Vitalik:5 种不同类型的 ZK-EVM
- Unitimes
- 发布于 2022-08-09 17:19
- 阅读 3111
这篇文章将试图描述 EVM 等效的不同“类型”的分类法,以及尝试实现每种类型系统的好处与代价。
 撰文:Vitalik Buterin,以太坊联合创始人
撰文:Vitalik Buterin,以太坊联合创始人
编辑:DeFi之道
特别感谢 PSE、Polygon Hermez、Zksync、Scroll、Matter Labs 以及 Starkware 团队的讨论和审查。
最近有很多“ZK-EVM”项目发布了华丽的公告,比如 Polygon 开源了他们的 ZK-EVM 项目,ZKSync 发布了他们的 ZKSync 2.0 计划,而相对较新的 Scroll 在最近也宣布了他们的 ZK-EVM。隐私和扩容探索团队(Privacy and Scaling Explorations)、Nicolas Liochon 等人的团队、从 EVM 到 Starkware 的 Cairo 语言的 alpha 编译器也在不断努力,当然,还有一些是我错过的。
所有这些项目的核心目标都是相同的:使用 ZK-SNARK 技术来制作类似以太坊交易执行的密码学证明,或者更容易验证以太坊区块链本身,或者构建与以太坊提供的功能相当(接近)但可扩展性更强的 ZK-Rollup。但这些项目之间存在细微的差异,以及它们在实用性和速度之间做出了权衡。这篇文章将试图描述 EVM 等效的不同“类型”的分类法,以及尝试实现每种类型系统的好处与代价。
ZK-EVM 概览图
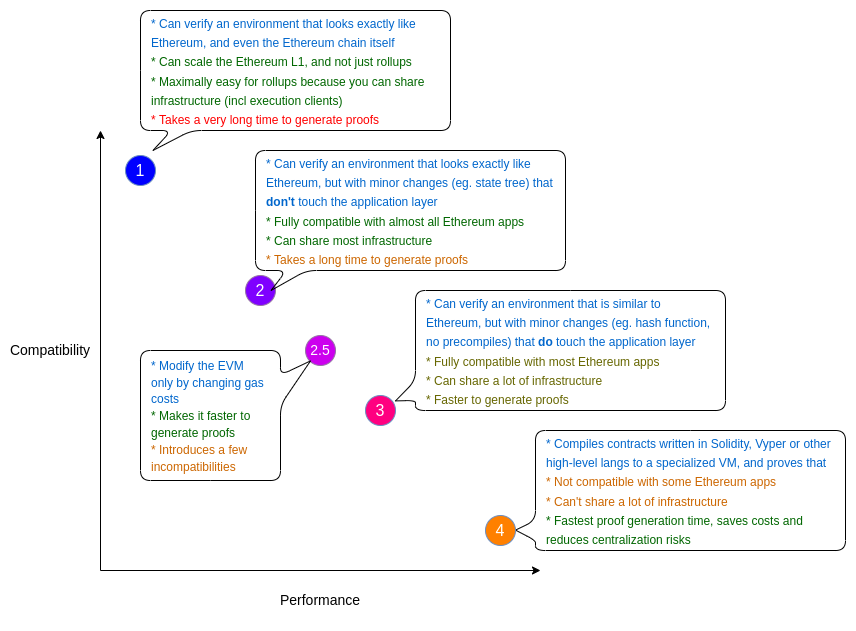
类型 1:完全等效于以太坊
类型 1 的 ZK-EVM 力求完全且毫不妥协地与以太坊等效,它们不会改变以太坊系统的任何部分来更容易生成证明。它们不会取代哈希、状态树、tx 树、预编译或任何其他共识逻辑,无论这些逻辑多么次要。
优点:完美兼容
目标是能够像今天一样验证以太坊区块,或者至少验证执行层端(因此,不包括信标链共识逻辑,但包括所有交易执行和智能合约和账户逻辑)。
类型 1 的 ZK-EVM 是我们最终需要的,它使以太坊 L1 层本身更具可扩展性。从长远来看,在类型 2 或类型 3 ZK-EVM 中测试过的以太坊修改可能会引入到以太坊本身,但这种重新架构也有其自身的复杂性。
类型 1 的 ZK-EVM 也是 Rollup 的理想选择,因为它们允许 Rollup 重用大量基础设施。例如,以太坊执行客户端可以按原样使用来生成和处理 Rollup 区块(或者至少,一旦实现提款,它们就可以使用,并且可以重新使用该功能来支持将 ETH 存入 Rollup 中),因此例如区块浏览器、区块生产等工具都是非常容易重新使用的。
缺点:证明者(prover)时间
以太坊最初并不是围绕 ZK 友好性设计的,因此以太坊协议的许多部分需要大量计算才能进行 ZK 证明。类型 1 的 ZK-EVM 旨在精确复制以太坊,因此它无法缓解这些低效率问题。目前,以太坊区块的证明需要很多小时才能够产生。这可以通过巧妙的工程大规模并行化证明者(prover)来缓解,长期也可以通过 ZK-SNARK ASIC 来缓解。
那谁在构建 类型 1 的 ZK-EVM 呢?
