVal变量中的值。
Solidity 看起来像 Java 或 JavaScript ,它们都是面向对象的语言。你会觉得它很熟悉,但因此也会对它产生一些错误的认识和假设。在下面的例子中,程序员可能会认为,只要两个合约变量共享相同的名字,那么它们就会共享相同的存储空间,但在 Solidity 中并不是这样的。
pragma solidity ^0.4.24;
contract LogicContract {
uint public a;
function set(uint val) public {
a = val;
}
}
contract ProxyContract {
address public contract_pointer;
uint public a;
constructor() public {
contract_pointer = address(new LogicContract());
}
function set(uint val) public {
// Note: the return value of delegatecall should be checked
contract_pointer.delegatecall(bytes4(keccak256("set(uint256)")), val);
}
}图10:危险的委托调用用法
下面图11表示两个合约在部署时的代码和存储变量:
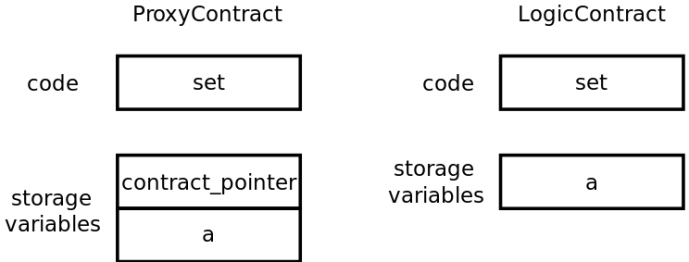
图11:图10的内存图示
当delegatecall被执行时会发生什么?LogicContract.set将写入ProxyContract.contract_pointer而不是ProxyContract.a。这种内存损坏发生的原因是:
LogicContract.set是在 ProxyContract 内执行的。LogicContract只知道一个状态变量:a。这个变量的任何存储都将在内存中的第一个元素上进行(参见存储中的状态变量布局文档)。ProxyContract的第一个元素是contract_pointer。因此,LogicContract.set将写入ProxyContract.contract_pointer变量而不是ProxyContract.a(见图12)。- 此时,
ProxyContract中的内存已经被破坏了。
如果 a是 ProxyContract中声明的第一个变量,delegatecall就不会破坏内存。
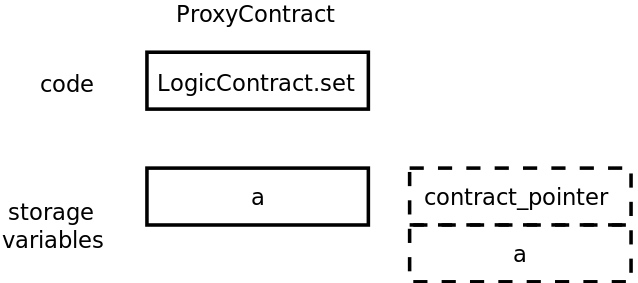
图12:LogicContract.set 将在存储中写入第一个元素。ProxyContract.contract_pointer
谨慎使用 delegatecall,特别是当被调用的合约有声明的状态变量时。
让我们回顾一下基于 delegatecall的不同数据存储策略。
数据存储策略
在使用代理模式时,有三种方法可以将数据和逻辑分开:
- 继承存储:它使用 Solidity 继承来确保调用者和被调用者有相同的内存布局。
- 永恒存储,这是我们上面看到的逻辑分离的键值存储版本。
- 非结构化存储,这是唯一不会因为内存布局不正确而造成潜在内存损坏的策略。它依赖于内联汇编代码和存储变量的自定义内存管理。
参见ZeppelinOS,对这些方法进行了更全面的回顾。
如何进行升级
将代理合约指向一个新的逻辑合约,以前的逻辑合约就被丢弃了。
委托调用的风险
根据我们客户的经验,我们发现实际上正确应用基于delegatecall的代理模式是很难的。代理模式需要升级过程中合约和编译器始终保持一致。开发者如果不熟悉 EVM 内部结构很容易在升级过程中引入严重错误。
只有一种方案,即非结构化存储,它不受内存布局要求的限制,但它要求低级别的内存处理,这很难实现和也不利于审查。由于它极其复杂,非结构化存储只用于存储对可升级合约非常重要的状态变量,比如指向逻辑合约的指针。此外,这种方案阻碍了 Solidity 的静态分析(如Slither),使合约失去了这些工具提供的保证。
用自动化工具防止内存布局损坏是一个正在进行的研究领域。当前没有任何现有的工具可以验证升级是安全的,不损害内存接口。使用 delegatecall的升级将缺乏自动化的安全保证。
打破了代理模式
我们发现并公布了 Zeppelin 代理模式中一个以前未知的安全问题,其根源在于delegatecall的复杂语义。它影响了我们所调查的所有 Zeppelin 实现。这个问题突出了使用低级 Solidity 机制的复杂性,并说明了这种模式的实现有可能存在缺陷。
是什么Bug?
