突破区块链不可能三角(四) — 区块链中的BFT及HotStuff BFT(Libra BFT)分析
- maxdeath
- 发布于 2020-01-20 17:30
- 阅读 9958
系列四 — 区块链中的BFT及HotStuff BFT(Libra BFT)分析
本系列文章:
- 扩容,扩展,与无限扩展
- 在比特币POW之上的尝试
- POS与POW-DAG
- 区块链中的BFT及HotStuff BFT(Libra BFT)分析
- 闪电网络,链下技术,以及它们的局限性
- 吹个关于区块链活性的哨子
- 分片(上)
- 分片(中)
- 分片(下)
实际上,在我关于BFT的那个系列中我简单地介绍了一下在区块链时代的BFT,其中,不得不说,有一部分是不够完善的。
更确切地说,那篇写作在我读到Hotstuff BFT之前,所以,其实在将BFT和中本聪共识(即类似于比特币的最长链共识)放在一起比较的时候,我更多的是从输出的角度,更确切地说,是根据最理想状态下的输出大小进行对比的,比如,我从消息复杂度的角度,将所有在最优情况中消息复杂度在O(N)的共识算法,无论是BFT还是中本聪共识,都作为一类来比较。因为在区块链的实际应用中,我们把两种共识都当做“无法篡改”的,而忽略了两者实际上在共识上的差异。而这一点其实对于分布式系统的研究者来说,是不够严谨的。
于是,这就造成了这个专栏在BFT介绍中的一个疏漏——在这个主要以“输出”和“可扩展”为主线的系列里,似乎并没有一个合适的介绍Hotstuff BFT的位置。而另一方面,在之前介绍BFT的文章中,由于也是以“输出”为主线的,我们也没有足够清晰地介绍BFT的一些基础问题,于是也无法自然而然地引入关于Hotstuff的介绍。
但另一方面,Hotstuff无论从它在BFT和中本聪共识之间搭起了一座坚实的桥梁的重要性上,以及它被Libra拿来使用的热度上,或者在它本身的实用性和优秀性能上,都正如其名,是一个炙手可热不得不提的重要问题。因此,在插播了一篇介绍LibraBFT背后的Hotstuff BFT的文章之后,我准备在这篇里稍微偏离一些这个系列“输出和可扩展”这个主线,来更全面地讲一讲在区块链中的BFT。
(注:感谢Hotstuff作者尹茂帆同学在报告中对于共识算法的精彩介绍,本文中部分引用他在报告和论文中的思路来阐述BFT和中本聪共识的关系)
从区块链的视角看来,拜占庭容错算法和中本聪共识已经远不如曾经那样泾渭分明——例如说道公有链,非许可链我们就需要用中本聪共识,而联盟链和许可链我们才可以用BFT;或者说BFT只在小网络里可用,而大网络就只能用中本聪共识。
现在,我们知道其实我们可以把POW仅仅看做一个进入门槛来防止女巫攻击(一个人伪造多个节点的攻击方式),同时我们知道我们可以在大网络采用采用可扩展的BFT,那么两者的区别到底在哪呢?
一致性与活性的永恒战争
在之前的BFT的部分中,我们介绍了所有区块链系统的一致目标:我们希望同时满足一致性和活性(在这里,我们只考虑传统的链式结构,DAG的原理类似)。
- 一致性:如果一个诚实节点认为在区块链的某个高度h的区块是B,那么不会有任何其他诚实节点认为高度h的区块是 B',B'不等于B。
- 活性:系统可以持续对新区块达成共识。
反过来说,我们还可以这么理解这两个属性 —— 我们必须保证如下的情况不会出现:
情况1(一致性):
一个诚实节点a认为高度h的区块是B,而另一个诚实节点b认为高度h的区块是B'。
情况2(活性):
一个诚实节点a无法确认新的区块。
这两者看起来简单,但是,想要在异步系统中100%的同时满足两者是非常困难的事情 —— 困难到什么地步呢?建议读者先向下拉浏览一下这篇的内容,做好心理准备,本篇大部分的内容,其实都在讲这个问题。
我们先考虑一个最简单的情况。
首先,为了保证活性,我们需要这个网络中的节点发布新区块,于是,我们简单地规定诚实节点当收到新区块时就确认。
情况3:
假设一个诚实节点a在高度h广播了区块B,然后另一个诚实节点b收到了这个区块。
这个时候,如果他接收并确认这个区块,那么就可能会出现情况1——也许另一个诚实节点c没有收到B,于是在高度h发了B',而诚实节点d接受并确认了这个B',于是,b和d就产生了不一致。
这里可能有两点疑问:
1,为什么会出现两个诚实节点a和c都发了新区块的情况呢?为什么不能设置一个时刻表不让诚实节点同时出块,而是让它们轮流出块呢?
