以太坊数据流分析技术
- 九暑
- 发布于 2022-12-27 02:05
- 阅读 7503
通过Slither工具理解以太坊数据流分析技术
以太坊数据流分析技术
一、前置知识
1. python第三方解析智能合约库:crytic-compile
crytic-compile是一个python智能合约审计框架下常用的第三方库,应用于slither、oyente等工具,其主要逻辑为通过solc生成合约的abi、bin、AST等信息,并进行一次封装,生成完整的json文件,同时支持多文件同时解析。
如一个简单的合约:
pragma solidity ^0.5.0;
contract SimpleStorage {
uint public storedData;
function set(uint x) public {
storedData = x;
}
function get() public view returns (uint) {
return storedData;
}
}调用crytic-compile生成结果json:
from crytic_compile import CryticCompile
from crytic_compile.platform.standard import generate_standard_export
if __name__ == '__main__':
compilation = CryticCompile("tests/test.sol")
print(generate_standard_export(compilation))结果如下:
{
'compilation_units': {
'test.sol': {
'compiler': {
'compiler': 'solc',
'version': '0.5.6',
'optimized': False
},
'asts': {
'D:\\PycharmProject\\ast_test\\test.sol': {
'absolutePath': 'test.sol',
'exportedSymbols': {
'SimpleStorage': [22]
},
'id': 23,
'nodeType': 'SourceUnit',
'nodes': [{
'id': 1,
'literals': ['solidity', '^', '0.5', '.0'],
'nodeType': 'PragmaDirective',
'src': '0:23:0'
},...],
'src': '0:238:0'
}
},
'contracts': {
'test.sol': {
'SimpleStorage': {
'abi': [{
'constant': True,
'inputs': [],
'name': 'storedData',
'outputs': [{
'name': '',
'type': 'uint256'
}
],
'payable': False,
'stateMutability': 'view',
'type': 'function'
}...
],
'bin': '6080......0029',
'filenames': {
'absolute': 'D:\\PycharmProject\\ast_test\\test.sol',
'used': 'test.sol',
'short': 'test.sol',
'relative': 'test.sol'
},
'libraries': {},
'is_dependency': False,
'userdoc': {
'methods': {},
'notice': None
},
'devdoc': {
'methods': {},
'author': None,
'details': None,
'title': None
}
}
}
},
'filenames': [{
'absolute': 'D:\\PycharmProject\\ast_test\\test.sol',
'used': 'test.sol',
'short': 'test.sol',
'relative': 'test.sol'
}
]
}
},
'package': None,
'working_dir': 'D:\\PycharmProject\\ast_test',
'type': 1,
'unit_tests': [],
'crytic_version': '0.0.1'
}
由于篇幅限制,删除了部分信息,概括其中主体信息如下:
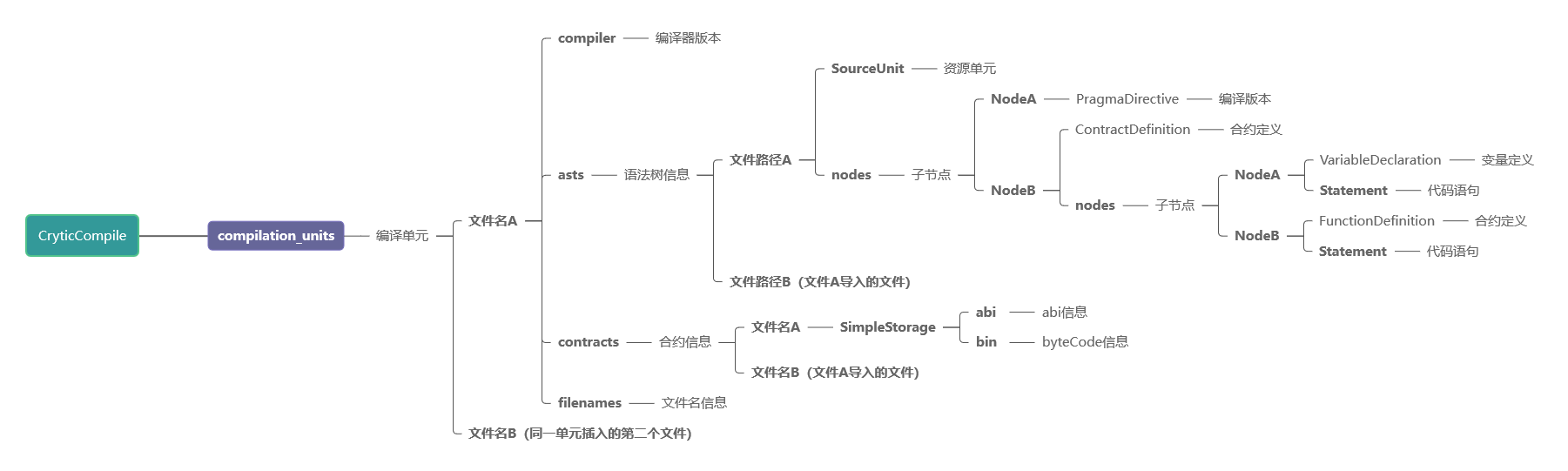
2. 智能合约AST中常见的NodeType
智能合约的 AST(抽象语法树)是一种表示智能合约代码结构的数据结构。它通常由一些节点组成,每个节点都代表代码中的一个语法单元。
一些常见的 AST 节点类型包括:
- Program: 表示整个源代码文件。
- BlockStatement: 表示代码块,也就是由花括号括起来的代码。
- ExpressionStatement: 表示表达式,即在语句中进行计算或操作的代码。
- Variable Declaration: 表示变量声明,即在代码中定义新变量的语句。
- Function Declaration: 表示函数声明,即在代码中定义新函数的语句。
- If Statement: 表示 if 语句,即根据某个条件来执行不同的代码块的语句。
- For Loop: 表示 for 循环,即在代码中循环执行某段代码的语句。
- Return Statement: 表示 return 语句,即从函数中返回结果的语句。
- UserDefinedValueTypeDefinition:指在智能合约AST中定义的自定义值类型。
例如,在某个智能合约中,我们可以定义一个自定义值类型Account,表示账户信息:
struct Account {
uint256 balance;
string name;
}在AST中,这个自定义值类型的定义可能是这样的:
{
"type": "UserDefinedValueTypeDefinition",
"name": "Account",
"fields": [
{
"name": "balance",
"type": "uint256"
},
{
"name": "name",
"type": "string"
}
]
}由于crytic-compile直接提供语法树,我们在数据流分析中可以基于其直接生成控制流,主要关注ForStatement、IfStatement等非顺序执行节点即可。
3. 支配树算法
在构造数据流时,我们需要知道每个变量的赋值受那些节点支配,即确定SOURCE与SINK之间是否有完整的支配关系,因此在生成控制流后应首先计算函数的支配树。
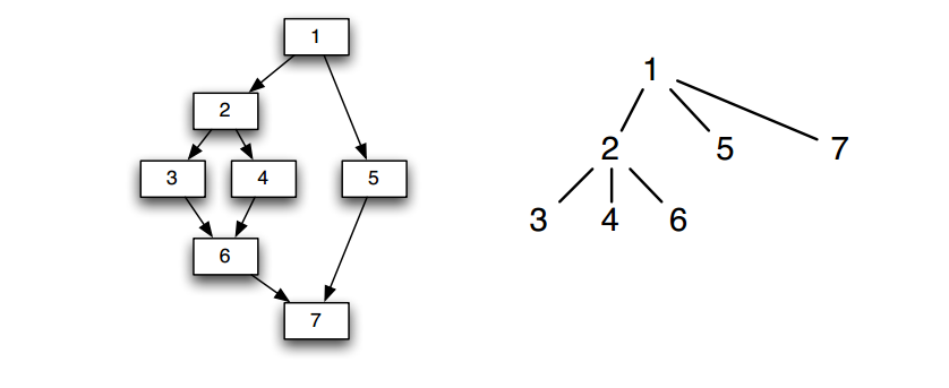
支配树
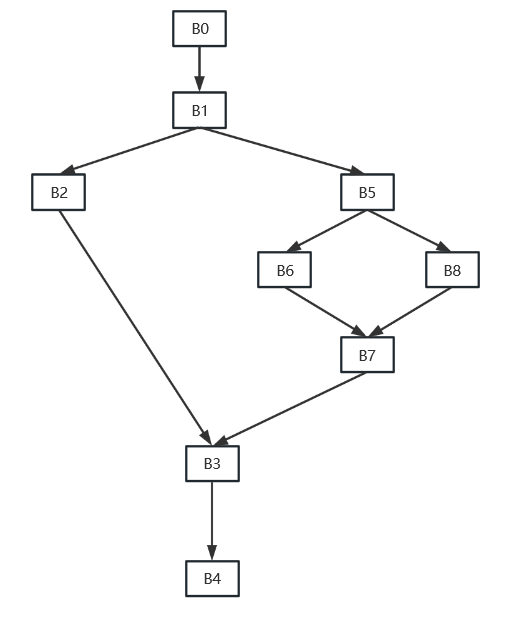
支配树(dominator tree)用来表示支配信息,在树中,入口节点,并且每个节点只支配它在树中的后代节点。一种支配树的示例如下:
直接支配节点
在支配树中,对于节点 n 来说,从根节点到节点 n 所在路径上的节点(不包括 n )都严格支配节点 n ,例如上图中从根节点 1 → 2 → 3 ,其中节点 1 和节点 2 都严格支配节点 3 。该路径上离节点 n 最近的节点叫做节点 n 的直接支配节点(immediate node),用 IDom(n) 表示,例如上图中 IDom(6) = 2。
支配边界
在构造 SSA 过程中,还有另外一个概念很重要,就是支配边界(dominance frontier)。支配边界直观理解就是当前节点所能支配的边界(并不包括该边界),另一种等价描述“Y 是 X 的支配边界,当且仅当 X 支配 Y 的一个前驱节点(CFG)同时 X 并不严格支配 Y”。
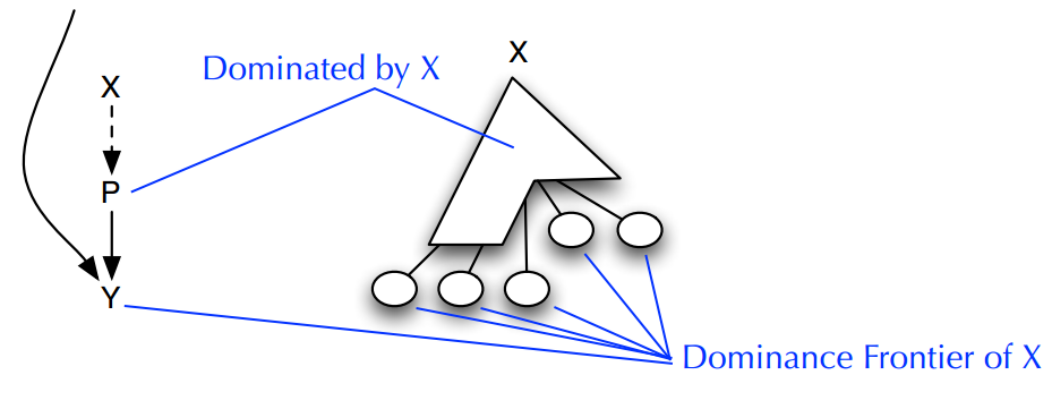
上面的图示直观的表示了支配边界的概念。下面的图给出了一个示例,给出了图中的支配结点以及支配边界关系。
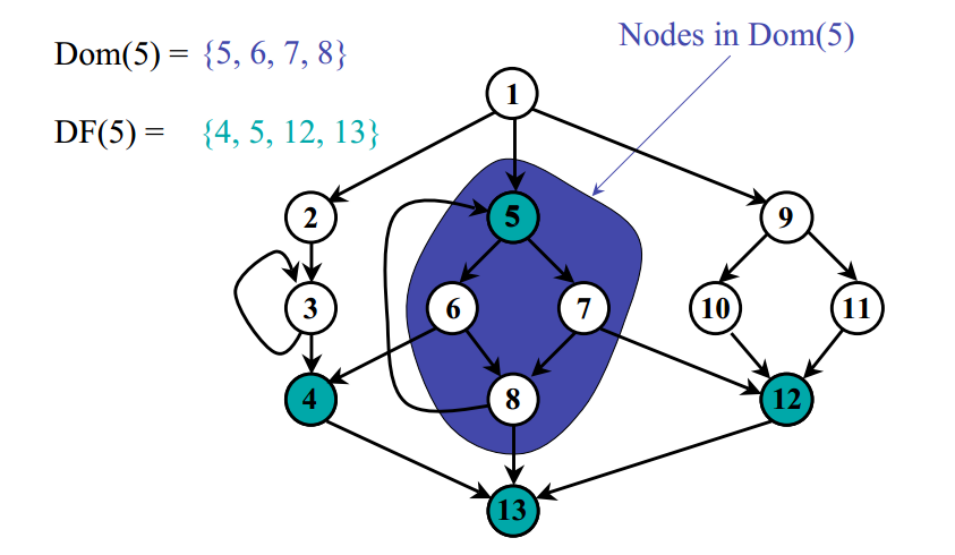