隐私和扩容探索团队(The Privacy and Scaling Explorations team)正在构建一个类型 1 的 ZK-EVM。(译者注:The Privacy and Scaling Explorations 团队即更名后的 appliedzkp)
类型 2:完全等效于 EVM
类型 2 的 ZK-EVM 力求完全等效于 EVM,但不完全等效于以太坊。也就是说,它们“从内部”看起来与以太坊完全一样,但它们在外部存在一些差异,特别是在区块结构和状态树等数据结构方面。
目标是与现有应用完全兼容,但对以太坊进行一些小的修改,以使开发更容易并更快地生成证明。
优点:VM 级别的完美等效
类型 2 的 ZK-EVM 对保存诸如以太坊状态之类的数据结构进行更改,幸运的是,这些结构是 EVM 本身无法直接访问的,因此在以太坊上工作的应用,几乎总是能在类型 2 的 ZK-EVM Rollup 上运行。你将无法按原样使用以太坊执行客户端,但你可以通过一些修改来使用它们,并且你仍然可以使用 EVM 调试工具和大多数其他开发者基础设施。
当然,也有少数例外的情况。对于验证以太坊历史区块的 Merkle 证明以验证历史交易、收据或状态声明的应用,会出现一种不兼容的情况(例如,桥有时会这样做)。用不同的哈希函数替换 Keccak 的 ZK-EVM 会破坏这些证明。但是,我通常建议不要以这种方式构建应用,因为未来的以太坊更改(例如 Verkle 树)甚至会破坏以太坊本身的此类应用。更好的选择是让以太坊本身添加经得起未来考验的历史访问预编译。
缺点:尽管改进了,但证明者(prover)时间依然很慢
类型 2 的 ZK-EVM 提供比类型 1 的 ZK-EVM 更快的证明者时间,主要是通过删除以太坊堆栈中依赖不必要的复杂和对 ZK 不友好的密码学部分。特别是,它们可能会改变以太坊对 Keccak 和基于 RLP 的 Merkle-Patricia 树,可能还会改变区块和收据结构。类型 2 对 ZK-EVM 可能会使用不同的哈希函数,比如 Poseidon。另一个自然修改是修改状态树以存储代码哈希和 keccak,从而无需验证哈希来处理 EXTCODEHASH 和 EXTCODECOPY 操作码。
这些修改显著改善了证明者(prover)时间,但并不能解决所有问题。由于 EVM 固有的所有低效率和 ZK 不友好性,证明 EVM 的速度仍然很缓慢。一个简单的例子是内存:因为一个 MLOAD 可以读取任意 32 个字节,包括“未对齐”chunk 块(开始和结束不是 32 的倍数),所以不能简单地将一个 MLOAD 解释为读取一个块;相反,它可能需要读取两个连续的块并执行位操作来组合结果。
那谁在构建 类型 2 的 ZK-EVM 呢?