实际上,我们当然希望这样做,只不过这件事在异步系统中远没有想象中的容易。
一种最简单的方法,是设一个时刻表,规定今天下午1点10分是a的出块时间,1点20分是b的出块时间…… 这种方法虽然简单粗暴,但是在一个同步系统,或者说,在消息延时是有上界的系统中,是可行的。然而,如果我们换了一个异步系统,我们的确可以采用这种方法,但是由于消息的延时没有上界,所以无论这个时刻表两个节点出块间隔多长,我们都无法保证不会出现情况3。
另一种最简单的思路是说,那么,为什么不排好一个顺序,比如把所有节点编好号,然后轮流出块。然后后一个节点等前一个节点出完块之后再出。
实际上,很多传统的BFT算法,例如PBFT,都是这么做的。然而,这并不能保证情况3不会出现。因为这里存在一个问题:后一个节点如何知道前一个节点没有出块呢?如果所有的节点都是诚实的,那这种方法没问题。但只要有哪怕一个节点可能故障(甚至不需要有恶意),那么这种方法就无法保证活性,因为后一个节点也许永远等不到前一个节点出块。
于是,我们必须规定一个时限 —— 在这个时限达到之后,如果诚实节点c判断上一个节点没有出块,那么他就应该出块了。
但是,实际上由于异步系统的原因,c的判断未必是对的,也许a发了区块只是c还没有收到。于是,这种方法仍旧无法避免两个诚实节点都出了块的情况。
比特币引入了一种新思路,即通过POW降低两个节点同时出块的几率,但实际上这种方法仍旧不能保证不会出现情况3,在异步网络中更是如此。
因此,实际上,我们并无法在异步网络中保证一个诚实节点不会同时受到两个诚实节点发出的区块。更深层次的原因其实仍旧是一致性(没有两个冲突的区块)和活性(确认新区块)的矛盾:如果我们想要保证一致,那么就无法保证活性,反之亦然。
于是,就有了第二个问题。
2,我们是不是能够换一种确认规则,来避免在有冲突区块的时候确认区块?
实际上,这就回到了经典拜占庭将军的轨道上,也是拜占庭容错问题一直致力于解决的问题——
当网络中存在两个冲突的区块的时候,如何确认才能保证一致性呢?
弱中止条件下的拜占庭将军问题告诉我们,这个时候我们需要每个节点都广播自己收到的区块,然后,当有了2f+1(f是恶意节点数量)个一致的答案的时候再确认,例如,如果自己收到的区块是B,然后,刨掉自己也发出去的消息,只需要再收到2f-1个节点发来的“我收到的是B”的消息,就可以确定——不会有另一个诚实节点对区块B'进行了确认。
于是,我们保证了一致。
然而,这里面有一个很重要的地方被忽略了——
我们仅仅保证了一致,但是还并没有保证活性,所以,我们还需要如下步骤来保证活性,即,最终所有诚实节点都能够确认B——
所有确认了B的节点再广播自己对于B的确认,所有收到f+1条“关于B的确认”的诚实节点也同样可以对B进行确认。
于是,我们保证了活性。
在之前的系列文章中,我对于这个问题的结论就是 —— 我们可以简单地把这种弱中止条件下的拜占庭当成一个黑盒子,然后设定某个失效条件,例如某个时限。于是,我们就得到了对于一般BFT的解决方法 —— 先确定一个领袖,然后如果失效则退出,换一个领袖,重新执行这个拜占庭将军问题,直到解决……
实际上,这个结论并不够严谨,因为我把一个非常关键的问题省略了 —— 即,如何在更换领袖的时候,保证所有的节点都能够对两个问题达成共识: 1,更换领袖这件事; 2,是否抛弃上一个区块。
但是在上一个系列中,由于这个部分过于复杂,我之后讨论路线就主要偏向于输出了。从而导致了本文开头时的那种尴尬状况——由于没能在那个系列讲清楚BFT,导致这个系列也没法好好讲输出……所以只能藉由这篇把这部分补上——
其实,以上这种简单的方法并不能解决以下的情况:
情况4:
诚实节点a收到2f+1条“收到B”的消息,这个时候他认为不会有另一个诚实节点确认不同的区块B',于是,他对B进行了确认,并发送了“确认B”。然而,在这个时候出现了大规模的网络异常,导致没有其他诚实节点成功收到2f+1个“收到B”的消息,同时也没有人收到f+1个B的“确认B”。然后,轮换中下一个出块节点b在长时间没有收到2f+1条区块B的消息之后,发了区块B'。这个时候,网络中的诚实节点c收到了B',广播自己收到了B'的消息,然后收到了2f+1条“收到B'”的消息但是并没有收到2f+1条“收到B”的消息,于是,c确认了区块B',导致一致性失效。
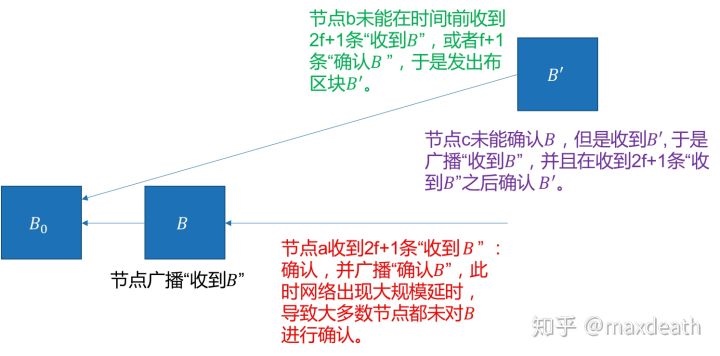
有人可能会觉得这似乎和在拜占庭将军问题里我们对于一致性的分析不一样——
“不是说好的收到2f+1条消息就不会不一致了吗?”