Zeppelin 代理合约在返回之前并不检查合约是否存在。因此,代理合约可能在调用失败时返回成功,如果调用结果是应用程序逻辑所需要的,则会导致错误的行为。
低级别调用,包括汇编,缺乏高级别 Solidity 调用所提供的保护。特别是,低级别调用不会检查被调用账户是否有代码。Solidity 文档警告说:
如果被调用的账户不存在,作为EVM设计的一部分,低级别调用,
delegatecall和调用代码将返回成功,如果需要,必须在调用前检查是否存在。
如果delegatecall的目标没有代码,那么调用将成功返回。如果代理设置不正确,或者目标被破坏,任何对代理的调用都会成功,但不会发回数据。
调用代理的合约可能会在假设其交互成功的情况下改变自己的状态,尽管它们并不成功。
如果调用者不检查返回的数据的大小,这是任何用 Solidity 0.4.22 或更早编译的合约的情况,那么任何调用都会成功。由于对 returndatasize的检查,最近编译的合约(Solidity 0.4.24及以上版本)情况稍好。然而,这个检查并不能保护那些不期望有数据返回的调用。
ERC20 token 面临相当大的风险
许多ERC20 token 有一个已知的缺陷,transfer函数没有返回数据。因此,这些合约支持对transfer()的调用,可能没有返回数据。在这种情况下,缺乏上文详述的存在性检查,可能会导致第三方认为代币转移是成功的,而事实并非如此,并可能导致资金被盗。
漏洞情况
Bob 的 ERC20 智能合约是一个基于delegatecall的代理合约。由于人为错误(代码中的缺陷或恶意行为),代理被错误地设置。任何对 token 的调用都被认为是成功的调用,没有数据返回。
Alice 交易所处理 ERC20 token ,在转账时不返回数据 。Eve 没有 token ,Eve 调用 Alice 交易所的存款函数,以获得 10,000 个 token ,该函数调用 Bob 的 token 的transferFrom,这个调用是成功的。Alice 交易所将 10,000 个 token 记入 Eve 的账户,Eve 卖出 token ,并免费获得了以太币。
如何避免
在升级过程中,检查新的逻辑合约是否有代码。一个解决方案是使用 extcodesize 操作码。另外,你可以在每次使用 delegatecall 时检查目标是否存在。
有一些工具可以提供帮助。例如,Manticore 能够审查你的智能合约代码,以便在对其进行任何调用之前检查合约是否存在。这种检查是为了帮助减轻有风险的代理合约升级。
编者注:在进行转账时,应该总是使用 TansferHelper 的 safeTransfer
建议
如果你必须设计一个智能合约的升级方案,请根据你的情况使用最简单的方案。
在所有情况下,避免使用内联汇编和低级调用。正确使用这一功能需要对 delegatecall的语义以及 Solidity 和 EVM 的内部结构非常熟悉。在我们审查的代码中,很少有团队能做到这一点。
数据分离模式建议
如果你需要存储数据,请选择简单的数据存储策略,而不是键-值对(又称永恒存储)。这种方法需要编写的代码较少,并且依赖的会变化的部分相对较少,可能出错的地方相对较少。
使用丢弃合约的解决方案来执行升级,避免使用调用转移的解决方案,因为它需要建立转发逻辑,可能太复杂而无法正确实现。只有在你需要一个固定地址时才使用代理解决方案。
代理模式建议
在调用 delegatecall 之前,检查目标合约是否存在。Solidity 不会代表你执行检查,但忽视检查可能导致非预期的行为和安全问题。如果依赖低级别的功能,你需要负责这些检查。
如果你正在使用代理模式,你必须:
对以太坊的内部有详细的了解,包括 delegatecall的精确机制以及 Solidity 和 EVM 内部的详细知识。
认真考虑继承的顺序,因为它影响内存布局。
认真考虑变量的声明顺序,例如,变量的覆盖,甚至类型的改变(如下所述)都会影响程序员与delegatecall交互时的意图。
注意编译器可能会使用填充和/或将变量打包在一起,例如,如果将两个连续的 uint256 改为两个 uint8,编译器可以将这两个变量存储在一个槽中,而不是两个。
确认变量的内存布局是否得到重视,如果使用不同版本的 solc 或者启用不同的优化功能。不同版本的 solc 计算存储偏移的方式不同。变量的存储顺序可能会影响 Gas 成本、内存布局,从而影响delegatecall的结果。
仔细考虑合约的初始化,根据代理变体,状态变量在构建过程中可能无法初始化。因此,在初始化过程中存在一个潜在的竞赛条件,需要加以缓解。
仔细考虑代理中的函数名称,以避免函数名称碰撞。与预定函数具有相同Keccak 哈希值的代理函数将被调用,这可能导致不可预测的或恶意的行为。
结论性意见
我们强烈建议不要对可升级的智能合约使用这些模式。这两种策略都有可能出现缺陷,大大增加复杂性,并引入错误,最终降低对你的智能合约的信任。努力追求简单、不可变和安全的合约,而不是导入大量的代码来推迟功能和安全问题。
此外,审查智能合约的安全工程师不应推荐复杂的、不甚了解的、可能不安全的升级机制。以太坊安全社区,在认可这些技术之前要考虑风险。
在后续的博文中,我们将描述合约迁移,这是我们推荐的可以实现和升级合约一样的效果的方法,同时没有升级带来的缺点。在私钥被破坏的情况下,合约迁移策略是必不可少的,并有助于避免其他升级的需要。
同时,如果你担心你的升级策略可能不安全,你应该联系我们。
本翻译由 CellETF 赞助支持。
- 学分: 82
- 分类: Solidity
- 标签: delegatecall 合约升级 智能合约