上图中节点 5 支配边界是 4、5、12、13,也就是节点 5 “刚好能力所不能及的地方”。
支配边界的意义在于计算SSA时确定 Φ函数 插入位置,具体见SSA小节
Dominator-tree Algorithm
计算支配树
我们主要采用Dominator-tree Algorithm算法来计算支配树,该算法迭代过程如下:

其每次遍历控制流时,计算本节点与所有父节点的支配节点的交集,如最终所有节点的支配节点不发生变化,则完成支配树计算。算法伪代码如下:

笔者用python简单实现一种计算方法用以验证:
from typing import List
import json
nodeDict = {}
node_json = """
{
"0":["1", ""],
"1":["2,5", "0"],
"2":["3", "1"],
"5":["6,8","1"],
"6":["7", "5"],
"8":["7","5"],
"7":["3","6,8"],
"3":["4", "2,7"],
"4":["", "3"]
}
"""
class Node:
def __init__(self, name, data):
self.name: str = name
self.data = data
self.fathers: List[Node] = []
self.children: List[Node] = []
self.dominators = set()
def set_children_fathers(self):
self.set_children(self.data[0].split(","))
self.set_fathers(self.data[1].split(","))
def set_children(self, name_list):
for n in name_list:
if n:
self.children.append(nodeDict[n])
def set_fathers(self, name_list):
for n in name_list:
if n:
self.fathers.append(nodeDict[n])
def print_dominators(self):
print(f"{self.name}: {[d.name for d in self.dominators]}")
def __str__(self):
return f"{self.name}: {[c.name for c in self.children]}, {[f.name for f in self.fathers]}"
def intersect(node: Node):
if node.fathers:
d = node.fathers[0].dominators
for f in node.fathers[1:]:
d = d.intersection(f.dominators)
return d
else:
return set()
def compute_dominators(node_list: List[Node]):
Change = True
while Change:
Change = False
for n in node_list:
new_dominators = intersect(n).union({n})
if new_dominators != n.dominators:
n.dominators = new_dominators
Change = True
def test():
node_list_str = json.loads(node_json)
node_list = []
for k,v in node_list_str.items():
n = Node(k, v)
nodeDict[k] = n
node_list.append(n)
for n in node_list:
n.set_children_fathers()
for n in node_list:
print(n)
print()
compute_dominators(node_list)
for n in node_list:
n.print_dominators()
模拟控制流图如下:
生成结果:
0: ['0']
1: ['0', '1']
2: ['2', '0', '1']
5: ['0', '1', '5']
6: ['6', '0', '1', '5']
8: ['8', '0', '1', '5']
7: ['7', '0', '1', '5']
3: ['3', '0', '1']
4: ['3', '4', '0', '1']符合支配树计算结果
计算直接支配节点
将节点除自身外的的支配节点作为候选节点,遍历候选节点,每次将该节点的支配节点加入总节点列表中,最后找到在候选节点但不再总节点列表中即为直接支配节点,用python实现:
def compute_immediate_dominator(node_list: List[Node]):
for node in node_list:
idom_candidates = set(node.dominators)
idom_candidates.remove(node)
# 仅有一项那必为直接支配节点
if len(idom_candidates) == 1:
idom = idom_candidates.pop()
node.idom = idom
continue
all_dominators = set()
for d in idom_candidates:
if d in all_dominators:
continue
all_dominators |= d.dominators - {d}
idom_candidates = all_dominators.symmetric_difference(idom_candidates)
assert len(idom_candidates) <= 1
if idom_candidates:
idom = idom_candidates.pop()
node.idom = idom最终结果:
0:
1: 0
2: 1
5: 1
6: 5
8: 5
7: 5
3: 1
4: 3与直接支配者计算结果一致
计算支配边界
遍历每个节点的父节点,如该父节点不是子节点的直接支配节点,则子节点作为父节点支配边界的一部分,pyhton实现:
def compute_dominator_frontier(node_list: List[Node]):
for node in node_list:
if len(node.fathers) >= 2:
for father in node.fathers:
if father != node.idom:
father.dominator_frontier = father.dominator_frontier.union({node})最终结果:
0: []
1: []
2: ['3']
5: []
6: ['7']
8: ['7']
7: ['3']
3: []
4: []与支配边界计算结果一致
4. 数据流分析
在进行污点追踪时,我们希望能找到某个SINK的直接数据流来源,譬如:
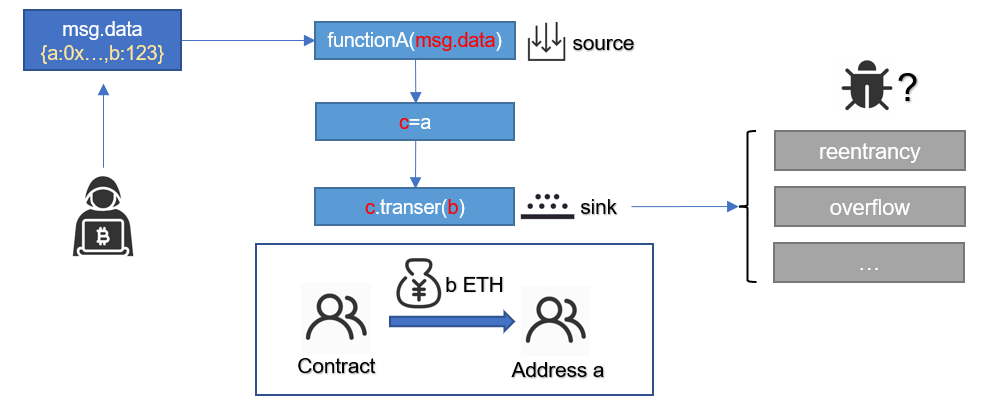
只有当transfer中的参数用户直接可控,这条污点链才是有意义的,因此我们在静态分析中最终目的是进行数据流分析,即分析数据是如何在程序执行路径上流动的。
数据流分析的通用方法是在控制流图上定义一组方程并迭代求解,一般分为正向传播和逆向传播。正向传播就是沿着控制流路径,状态向前传递,前驱块的值传到后继块;逆向传播就是逆着控制流路径,后继块的值反向传给前驱块。
5. 静态单赋值SSA
SSA 是 static single assignment 的缩写,也就是静态单赋值形式。顾名思义,就是每个变量只有唯一的赋值。SSA范式可以用来简化各种基于数据流的分析。SSA范式之前,数据流分析的某个变量的定义是一个集合,SSA范式转换之后这些变量都变成了唯一定义;而且由于每个变量只有一次定义,相当于说每个变量都可以转换成常量(循环内定义的变量除外,每次循环迭代,变量都会被重新定义)。
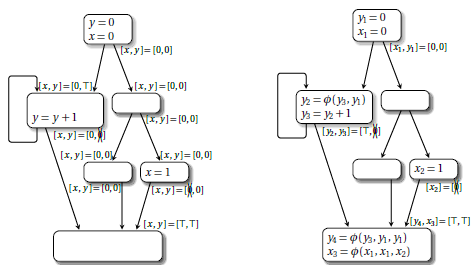