但是,如果仔细看看https://zhuanlan.zhihu.com/p/41329283这里对于这个拜占庭将军问题的描述就知道,这个方法只解决“弱中止”条件下的拜占庭将军问题,也就是说,只有在B的出块节点必须要发消息(可以不一致),而且,所有的节点都需要知道B的出块节点不会不发消息。
但在目前的系统里,这两点,尤其是后一点并不满足。
于是,尽管诚实节点a收到了2f+1条B的消息,但,尽管a知道如果所有节点一直等下去的话,一定可以达成共识,但其他的诚实节点此刻并不知道这一点。他们仍旧认为出块节点可能失效(或者恶意)。
于是,一致性和活性的矛盾再次出现 —— 为了保证活性,他们必须冒着失去一致性的风险让下一个出块者出块,最终导致不一致。
那么,如何解决这个问题呢?其实症结还是在确认的规则上——
我们仔细看看情况4中的问题,其实在于a不该这么快就对B进行确认,而应该确认没有更换领袖之后再对B进行确认。
于是,我们才有了PBFT的两阶段确认。
两阶段确认
同样是在情况4,在两阶段确认之中,当a收到2f+1条关于B的消息时,他并不是直接确认,而是进入“预备”状态,并且发一条“确认”消息表示自己正在“预备”。然后,如果一个诚实节点收到2f+1条“确认”消息之后,再进行确认。
同时,我们采用这样的节点轮换机制:
当节点达到time out之后,他会请求出块节点轮换,相当于说:我认为出块节点可能是恶意的,所以请求节点轮换。然后,当新的出块节点收到2f+1条请求之后,它广播新的区块,并且广播这2f+1条请求,公告大家他的确收到了这些请求。
于是,我们解决了情况4:
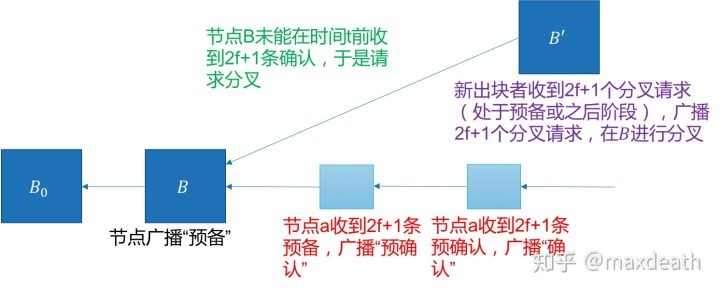
在情况4中,即便a节点已经收到2f+1条关于B的预备消息(第一轮的消息),但是他仅仅进入预备状态,因为此时他还并不确定共识是不是一定能达成,因为出块节点仍旧可能是恶意的,所以他知道其他节点还有节点轮换的可能。而这个时候另一个诚实节点b,如果他在time out之前只收到了不到2f+1条关于B的预备消息,于是他会发出领袖轮换请求。而如果有2f+1个节点都发出了这种请求的话,下一个出块的诚实节点c将会发出新的区块B'。这个时候,a节点由于并没有确认B,而由于2f+1个节点都已经请求节点轮换了,那么,a一定收不到2f+1个B的确认消息,于是无法对B进行确认,于是,如果他收到2f+1条B'的预备消息,他就会抛弃对于B的预备,而切换到B'上,这样,我们同时保证了一致性和活性。
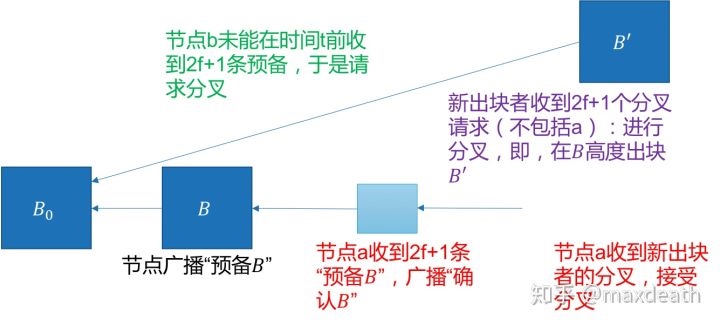
然而,虽然我们解决了情况4,却带来了新的问题——
情况5:
诚实节点a顺利通过了预备阶段,并且,收到2f+1条区块B的确认消息(第二轮),这个时候他认为不会有另一个诚实节点确认不同的区块B',于是,他对B进行了确认。然而,在这个时候出现了大规模的网络异常,导致其他诚实节点没有在timeout之前成功收到2f+1个关于区块B的确认消息,于是大部分节点还没有对B进行确认的情况下,发了轮换出块节点请求。然后,新节点在B的高度出块B',再次造成不一致。
对比上图,我们面临的问题是——即便需要2f+1个请求才能轮换节点,但是,仍旧可能出现某个诚实节点已经对B进行了确认,于是,我们需要对于新区块B'应该在B之前还是之后进行共识
情况5其实在纠结的是这样一件事:虽然我们在中间加了一轮,但是,为了保证活性,我们还是需要在某个条件下对于区块进行确认,而同时,我们必须允许在timeout的时候进行出块节点轮换。但是,怎么保证出块节点轮换的时候没有任何一个诚实节点已经确认呢?反过来说,我们回到了老问题,诚实节点在什么时候才知道自己确认的这个区块不会再被改动了呢?