Scroll 的 ZK-EVM 项目正朝着类型 2 的 ZK-EVM 方向发展,Polygon Hermez 也是如此。当然,这两个项目都还没有完成。特别是,很多更复杂的预编译还没有实现。因此,目前这两个项目被归类到 类型 3 的 ZK-EVM 会更好一些。
类型 2.5:等效于 EVM,但 gas 成本除外
显着改善最坏情况证明者时间的一种方法,是大大增加 EVM 中很难进行 ZK 证明的特定操作的 gas 成本。这可能涉及到预编译、KECCAK 操作码,以及调用合约或访问内存或存储或恢复的可能特定模式。
更改 gas 成本可能会降低开发人员工具的兼容性,并破坏一些应用,但通常我们认为它比“更深入”的 EVM 更改风险更低。开发人员应该注意不要在一笔交易中要求超过一个区块的 gas,永远不要使用硬编码的 gas 量进行调用(这已经是长期以来的一种标准建议)。
管理资源约束的另一种方法,是简单地对每个操作可调用的次数设置硬限制。这在电路中更容易实现,但在 EVM 安全假设下的表现要差得多。我将这种方法称为 类型 3 而不是 类型 2.5。
类型 3:几乎等效于 EVM
类型 3 的 ZK-EVM 几乎等效于 EVM,但为了进一步改进证明者(prover)时间并使 EVM 更易于开发,需要在精确等效性上做出一些牺牲。
优点:易于构建,证明者(prover)时间更快
类型 3 的 ZK-EVM 可能会删除一些在 ZK-EVM 实施中非常难以实现的特性,而预编译通常位于该列表的顶部,此外,类型 3 的 ZK-EVM 有时在处理合约代码、内存或堆栈方面也存在细微差别。
缺点:不兼容的地方会相对多一些
类型 3 ZK-EVM 的目标是与大多数应用兼容,而其余部分只需要最少的重写工作。也就是说,有些应用需要重写,因为它们使用了类型 3 ZK-EVM 删除的预编译,或者因为对 VM 不同处理的边缘情况的微妙依赖。
那谁在构建类型 3 的 ZK-EVM?
Scroll 和 Polygon 在当前构建的 ZK-EVM 都是属于类型 3,尽管它们有望随着时间的推移提高兼容性。Polygon 有一个独特的设计,他们对自己的内部语言 zkASM 进行 ZK 验证,并使用 zkASM 实现来解释 ZK-EVM 代码。尽管有这个实现细节,但我仍将其称为真正的类型 3 ZK-EVM,它仍然可以验证 EVM 代码,它只是使用了一些不同的内部逻辑来完成它。
今天,没有 ZK-EVM 团队的目标是成为类型 3 的 ZK-EVM,类型 3 只是一个过渡阶段,直到添加预编译的复杂工作完成,然后项目就可以转移到类型 2.5 的 ZK-EVM。然而,在未来,类型 1 或类型 2 的 ZK-EVM 可能会自动成为类型 3 的 ZK-EVM,方法是添加新的 ZK-SNARK 友好的预编译,为开发人员提供低证明者(prover)时间和 gas 成本的功能。
类型 4:高级语言等效
类型 4 系统的工作原理,是将用高级语言编写的智能合约源代码(例如 Solidity、Vyper 或中间语言)编译为某种明确设计为 ZK-SNARK 友好的语言。
优点:非常快的证明者(prover)时间
通过不对每个 EVM 执行步骤的所有不同部分进行 ZK 证明,并直接从更高 level 的代码开始,你可以避免大量开销。
我在这篇文章中仅用一句话来描述类型 4 系统的这一优势(与下面列出的与兼容性相关的缺点相比),但这不应该被解释为一种价值判断!直接从高级语言编译,确实可以大大降低成本,并通过更容易成为证明者(prover)来帮助实现去中心化。
缺点:兼容性会更糟
用 Vyper 或 Solidity 编写的“普通”应用可通过编译“正常工作”,但有一些重要的方式使得很多应用无法“正常工作”。
合约在类型 4 系统中的地址可能与 EVM 中的地址不同,因为 CREATE2 合约地址取决于确切的字节码。这破坏了依赖尚未部署的“反事实合约”、ERC-4337 钱包、EIP-2470 单件和很多其他应用程序的应用。 手写的 EVM 字节码更难使用,很多应用在某些部分会使用手写 EVM 字节码以提高效率。而类型 4 的系统可能不支持它,尽管有一些方法可以实现有限的 EVM 字节码支持来满足这些用例,而无需努力成为一个完整的类型 3 ZK-EVM。 很多调试基础设施无法兼容,因为这样的基础设施运行在 EVM 字节码上。也就是说,通过从“传统”高级或中间语言(例如 LLVM)更多地访问调试基础设施,可以缓解这一缺点。
开发人员应该注意这些问题。
那谁在构建类型 4 的系统?