以下图为例,左图是原始代码,里面有分支, y 变量在不同路径中有不同赋值,最后打印 y 的值。右图是等价的 SSA 形式,y 变量在两个分支中被改写为 y1, y2,在控制流交汇处插入 Ф 函数,合并了来自不同边的 y1, y2 值, 赋给 y3, 最后打印的是 y3。
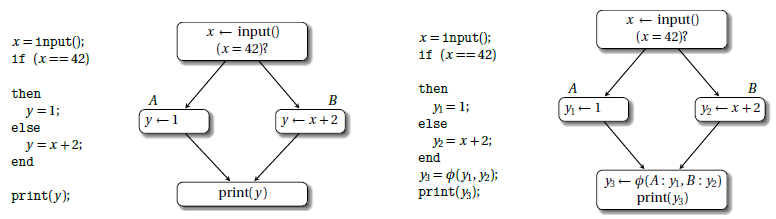
总结 SSA 形式的两个特征就是:
- 旧变量按照活动范围(从变量的一次定义到使用)分割,被重新命名为添加数字编号后缀的新变量,每个变量只定义一次。
- 控制流交汇处有 Ф 函数将来自不同路径的值合并。 Ф 函数表示一个 parallel 操作,根据运行的路径选择一个赋值。如果有多个 Ф 函数,它们是并发执行的。
这里引入两个名词 use-def chain 和 def-use chain。use-def chain 是一个数据结构,包含一个 def 变量,以及它的全部 use 的集合。相对的,def-use chain 包含一个 use 变量,以及它的全部 def 的集合。以图2左图为例,虚线就是 x 每处定义的 def-use chain. 传统代码因为变量不止一次定义,所以每个定义的 def-use chain 非常复杂。再看右图,SSA 形式下没有同名变量,每个变量只定义一次,所以同名的 use 都是属于它的 def-use chain. 而且因为每个变量 use 前都只有一次 def, 所以 use-def chain 是一对一的。可见,SSA 形式下的 def-use chain 与 use-def chain 都得到了简化。
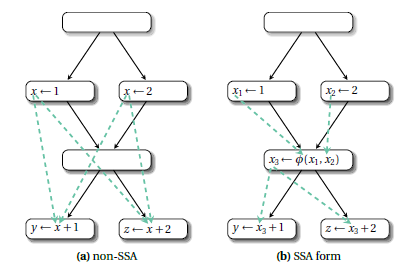
SSA 形式的优点不仅在于简化 def-use chain 与 use-def chain,它提供了一种稀疏表示的数据结构,极大方便了数据流分析。如图3 所示,左边是传统的基于方程组的数据流分析,右边是基于 SSA 形式的数据流分析。前文讲过传统数据流分析是在基本块上沿控制流路径或逆向迭代传播,SSA 形式的 def-use chain 与 use-def chain 直接给出了更多信息,数据流值传播不局限于控制流路径。可见 SSA 形式可以简化数据流分析。
二、Slither
Slither是一个由Python 3编写的智能合约静态审计框架。提供如下功能:
- 自动化漏洞检测。提供超30多项的漏洞检查模型
- 自动优化检测。Slither可以检测编译器遗漏的代码优化项并给出优化建议。
- 代码理解。Slither能够绘制合约的继承拓扑图,合约方法调用关系图等,帮助开发者理解代码。
- 辅助代码审查。用户可以通过API与Slither进行交互
工作流程如下:
- 抽象语法树(AST)的生成:使用 crytic-compile第三方库生成直接生成智能合约的AST作为输入
- 控制流的生成:经过遍历语法树节点,生成每个函数的控制流
- 数据流的生成:通过将控制流转换为IR,并分析其中表达式构造静态单赋值,生成所有参数的def-use链
- 漏洞检测:根据污点追踪等技术,采用不同模型判断漏洞是否存在并提供检测报告。
作为一个完整的静态分析模型,其代码架构有助于我们理解智能合约中的数据流分析流程,笔者总结了简化版流程图:https://www.processon.com/v/63a9a358ebd78059fa588a61,文字分析如下,顺序基于工作流程。
1. 抽象语法树的生成
本部分直接通过第三方包 crytic-compile 即可完成,在入口函数Slither()中:
87 try:
88 # 如果是文件名,先进行编译
89 if isinstance(target, CryticCompile):
90 crytic_compile = target
91 else:
92 crytic_compile = CryticCompile(target, **kwargs)
93 self._crytic_compile = crytic_compile判断提供的参数是否为CryticCompile,若不是,则先进行一次封装,封装结果见前置知识1
2. 控制流的生成
首先介绍该过程用到的部分封装类,主要在slither/core与slither/solc_parsing文件夹下,前者为节点类,后者为解析器类,解析器其实就是节点的一个封装,首先保存该节点的所有信息,再提供某些方法供计算与解析节点。
解析器类
SlitherCompilationUnit
为编译单元解析器,负责维护每个编译单元(compilation_unit)中解析的内容,保存语法树中的顶层信息与编译单元中的合约信息
def __init__(self, core: "SlitherCore", crytic_compilation_unit: CompilationUnit):
super().__init__()
self._core = core
self._crytic_compile_compilation_unit = crytic_compilation_unit
# Top level object
self.contracts: List[Contract] = []
self._structures_top_level: List[StructureTopLevel] = []
self._enums_top_level: List[EnumTopLevel] = []
self._variables_top_level: List[TopLevelVariable] = []
self._functions_top_level: List[FunctionTopLevel] = []
self._pragma_directives: List[Pragma] = []
self._import_directives: List[Import] = []
self._custom_errors: List[CustomError] = []
self._all_functions: Set[Function] = set()
self._all_modifiers: Set[Modifier] = set()
# Memoize
self._all_state_variables: Optional[Set[StateVariable]] = None
self._storage_layouts: Dict[str, Dict[str, Tuple[int, int]]] = {}
self._contract_with_missing_inheritance = set()
self._source_units: Dict[int, str] = {}
self.counter_slithir_tuple = 0
self.counter_slithir_temporary = 0
self.counter_slithir_reference = 0
self.scopes: Dict[Filename, FileScope] = {}ContractSolc
合约解析器,维护对应合约的完整解析内容与其中的所有函数、修饰器、结构体解释器,
def __init__(self, slither_parser: "SlitherCompilationUnitSolc", contract: Contract, data):
# assert slitherSolc.solc_version.startswith('0.4')
self._contract = contract
self._slither_parser = slither_parser
self._data = data
self._functionsNotParsed: List[Dict] = []
self._modifiersNotParsed: List[Dict] = []
self._functions_no_params: List[FunctionSolc] = []
self._modifiers_no_params: List[ModifierSolc] = []
self._eventsNotParsed: List[Dict] = []
self._variablesNotParsed: List[Dict] = []