这里,我们似乎又陷入了一致性与活性的循环之中——为了保证活性,我们不能吊死在一个出块节点上,需要进行节点轮换;但是另一方面,一旦轮换了节点,新出的块又会和之前达成的一致相冲突。
但其实,在这里,这是个伪命题。
因为其实两轮共识已经提供了可以解决这个问题的基础 —— PBFT做了如下的改动,解决了一致性与活性的矛盾:
所有节点在广播更换出块节点的申请的时候,需要同时广播自己的状态,同时给出自己处于这个状态的证据(例如,如果处于准备状态,就提交2f+1条来自不同节点的准备信息)。然后,新的出块节点根据收到的2f+1条信息中的状态决定是否替换掉B:
1,如果没有任何一个节点处于预备状态,则,至少有f+1个诚实节点还没有预备,于是不会有2f+1条确认消息,于是不会有任何一个诚实节点已经确认了区块B。于是,这个时候,新的出块节点会将自己的新区块B'放在同B一样的高度,替换掉B。然后,广播区块B'的同时,广播收到的所有轮换申请——向所有人说明这种情况。
2,如果有一个节点处于预备状态,则说明至少有f+1个诚实节点已经收到过B并且准备进入预备状态。这个时候我们可以确认,不可能有一些诚实节点由于不同步(例如一直处于timeout),以至于他们对于一条和B不一致的链进行了确认。那么,新的出块节点将新区块B'连在B之后,并且广播收到的所有轮换申请。这时,由于处于预备状态的节点的轮换申请里包括2f+1条预备消息,所有收到新区块B'的节点也同时收到了2f+1条预备消息,于是可以进入预备状态。换句话说,无论新的区块节点是谁,有没有恶意,或者是网络失活导致区块B'没有达成共识都没关系。只要新区快的发布者采用这种方法,我们可以在保证活性的同时,保证不会和已经达成共识的区块出现不一致。