ZKSync 就是一个类型 4 系统,尽管随着时间的推移,它可能会增加对 EVM 字节码的兼容性。Nethermind 的 Warp 项目正在构建一个从 Solidity 到 Starkware 的 Cairo 语言的编译器,这将使 StarkNet 变成事实上的类型 4 系统。
ZK-EVM 类型的未来
本文并没有明确判断以上各种类型的 ZK-EVM 哪个“更好”或“更差”,相反,它们只是在不同的点上进行了权衡:编号较低的类型与现有基础设施更兼容,但速度会较慢,而编号较高的类型与已有基础设施不太兼容,但它们会更快。 总的来说,所有类型 ZK-EVM 的探索都是有益的。
此外,ZK-EVM 项目可以很容易地从编号较高的类型开始,并随着时间推移跳转到编号较低的类型(反之亦然)。 例如:
- 一个 ZK-EVM 可以从类型 3 开始,它决定不包含一些特别难以 ZK 证明的功能。之后,他们可以随着时间的推移添加这些功能,并转向类型 2 的 ZK-EVM。
- ZK-EVM 也可以从类型 2 开始,然后成为混合类型 2/类型 1 的 ZK-EVM,通过提供在完全以太坊兼容模式下运行的可能性,或者提供可以更快证明的修改状态树,比如 Scroll 正在考虑朝这个方向发展。
- 通过添加处理 EVM 代码的能力,从类型 4 开始的系统,可能会随着时间的推移变成类型 3(尽管仍然鼓励开发人员直接从高级语言编译以减少费用和证明者时间)。
- 如果以太坊本身采用修改以变得对 ZK 更加友好,则类型 2 或类型 3 的 ZK-EVM 可以成为类型 1 的 ZK-EVM。
- 类型 1 或类型 2 的 ZK-EVM 可以通过添加预编译来验证 ZK-SNARK 友好语言中的代码,从而成为类型 3 的 ZK-EVM。这将使开发人员在以太坊兼容性和速度之间做出选择,而类型 3 就是这样的选择,因为它打破了完美的 EVM 等效性,但出于实际目的,它将具有类型 1 和类型 2 ZK-EVM 的很多好处。主要的缺点可能是某些开发人员工具无法理解 ZK-EVM 的自定义预编译,尽管这可以修复:开发者工具可通过支持包含预编译的 EVM 代码等效实现的配置格式来添加通用预编译支持。
就我个人而言,我希望随着时间的推移,通过 ZK-EVM 的改进以及以太坊本身的改进(使其对 ZK-SNARK 更友好),让一切都变成类型 1 的 ZK-EVM。在这样的未来,我们将有多个 ZK-EVM 实现,它们既可以用于 ZK Rollup,也可以用于验证以太坊区块链本身。从理论上讲,以太坊不需要为 L1 使用在单个 ZK-EVM 实现上进行标准化。不同的客户端可以使用不同的证明,因此我们继续受益于代码冗余。
然而,要实现这样的一个未来,还需要相当长的时间。与此同时,我们将在扩展以太坊和基于以太坊的 ZK-Rollup 的不同路径上看到很多创新。
本文仅代表原作者观点,不构成任何投资意见或建议。