self._enumsNotParsed: List[Dict] = []
self._structuresNotParsed: List[Dict] = []
self._usingForNotParsed: List[Dict] = []
self._customErrorParsed: List[Dict] = []
self._functions_parser: List[FunctionSolc] = []
self._modifiers_parser: List[ModifierSolc] = []
self._structures_parser: List[StructureContractSolc] = []
self._custom_errors_parser: List[CustomErrorSolc] = []
self._is_analyzed: bool = False
# use to remap inheritance id
self._remapping: Dict[str, str] = {}
self.baseContracts: List[str] = []
self.baseConstructorContractsCalled: List[str] = []
self._linearized_base_contracts: List[int]
self._variables_parser: List[StateVariableSolc] = []
# Export info
if self.is_compact_ast:
self._contract.name = self._data["name"]
else:
self._contract.name = self._data["attributes"][self.get_key()]
self._contract.id = self._data["id"]
# 解析合约
self._parse_contract_info()
self._parse_contract_items()FunctionSolc
函数解析器,维护对应的函数信息与其中的参数解释器
def __init__(
self,
function: Function,
function_data: Dict,
contract_parser: Optional["ContractSolc"],
slither_parser: "SlitherCompilationUnitSolc",
):
self._slither_parser: "SlitherCompilationUnitSolc" = slither_parser
self._contract_parser = contract_parser
self._function = function
# Only present if compact AST
if self.is_compact_ast:
self._function.name = function_data["name"]
if "id" in function_data:
self._function.id = function_data["id"]
else:
self._function.name = function_data["attributes"][self.get_key()]
self._functionNotParsed = function_data
self._params_was_analyzed = False
self._content_was_analyzed = False
self._counter_scope_local_variables = 0
self._variables_renamed: Dict[
int, Union[LocalVariableSolc, LocalVariableInitFromTupleSolc]
] = {}
self._analyze_type()
self._node_to_nodesolc: Dict[Node, NodeSolc] = {}
self._node_to_yulobject: Dict[Node, YulBlock] = {}
self._local_variables_parser: List[
Union[LocalVariableSolc, LocalVariableInitFromTupleSolc]
] = []NodeSolc
封装节点的解析信息
class NodeSolc:
def __init__(self, node: Node):
self._unparsed_expression: Optional[Dict] = None
self._node = node节点类
FileScope
对应文件的作用范围,保存AST对应的顶层节点
def __init__(self, filename: Filename):
self.filename = filename
self.accessible_scopes: List[FileScope] = []
self.contracts: Dict[str, Contract] = {}
# Custom error are a list instead of a dict
# Because we parse the function signature later on
# So we simplify the logic and have the scope fields all populated
self.custom_errors: Set[CustomErrorTopLevel] = set()
self.enums: Dict[str, EnumTopLevel] = {}
# Functions is a list instead of a dict
# Because we parse the function signature later on
# So we simplify the logic and have the scope fields all populated
self.functions: Set[FunctionTopLevel] = set()
self.imports: Set[Import] = set()
self.pragmas: Set[Pragma] = set()
self.structures: Dict[str, StructureTopLevel] = {}
self.variables: Dict[str, TopLevelVariable] = {}
# Renamed created by import
# import A as B
# local name -> original name (A -> B)
self.renaming: Dict[str, str] = {}
# User defined types
# Name -> type alias
self.user_defined_types: Dict[str, TypeAlias] = {}TopLevelVariable
维护顶层节点信息,负责后续进一步解析
def __init__(self, scope: "FileScope"):
super().__init__()
self._node_initialization: Optional["Node"] = None
self.file_scope = scopeContract
维护合约中的所有信息,如父合约_linearizedBaseContracts,函数_functions,变量_variables,修饰器_modifiers等,
def __init__(self, compilation_unit: "SlitherCompilationUnit", scope: "FileScope"):
super().__init__()
self._name: Optional[str] = None
self._id: Optional[int] = None
self._inheritance: List["Contract"] = [] # all contract inherited, c3 linearization