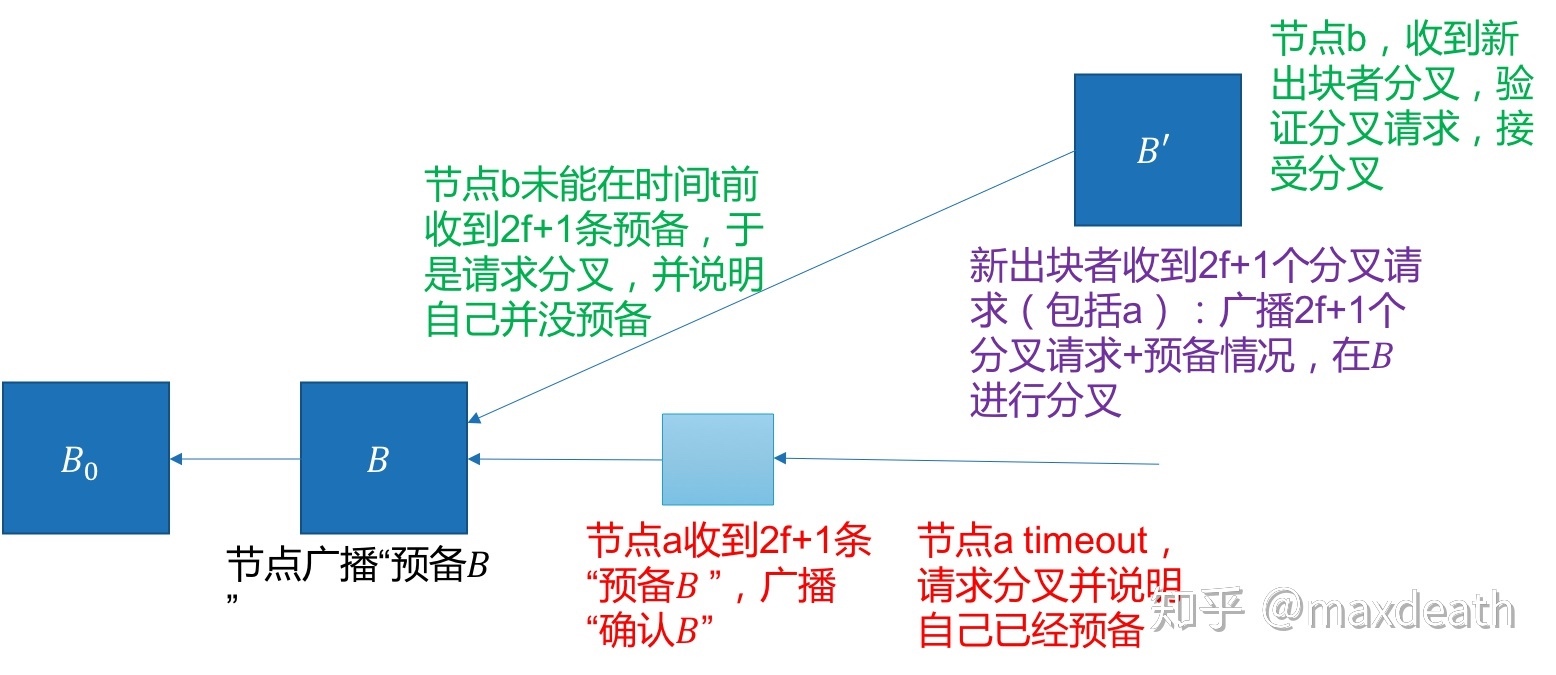
三阶段确认
然而,以上的方法有个非常严重的问题 —— 每次节点轮换的时候有极高的消息复杂度。
首先,节点轮换的时候,每个节点需要广播一个轮换请求,这里就是O(N^2)的消息复杂度,然后,轮换请求中还需要包括自己之前所收到的所有预备消息来说明现在的状态,于是,这里就有了O(N^3)的消息复杂度。
不仅如此,当下一个出块节点收到这些消息之后,他需要在发布区块的时候包含这些消息并且广播,于是,这里又有了O(N^3)的消息复杂度。
这对网络资源造成极大的消耗,同时,对于出块节点而言也是极大的负担。
这个问题其实存在于在拜占庭容错那个系列文章中介绍的所有采用“拜占庭将军问题(以下采用更常用的说法,拜占庭共识,即Byzantine Agreement)+领袖轮换”这种范式实现BFT的算法。也就是说,即便是之前讨论过的“可扩展的”,消息复杂度为O(N)的拜占庭容错算法,例如Zyzzyva或者链式BFT,都无法避免会遇到这个问题 —— 于是,尽管这些算法可以把理想状态下的消息复杂度降到O(N),但是,一旦出现节点轮换的情况,消息复杂度又变成O(N^3),于是仍旧无法适用于大网络。
这个问题几乎没怎么被人研究过,直到Hotstuff提出了三阶段共识。
与两阶段共识和三阶段共识的区别如同一阶段和两阶段的共识得区别一样,其中加了一轮确认。其中的目的其实就是降低两阶段共识中节点轮换的复杂度——更确切地说,两阶段共识中关于“前一个区块B是否已经达成共识”这件事的共识需要依靠每个节点发给新的出块节点,然后再广播给所有节点,造成了O(N^3)的消息复杂度。那么,如果干脆用一轮共识来决定这个问题会怎么样呢?
于是,我们得到了如下的三阶段共识方案:
诚实出块者广播区块B,诚实节点收到后发送关于B的“预备消息”,然后,当节点收到2f+1条预备消息之后,节点进入预备状态并广播“预确认消息”;然后,当节点收到2f+1条预确认消息时,节点进入预确认状态并广播“确认消息”;最后,当节点收到2f+1条确认消息的时候,确认区块B。
然后,这里面的节点轮换机制是:当节点达到timeout还没有达成共识的时候,节点广播自己的状态并申请更换出块者。然后,下一个出块者收集这些状态来决定新区块的高度:如果没有2f+1个节点在预备状态,则换掉B,如果有2f+1个节点在预备(或更高)状态,则把新区块出在B之后。
实际上,这种方法和两阶段共识的结果是一致的:
1,如果没有2f+1个节点在预备状态,则不可能有一个诚实节点已经进入确认状态,所以我们可以替换掉B。
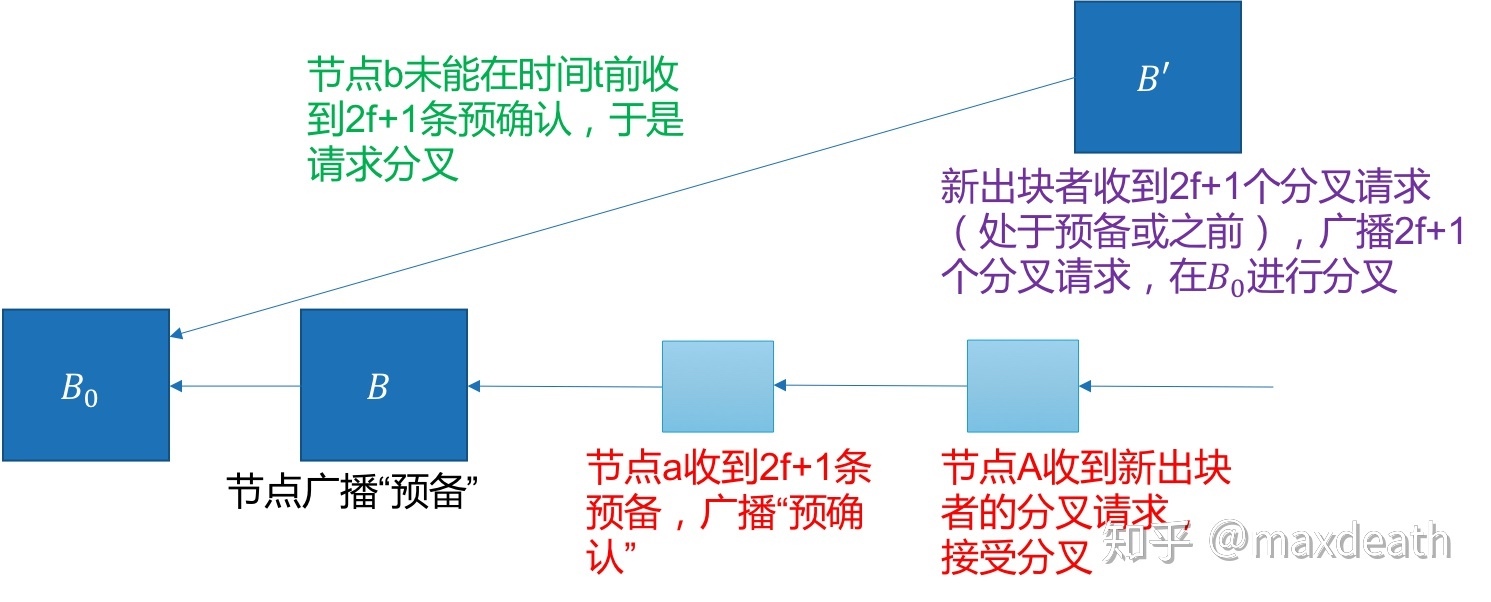
2,如果有2f+1个节点在预备(或更高)状态,则不可能有一个诚实节点确认了一条不包括B的链,所以这个时候新的区块出在B之后。
三阶段共识和两阶段共识的区别,在我看来可以这样理解——对于一个诚实节点,当他对于区块B达成了两轮共识,他就可以确认对于另一个冲突的区块B'达不成共识。于是在两阶段共识中,如果在两阶段共识过程中进行了节点轮换,我们无法仅通过节点现在的状态就判定: 1)是否有节点已经对B进行了确认; 2)是否有节点对另一个区块B'进行了共识。于是,我们需要在节点轮换的时候,让所有节点广播自己收到的所有消息,然后新的区块发布者再广播收到的消息。
但是,如果采用三阶段共识,那么我们可以仅通过节点现在所处的状态来判定这一点——1)如果2f+1个节点还没达成两轮共识,那么就不会有节点已经对B进行了确认;2)如果有2f+1个节点达成了两轮共识,那么就不会有节点对另一个区块B'达成了共识。
Hotstuff BFT
三阶段共识以外,Hotstuff BFT还采用了一些其他的技术。
门限签名
这里,我们就不深入探讨门限签名的具体实现方法了,只介绍门限签名可以做什么:
首先,n个节点可以通过某种密钥生成方法生成各自的私钥,然后,他们可以对于某个消息采取(k,n)门限签名。这个签名只有在收集到k个不同节点的签名“碎片”才能聚合成一个签名。于是,我们可以通过签名来验证某条消息经过n个节点中的k个的确认。
于是,我们可以用(2f+1, N)门限签名来代替2f+1个来自不同节点的消息,然后把消息复杂度降到O(N)。具体的方法是,当收到区块B的时候,每个节点发一个(2f+1, N)门限签名的碎片给出块节点,然后,出块节点将这些碎片聚合成一个完整的签名并且广播出去,于是,所有节点都可以通过验证这个签名,来判断是不是有2f+1个节点收到了并且确认了这条消息。
于是,采用三轮共识和门限签名的BFT是这样的:
出块节点广播消息B,每个节点收到后,用(2f+1, N)门限签名签署预备消息发给出块节点;之后,出块节点聚合成完整签名之后广播,每个节点收到之后,用(2f+1, N)门限签名签署预确认消息之后再广播;最后,出块节点聚合成完整签名之后广播,每个节点收到之后,用(2f+1, N)门限签名签署确认消息之后再广播,出块节点收到之后聚合再广播,每个节点验证签名之后进行确认。
同样的,当需要节点轮换的时候,每个节点也用(2f+1, N)门限签名签署一个节点轮换请求,然后新的出块节点聚合这些请求并且包含在新的区块之中。
链式Hotstuff
到这里,我们发现了一个非常有意思的特点,就是每轮的消息,甚至包括出块节点轮换,实际上都具有一样的格式——只是一个门限签名。那么,我们何不利用区块链的性质把这些结合起来——
我们规定每个合法的区块需要具有一个对于区块的(2f+1, N)门限签名,而同时,每个区块都是连在前面的链上的。于是,每个发表的区块中的门限签名,实际上就可以同时承担多重作用——它相当于本区块的预备消息,也相当于之前的区块的预确认消息,也相当于更前一个区块的确认消息。甚至,如果它是一个分叉,它还相当于一个合法的节点轮换请求。于是,平均到每个区块,达成共识只需要一轮通信,确切地说,其实额外的通信需求只是获取一个门限签名的通信需求,而不需要单独进行三轮通信。