self._immediate_inheritance: List["Contract"] = [] # immediate inheritance
# Constructors called on contract's definition
# contract B is A(1) { ..
self._explicit_base_constructor_calls: List["Contract"] = []
self._enums: Dict[str, "EnumContract"] = {}
self._structures: Dict[str, "StructureContract"] = {}
self._events: Dict[str, "Event"] = {}
self._variables: Dict[str, "StateVariable"] = {}
self._variables_ordered: List["StateVariable"] = []
self._modifiers: Dict[str, "Modifier"] = {}
self._functions: Dict[str, "FunctionContract"] = {}
self._linearizedBaseContracts: List[int] = []
self._custom_errors: Dict[str, "CustomErrorContract"] = {}
# The only str is "*"
self._using_for: Dict[Union[str, Type], List[Type]] = {}
self._kind: Optional[str] = None
self._is_interface: bool = False
self._is_library: bool = False
self._signatures: Optional[List[str]] = None
self._signatures_declared: Optional[List[str]] = None
self._is_upgradeable: Optional[bool] = None
self._is_upgradeable_proxy: Optional[bool] = None
self.is_top_level = False # heavily used, so no @property
self._initial_state_variables: List["StateVariable"] = [] # ssa
self._is_incorrectly_parsed: bool = False
self._available_functions_as_dict: Optional[Dict[str, "Function"]] = None
self._all_functions_called: Optional[List["InternalCallType"]] = None
self.compilation_unit: "SlitherCompilationUnit" = compilation_unit
self.file_scope: "FileScope" = scope
# memoize
self._state_variables_used_in_reentrant_targets: Optional[
Dict["StateVariable", Set[Union["StateVariable", "Function"]]]
] = NoneFunction
维护函数的完整信息,包括其中节点、变量、参数等。
def __init__(self, compilation_unit: "SlitherCompilationUnit"):
super().__init__()
self._internal_scope: List[str] = []
self._name: Optional[str] = None
self._view: bool = False
self._pure: bool = False
self._payable: bool = False
self._visibility: Optional[str] = None
self._is_implemented: Optional[bool] = None
self._is_empty: Optional[bool] = None
self._entry_point: Optional["Node"] = None
self._nodes: List["Node"] = []
self._variables: Dict[str, "LocalVariable"] = {}
# slithir Temporary and references variables (but not SSA)
self._slithir_variables: Set["SlithIRVariable"] = set()
self._parameters: List["LocalVariable"] = []
self._parameters_ssa: List["LocalIRVariable"] = []
self._parameters_src: SourceMapping = SourceMapping()
self._returns: List["LocalVariable"] = []
self._returns_ssa: List["LocalIRVariable"] = []
self._returns_src: SourceMapping = SourceMapping()
self._return_values: Optional[List["SlithIRVariable"]] = None
self._return_values_ssa: Optional[List["SlithIRVariable"]] = None
self._vars_read: List["Variable"] = []
self._vars_written: List["Variable"] = []
self._state_vars_read: List["StateVariable"] = []
self._vars_read_or_written: List["Variable"] = []
self._solidity_vars_read: List["SolidityVariable"] = []
self._state_vars_written: List["StateVariable"] = []
self._internal_calls: List["InternalCallType"] = []
self._solidity_calls: List["SolidityFunction"] = []
self._low_level_calls: List["LowLevelCallType"] = []
self._high_level_calls: List["HighLevelCallType"] = []
self._library_calls: List["LibraryCallType"] = []
self._external_calls_as_expressions: List["Expression"] = []
self._expression_vars_read: List["Expression"] = []
self._expression_vars_written: List["Expression"] = []
self._expression_calls: List["Expression"] = []
# self._expression_modifiers: List["Expression"] = []
self._modifiers: List[ModifierStatements] = []
self._explicit_base_constructor_calls: List[ModifierStatements] = []
self._contains_assembly: bool = False
self._expressions: Optional[List["Expression"]] = None
self._slithir_operations: Optional[List["Operation"]] = None
self._slithir_ssa_operations: Optional[List["Operation"]] = None
self._all_expressions: Optional[List["Expression"]] = None
self._all_slithir_operations: Optional[List["Operation"]] = None
self._all_internals_calls: Optional[List["InternalCallType"]] = None
self._all_high_level_calls: Optional[List["HighLevelCallType"]] = None
self._all_library_calls: Optional[List["LibraryCallType"]] = None
self._all_low_level_calls: Optional[List["LowLevelCallType"]] = None
self._all_solidity_calls: Optional[List["SolidityFunction"]] = None
self._all_state_variables_read: Optional[List["StateVariable"]] = None
self._all_solidity_variables_read: Optional[List["SolidityVariable"]] = None
self._all_state_variables_written: Optional[List["StateVariable"]] = None
self._all_slithir_variables: Optional[List["SlithIRVariable"]] = None
self._all_nodes: Optional[List["Node"]] = None
self._all_conditional_state_variables_read: Optional[List["StateVariable"]] = None
self._all_conditional_state_variables_read_with_loop: Optional[List["StateVariable"]] = None
self._all_conditional_solidity_variables_read: Optional[List["SolidityVariable"]] = None
self._all_conditional_solidity_variables_read_with_loop: Optional[
List["SolidityVariable"]
] = None
self._all_solidity_variables_used_as_args: Optional[List["SolidityVariable"]] = None
self._is_shadowed: bool = False
self._shadows: bool = False
# set(ReacheableNode)
self._reachable_from_nodes: Set[ReacheableNode] = set()
self._reachable_from_functions: Set[Function] = set()
self._all_reachable_from_functions: Optional[Set[Function]] = None
# Constructor, fallback, State variable constructor
self._function_type: Optional[FunctionType] = None
self._is_constructor: Optional[bool] = None
# Computed on the fly, can be True of False
self._can_reenter: Optional[bool] = None
self._can_send_eth: Optional[bool] = None
self._nodes_ordered_dominators: Optional[List["Node"]] = None
self._counter_nodes = 0
# Memoize parameters:
# TODO: identify all the memoize parameters and add a way to undo the memoization
self._full_name: Optional[str] = None
self._signature: Optional[Tuple[str, List[str], List[str]]] = None
self._solidity_signature: Optional[str] = None
self._signature_str: Optional[str] = None
self._canonical_name: Optional[str] = None
self._is_protected: Optional[bool] = None
self.compilation_unit: "SlitherCompilationUnit" = compilation_unit
# Assume we are analyzing Solidity by default
self.function_language: FunctionLanguage = FunctionLanguage.Solidity
self._id: Optional[str] = NoneVariable
维护变量的类型、可见性等信息