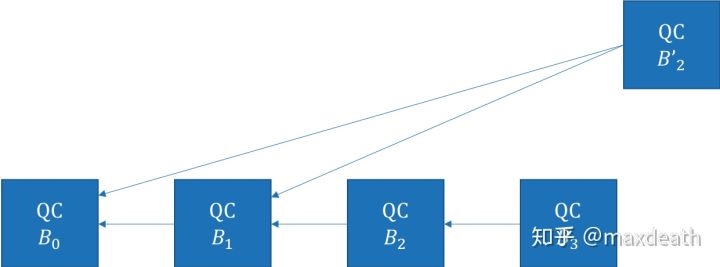 这里QC是一个(2f+1,N)的门限签名,而在链式结构中,一个QC可以有多重作用,例如,区块B3中的QC既是B3的预备消息,也是B2的预确认消息,也是B1的确认消息
这里QC是一个(2f+1,N)的门限签名,而在链式结构中,一个QC可以有多重作用,例如,区块B3中的QC既是B3的预备消息,也是B2的预确认消息,也是B1的确认消息
节点轮换规则
而且,另外一个有趣的特点是 —— 以上这个算法完全独立于节点轮换机制。于是,我们可以采用任何我们觉得合适的节点轮换机制来决定谁,以及什么时候来出下一个区块。
在同步系统里,我们可以规定每个时段的出块者,或者,我们可以固定时间,然后每轮都轮换出块者。
我们也可以像PBFT那样,用一个预先规定好的顺序,然后每次如果无法出块,就加长timeout,并更换出块者,从而达到弱同步(部分同步)条件下的BFT。
甚至,我们在区块链中,为了防止对于固定顺序出块节点的DDOS攻击,我们还可以采用基于可验证随机数(VRF)的方法来决定下一个出块者,Libra就采用了这种方法。
Hotstuff的意义
Hotstuff BFT采用一种非常精妙的方法,用门限签名和链式结构,把节点轮换,区块链出块,以及拜占庭共识本身给揉在了一起,使得无论是出块,拜占庭共识,还是区块轮换都有了一个非常简洁,并且完全一致的形式。其实其中,门限签名并不算是新东西,采用门限签名降低消息复杂度来扩展BFT也不是。所以,从BFT的角度上,也许最有趣的地方,在于三阶段共识——而实际上也只是用牺牲延迟的代价(因为多了一轮共识),来降低出块节点轮换的通信复杂度。
然而,它对于区块链共识算法的意义则要大得多 —— 首先,Hotstuff的形式非常接近于中本聪共识,所以为未来两者的比较和融合铺平了道路。于此同时,它也让节点轮换和拜占庭共识的消息复杂度都变成了O(N),这一点,使得它在输出上也达到了之前其他可扩展的BFT算法的级别(也可以说是最优的情况)。相对于其他算法,Hotstuff唯一做的妥协——延迟,在区块链中,由于大家从一开始就习惯了中本聪共识长达6个区块的确认,又算不上什么特别大的牺牲。并且,也许是最为重要的一点 —— Hotstuff的结构十分简单而且易于没有分布式系统基础的人理解和实现,这于之前的BFT算法大相径庭。这为它被应用于未来的区块链项目中打开了方便之门。
实际上,在原本的计划中,这一部分我们会讲到Honeybadger,讲到Byzcoin,讲到Hybrid Consensus,讲到Hyperledger Fabric,讲到Algorand的BA*。
但是,因为有了Hotstuff,我觉得我可以在这个系列中省略掉关于他们的介绍了。
并不是因为他们不重要,或者没有值得学习的地方。而是因为在我看来,Hotstuff提出的将BFT应用于区块链的方法如此优雅,以至于传统的,基于类似PBFT范式的共识算法很可能会被未来的区块链共识算法所抛弃。而以上所列举的这些算法中——
Byzcoin和Hybrid Consensus中的BFT仍旧采用PBFT的范式,因此仍旧有节点轮换高复杂度的问题。同时,Byzcoin和Hybrid Consensus的最佳情况消息复杂度分别是O(NlogN)和O(N^2),也不如Hotstuff。
Honeybadger BFT并没有采用节点轮换的方式,而是另一种拜占庭容错的方法,而这种方法不太符合人们对于区块链的想法。而同时,Honeybadger BFT对网络做的极度严格的异步假设,在我看来也并不符合大多数区块链的应用的场景。