def __init__(self):
super().__init__()
self._name: Optional[str] = None
self._initial_expression: Optional["Expression"] = None
self._type: Optional[Type] = None
self._initialized: Optional[bool] = None
self._visibility: Optional[str] = None
self._is_constant = False
self._is_immutable: bool = False
self._is_reentrant: bool = True
self._write_protection: Optional[List[str]] = NoneNode
维护控制流中的节点信息,如ir、Φ函数、读写变量等,主要用于控制流与数据流的生成中
class Node(SourceMapping, ChildFunction): # pylint: disable=too-many-public-methods
"""
Node class
"""
def __init__(
self,
node_type: NodeType,
node_id: int,
scope: Union["Scope", "Function"],
file_scope: "FileScope",
):
super().__init__()
self._node_type = node_type
# TODO: rename to explicit CFG
self._sons: List["Node"] = []
self._fathers: List["Node"] = []
## Dominators info
# Dominators nodes
self._dominators: Set["Node"] = set()
self._immediate_dominator: Optional["Node"] = None
## Nodes of the dominators tree
# self._dom_predecessors = set()
self._dom_successors: Set["Node"] = set()
# Dominance frontier
self._dominance_frontier: Set["Node"] = set()
# Phi origin
# key are variable name
self._phi_origins_state_variables: Dict[str, Tuple[StateVariable, Set["Node"]]] = {}
self._phi_origins_local_variables: Dict[str, Tuple[LocalVariable, Set["Node"]]] = {}
# self._phi_origins_member_variables: Dict[str, Tuple[MemberVariable, Set["Node"]]] = {}
self._expression: Optional[Expression] = None
self._variable_declaration: Optional[LocalVariable] = None
self._node_id: int = node_id
self._vars_written: List[Variable] = []
self._vars_read: List[Variable] = []
self._ssa_vars_written: List["SlithIRVariable"] = []
self._ssa_vars_read: List["SlithIRVariable"] = []
self._internal_calls: List["Function"] = []
self._solidity_calls: List[SolidityFunction] = []
self._high_level_calls: List["HighLevelCallType"] = [] # contains library calls
self._library_calls: List["LibraryCallType"] = []
self._low_level_calls: List["LowLevelCallType"] = []
self._external_calls_as_expressions: List[Expression] = []
self._internal_calls_as_expressions: List[Expression] = []
self._irs: List[Operation] = []
self._all_slithir_operations: Optional[List[Operation]] = None
self._irs_ssa: List[Operation] = []
self._state_vars_written: List[StateVariable] = []
self._state_vars_read: List[StateVariable] = []
self._solidity_vars_read: List[SolidityVariable] = []
self._ssa_state_vars_written: List[StateIRVariable] = []
self._ssa_state_vars_read: List[StateIRVariable] = []
self._local_vars_read: List[LocalVariable] = []
self._local_vars_written: List[LocalVariable] = []
self._slithir_vars: Set["SlithIRVariable"] = set() # non SSA
self._ssa_local_vars_read: List[LocalIRVariable] = []
self._ssa_local_vars_written: List[LocalIRVariable] = []
self._expression_vars_written: List[Expression] = []
self._expression_vars_read: List[Expression] = []
self._expression_calls: List[Expression] = []
# Computed on the fly, can be True of False
self._can_reenter: Optional[bool] = None
self._can_send_eth: Optional[bool] = None
self._asm_source_code: Optional[Union[str, Dict]] = None
self.scope: Union["Scope", "Function"] = scope
self.file_scope: "FileScope" = file_scopeExpression
各种语句的父类
def __init__(self) -> None:
super().__init__()
self._is_lvalue = FalseOperation
各种语句的封装类,继承于Expression,如二元语句:
class BinaryOperation(ExpressionTyped):
def __init__(
self,
left_expression: Expression,
right_expression: Expression,
expression_type: BinaryOperationType,
) -> None:
assert isinstance(left_expression, Expression)
assert isinstance(right_expression, Expression)
super().__init__()
self._expressions = [left_expression, right_expression]
self._type: BinaryOperationType = expression_typeContext
大部分节点类均继承该类,其中以键值对形式维护上下文中分析状态与漏洞结果等信息
def __init__(self) -> None:
super().__init__()
self._context: Dict = {"MEMBERS": defaultdict(None)}顶层节点解析:parse_top_level_from_loaded_json()
在Slither()中调用,在生成语法树后首先解析顶层节点信息,即不解析节点内容,只创建顶层节点即合约、全局变量的解释器,保存节点名、id等信息。
解析合约:parse_contracts()
解析合约中分为三步:
_analyze_first_part()
第一步创建结构体、变量、函数、合约的解析器
函数中首先进行while循环,判断合约的所有依赖合约是否被解析,若未全部解析,则置于最后:
while contracts_to_be_analyzed:
contract = contracts_to_be_analyzed[0]
contracts_to_be_analyzed = contracts_to_be_analyzed[1:]
all_father_analyzed = all(
self._underlying_contract_to_parser[father].is_analyzed
for father in contract.underlying_contract.inheritance
)
if not contract.underlying_contract.inheritance or all_father_analyzed:
self._parse_struct_var_modifiers_functions(contract)
else:
contracts_to_be_analyzed += [contract]接着调用_parse_struct_var_modifiers_functions()方法,对所有结构体、函数等创建解析器:
def _parse_struct_var_modifiers_functions(self, contract: ContractSolc):
contract.parse_structs() # struct can refer another struct
contract.parse_state_variables()
contract.parse_modifiers()
contract.parse_functions()
contract.parse_custom_errors()
contract.set_is_analyzed(True)如parse_structs()最终创建结构体解析器:
def _parse_struct(self, struct: Dict):
st = StructureContract(self._contract.compilation_unit)
st.set_contract(self._contract)
st.set_offset(struct["src"], self._contract.compilation_unit)
st_parser = StructureContractSolc(st, struct, self)
self._contract.structures_as_dict[st.name] = st
self._structures_parser.append(st_parser)此处并未进一步解析
_analyze_second_part()
第二步解析结构体与事件
同样先等待父合约解析完成:
while contracts_to_be_analyzed:
contract = contracts_to_be_analyzed[0]
contracts_to_be_analyzed = contracts_to_be_analyzed[1:]
all_father_analyzed = all(
self._underlying_contract_to_parser[father].is_analyzed
for father in contract.underlying_contract.inheritance
)
if not contract.underlying_contract.inheritance or all_father_analyzed:
self._analyze_struct_events(contract)
else:
contracts_to_be_analyzed += [contract]调用_analyze_struct_events(),进入结构体与事件解析:
def _analyze_struct_events(self, contract: ContractSolc):
contract.analyze_constant_state_variables()
# Struct can refer to enum, or state variables
contract.analyze_structs()
# Event can refer to struct
contract.analyze_events()
contract.analyze_using_for()
contract.analyze_custom_errors()
contract.set_is_analyzed(True)如analyze_structs()最终调用StructureContractSolc.analyze():
def analyze(self):
for elem_to_parse in self._elemsNotParsed:
elem = StructureVariable()
elem.set_structure(self._structure)