在这里写Hyperledger-fabric在很多人看来很莫名其妙,因为现在人人都知道Hyperledger-fabric不是BFT的,有的可能还知道HF用的是Kafka,而且可以升级为BFT,因为它的共识算法是可插拔的。但是,这些都只对了一半。HF的确不是BFT算法,但是,它不是BFT算法的原因并不是在可插拔的部分用了Kafka,换句话说,就算把Kafka换成PBFT也不会让HF变成BFT的。HF应用的场景和我们在这里考虑的是完全针对于某种现实场景的,于是,尽管不是BFT的,但是,它仍旧用的是BFT算法的范式,只不过去掉了许多BFT中会出现但是在HF中不会出现的场景,然后巧妙地去掉了冗余。
Algorand中的BA*并不是一个BFT算法,而只是拜占庭共识(BA)的一种优化版。在Algorand之中,采用的是VRF+同步假设的出块节点轮换机制。尽管没有了PBFT的高通信复杂度,但是相比于Hotstuff,不仅在表现上不如,而且实现上也远没有那么简洁优雅。
Avalanche来自于和Hotstuff相同的作者,采用了“随机抽样BFT”和DAG代替链式结构来降低在大网络中的通信复杂度。然而,一方面是我对于DAG仍旧有非常大的疑问(我觉得在目前的大部分网络中,DAG的劣势多于优势,这点见前文);另一方面,至少从通信复杂度看,Avalanche并不比Hotstuff有明显的优势,这也就是说两者的输出并不会有量级的差别。而Hotstuff的简洁性和易理解性远胜Avalanche。
而与此同时,Hotstuff的输出和延时基本都优于这些算法(因为机制的简洁),至少,并不会和这些算法有显著的差距。
而与之相对的,试图实现finality的中本聪共识算法,例如以太坊,Polkadots,反而可以非常顺理成章地采用Hotstuff中的三阶段共识来解释和证明——这点得益于Hotstuff本身非常接近中本聪共识的结构,所以,我认为它是一座沟通两个世界的桥梁。
因此,我一方面非常欣赏Hotstuff这个算法本身,另一方面,也认为这个算法将会非常重要——因为它十分简洁地统一了区块链和BFT,同时达到了近乎最优的性能,以至于我想不到任何一个可以使用BFT的区块链场景,我们应该采用其他类型的BFT,例如PBFT,Honeybadger BFT,或者链式BFT,而不是Hotstuff。因此,我认为在这篇“区块链中的BFT”中详细地解释了它是非常合适的,同时,也可能是非常足够的——
因为它可能会是未来所有采用BFT的区块链的基础形态。
关于所有可扩展类的共识算法我们就介绍到这里 —— 因此,到此为止,算上上个系列,我们已经从两个角度介绍了共识算法从不可扩展到可扩展的进化过程:
1,从POW的角度,问题的症结是POW的过程依赖交易同步,所以我们应该将POW与交易同步并行。于是我们有了“先共识后同步”的基于领袖选择的共识算法,也有了“先同步后共识”的DAG算法。而同时,多数POS算法也属于第一类。
2,从BFT的角度,问题的症结是O(N^2)的消息复杂度,于是我们有了投机BFT来理想状况下降低消息复杂度到O(N)。然而,这些算法在出块节点轮换上的消息复杂度仍旧很高,使得他们仍旧很难被应用于大网络,于是,我们有了Hotstuff,将共识和节点轮换的消息复杂度都降到了O(N)。
而到此刻,从输出的角度讲,我们达到了区块链的瓶颈 —— 如果我们想要做到去中心化,那么所有的节点都需要验证每一笔交易,那么O(N)消息复杂度就是一个明摆着的下限。想要突破这个限制,我们就需要采用某些方法,让某些节点不需要接收某些交易,或者说,某些交易不需要广播给整个网络。于是,我们可以把消息复杂度降到o(N),于是系统的输出可以随着网络增大而增大,这就是所谓的无限扩展。
于是,在这里,就有了所谓“第一层”和“第二层”之争(第一层第二层之争是个筐,什么都能往里装,详细的关于第一层,第二层,以及无线扩展概念的介绍请见系列第一篇)——
前者认为应该采用链上扩展的方式,即分片。
后者认为应该采用链下扩展的方式,即链下技术或者侧链。
后面,我会介绍这两种技术中的一些关键算法。