elem.set_offset(elem_to_parse["src"], self._structure.contract.compilation_unit)
elem_parser = StructureVariableSolc(elem, elem_to_parse)
elem_parser.analyze(self._contract_parser)
self._structure.elems[elem.name] = elem
self._structure.add_elem_in_order(elem.name)
self._elemsNotParsed = []将AST中的键值对进行完整解析赋值
_analyze_third_part()
第三步解析函数、修饰器与变量
同样等待父合约解析完成:
while contracts_to_be_analyzed:
contract = contracts_to_be_analyzed[0]
contracts_to_be_analyzed = contracts_to_be_analyzed[1:]
all_father_analyzed = all(
self._underlying_contract_to_parser[father].is_analyzed
for father in contract.underlying_contract.inheritance
)
if not contract.underlying_contract.inheritance or all_father_analyzed:
self._analyze_variables_modifiers_functions(contract)
else:
contracts_to_be_analyzed += [contract]调用_analyze_variables_modifiers_functions(),进入函数、修饰器与变量解析:
def _analyze_variables_modifiers_functions(self, contract: ContractSolc):
# State variables, modifiers and functions can refer to anything
contract.analyze_params_modifiers()
contract.analyze_params_functions()
self._analyze_params_top_level_function()
self._analyze_params_custom_error()
contract.analyze_state_variables()
contract.analyze_content_modifiers()
contract.analyze_content_functions()
self._analyze_content_top_level_function()
contract.set_is_analyzed(True)如在analyze_content_functions()中,会调用_parse_cfg()最终生成控制流图:
def analyze_content(self):
if self._content_was_analyzed:
return
self._content_was_analyzed = True
if self.is_compact_ast:
body = self._functionNotParsed.get("body", None)
if body and body[self.get_key()] == "Block":
self._function.is_implemented = True
# 生成控制流图
self._parse_cfg(body)
for modifier in self._functionNotParsed["modifiers"]:
self._parse_modifier(modifier)生成控制流图:_parse_cfg()
此时所有函数与参数都已解析完成,该函数主要调用_parse_statement()函数,根据不同表达式种类进行节点的父子连接:
def _parse_statement(
self, statement: Dict, node: NodeSolc, scope: Union[Scope, Function]
) -> NodeSolc:
"""
Return:
node
"""
# Statement = IfStatement | WhileStatement | ForStatement | Block | InlineAssemblyStatement |
# ( DoWhileStatement | PlaceholderStatement | Continue | Break | Return |
# Throw | EmitStatement | SimpleStatement ) ';'
# SimpleStatement = VariableDefinition | ExpressionStatement
name = statement[self.get_key()]
# SimpleStatement = VariableDefinition | ExpressionStatement
if name == "IfStatement":
node = self._parse_if(statement, node)
elif name == "WhileStatement":
node = self._parse_while(statement, node)
elif name == "ForStatement":
node = self._parse_for(statement, node)
elif name == "Block":
node = self._parse_block(statement, node)
elif name == "UncheckedBlock":
node = self._parse_unchecked_block(statement, node)
......如IfStatement,进入_parse_if()函数:
def _parse_if(self, if_statement: Dict, node: NodeSolc) -> NodeSolc:
# IfStatement = 'if' '(' Expression ')' Statement ( 'else' Statement )?
falseStatement = None
if self.is_compact_ast:
condition = if_statement["condition"]
# Note: check if the expression could be directly
# parsed here
condition_node = self._new_node(
NodeType.IF, condition["src"], node.underlying_node.scope
)
condition_node.add_unparsed_expression(condition)
link_underlying_nodes(node, condition_node)
true_scope = Scope(
node.underlying_node.scope.is_checked, False, node.underlying_node.scope
)
trueStatement = self._parse_statement(
if_statement["trueBody"], condition_node, true_scope
)
if "falseBody" in if_statement and if_statement["falseBody"]:
false_scope = Scope(
node.underlying_node.scope.is_checked, False, node.underlying_node.scope
)
falseStatement = self._parse_statement(
if_statement["falseBody"], condition_node, false_scope
)
else:
children = if_statement[self.get_children("children")]
condition = children[0]
# Note: check if the expression could be directly
# parsed here
condition_node = self._new_node(
NodeType.IF, condition["src"], node.underlying_node.scope
)
condition_node.add_unparsed_expression(condition)
link_underlying_nodes(node, condition_node)
true_scope = Scope(
node.underlying_node.scope.is_checked, False, node.underlying_node.scope
)
trueStatement = self._parse_statement(children[1], condition_node, true_scope)
if len(children) == 3:
false_scope = Scope(
node.underlying_node.scope.is_checked, False, node.underlying_node.scope
)
falseStatement = self._parse_statement(children[2], condition_node, false_scope)
endIf_node = self._new_node(NodeType.ENDIF, if_statement["src"], node.underlying_node.scope)
# 添加连接
link_underlying_nodes(trueStatement, endIf_node)
if falseStatement:
link_underlying_nodes(falseStatement, endIf_node)
else:
link_underlying_nodes(condition_node, endIf_node)
return endIf_node
其主要流程为创建ENDIF节点,将判断表达式转换为CONDITION节点,TRUE与FALSE作为单独节点,并创建连接关系:FATHER→CONDITION→TRUE FALSE → ENDIF ,最终返回ENDIF节点作为下次分析的父节点。
3. 支配树的生成
analyze_contracts()
在Slither()函数中,解析完成合约后,会调用analyze_contracts()进行数据流的分析,其中会进行支配树的计算。
compute_dominators()
代码整体与前置知识中一致,采用Dominator-tree Algorithm算法,计算出支配者与直接支配者。
def compute_dominators(nodes: List["Node"]):
"""
Naive implementation of Cooper, Harvey, Kennedy algo
See 'A Simple,Fast Dominance Algorithm'
Compute strict domniators
"""
for n in nodes:
n.dominators = set(nodes)
_compute_dominators(nodes)
# 计算直接支配者
_compute_immediate_dominators(nodes)compute_dominance_frontier()
采用Dominator-tree Algorithm算法,计算出支配边界。
def compute_dominance_frontier(nodes: List["Node"]):
"""
Naive implementation of Cooper, Harvey, Kennedy algo
See 'A Simple,Fast Dominance Algorithm'
Compute dominance frontier
"""
for node in nodes:
if len(node.fathers) >= 2:
for father in node.fathers:
runner = father
# Corner case: if there is a if without else
# we need to add update the conditional node
if (
runner == node.immediate_dominator
and runner.type == NodeType.IF
and node.type == NodeType.ENDIF
):
runner.dominance_frontier = runner.dominance_frontier.union({node})
while runner != node.immediate_dominator:
runner.dominance_frontier = runner.dominance_frontier.union({node})
runner = runner.immediate_dominator此处对于 IF与ENDIF做出特别处理,原因是如果没有ELSE的IF语句,同样会产生两个分叉,因此支配边界也应当考虑。
4. 数据流的生成
普通ir:generate_slithir_and_analyze()
主要通过convert_expression()方法将节点中的表达式转换为ir形式:
def convert_expression(expression, node):
# handle standlone expression
# such as return true;
# 处理if语句与return
from slither.core.cfg.node import NodeType
......
visitor = ExpressionToSlithIR(expression, node)
result = visitor.result()
......
return result在创建ExpressionToSlithIR时,进入转换函数,如二元表达式:
def _post_binary_operation(self, expression):
left = get(expression.expression_left)
right = get(expression.expression_right)
val = TemporaryVariable(self._node)
if expression.type in _signed_to_unsigned:
new_left = TemporaryVariable(self._node)
conv_left = TypeConversion(new_left, left, ElementaryType("int256"))
new_left.set_type(ElementaryType("int256"))
conv_left.set_expression(expression)
self._result.append(conv_left)
if expression.type != BinaryOperationType.RIGHT_SHIFT_ARITHMETIC:
new_right = TemporaryVariable(self._node)
conv_right = TypeConversion(new_right, right, ElementaryType("int256"))
new_right.set_type(ElementaryType("int256"))
conv_right.set_expression(expression)
self._result.append(conv_right)
else:
new_right = right
new_final = TemporaryVariable(self._node)
operation = Binary(new_final, new_left, new_right, _signed_to_unsigned[expression.type])
operation.set_expression(expression)
self._result.append(operation)
conv_final = TypeConversion(val, new_final, ElementaryType("uint256"))
val.set_type(ElementaryType("uint256"))
conv_final.set_expression(expression)
self._result.append(conv_final)
else:
operation = Binary(val, left, right, _binary_to_binary[expression.type])
operation.set_expression(expression)
self._result.append(operation)
set_val(expression, val)如d==1会生成TMP_1 = d==1,即将每种表达式都转换为赋值表达式的形式
ssa-ir:convert_expression_to_slithir_ssa
ssa主要目的是生成单一的赋值变量并添加函数传参与全局变量在数据流中的导向。
首先将本合约与父合约的全局变量传入_initial_state_variables数组中:
for contract in self.inheritance:
for v in contract.state_variables_declared:
new_var = StateIRVariable(v)
all_ssa_state_variables_instances[v.canonical_name] = new_var
self._initial_state_variables.append(new_var)将本合约的状态变量传入数组:
for v in self.variables:
if v.contract == self:
new_var = StateIRVariable(v)
all_ssa_state_variables_instances[v.canonical_name] = new_var
self._initial_state_variables.append(new_var)生成函数的ssa-ir:
for func in self.functions + self.modifiers:
func.generate_slithir_ssa(all_ssa_state_variables_instances)主要调用add_ssa_ir()函数:
首先装载函数传参与returns的初始定义:
init_definition = {}
for v in function.parameters:
if v.name:
init_definition[v.name] = (v, function.entry_point)
function.entry_point.add_ssa_ir(Phi(LocalIRVariable(v), set()))
# 返回变量初始化
for v in function.returns:
# 有参数名才初始化
if v.name:
init_definition[v.name] = (v, function.entry_point)
接着在入口节点:ENTRYPOINT插入Φ函数:
for (_, variable_instance) in all_state_variables_instances.items():
if is_used_later(function.entry_point, variable_instance):
# rvalues are fixed in solc_parsing.declaration.function, 在entrypoint添加
function.entry_point.add_ssa_ir(Phi(StateIRVariable(variable_instance), set()))
# 添加phi函数
add_phi_origins(function.entry_point, init_definition, {})
add_phi_origins()函数为循环所有节点插入Φ变量:
def add_phi_origins(node, local_variables_definition, state_variables_definition):
# Add new key to local_variables_definition
# The key is the variable_name
# The value is (variable_instance, the node where its written)
# We keep the instance as we want to avoid to add __hash__ on v.name in Variable
# That might work for this used, but could create collision for other uses
local_variables_definition = dict(
local_variables_definition,
**{v.name: (v, node) for v in node.local_variables_written},
)
state_variables_definition = dict(
state_variables_definition,
**{v.canonical_name: (v, node) for v in node.state_variables_written},
)
# For unini variable declaration
if (
node.variable_declaration
and not node.variable_declaration.name in local_variables_definition
):
local_variables_definition[node.variable_declaration.name] = (
node.variable_declaration,
node,
)
# filter length of successors because we have node with one successor
# while most of the ssa textbook would represent following nodes as one
# 添加新的 phi变量
if node.dominance_frontier and len(node.dominator_successors) != 1:
for phi_node in node.dominance_frontier:
for _, (variable, n) in local_variables_definition.items():
phi_node.add_phi_origin_local_variable(variable, n)
for _, (variable, n) in state_variables_definition.items():
phi_node.add_phi_origin_state_variable(variable, n)
if not node.dominator_successors:
return
for succ in node.dominator_successors:
add_phi_origins(succ, local_variables_definition, state_variables_definition)
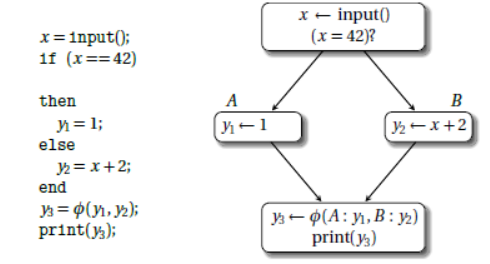
我们知道每个节点对于其支配者Φ函数值是固定的,然而在支配边界以外,Φ函数值不可控,因此需要插入新的Φ变量。
随后遍历判断是否需新添加Φ函数:
for node in function.nodes:
for (variable, nodes) in node.phi_origins_local_variables.values():
if len(nodes) < 2:
continue
if not is_used_later(node, variable):
continue
node.add_ssa_ir(Phi(LocalIRVariable(variable), nodes))
for (variable, nodes) in node.phi_origins_state_variables.values():
if len(nodes) < 2:
continue
# if not is_used_later(node, variable.name, []):
# continue
node.add_ssa_ir(Phi(StateIRVariable(variable), nodes))只有当某个节点对一个变量受到两个不同的Φ变量控制时,需要插入新的Φ函数,如前置知识中提到的:
接着调用generate_ssa_irs()函数生成ssa-ir:
generate_ssa_irs(
function.entry_point,
dict(init_local_variables_instances),
all_init_local_variables_instances,
dict(init_state_variables_instances),
all_state_variables_instances,
init_local_variables_instances,
[],
)主要逻辑就是递增左值下标,并替换右值中变量为最新变量下标:
new_ir = copy_ir(
ir,
local_variables_instances,
state_variables_instances,
temporary_variables_instances,
reference_variables_instances,
tuple_variables_instances,
all_local_variables_instances,
)
new_ir.set_expression(ir.expression)
new_ir.set_node(ir.node)
update_lvalue(
new_ir,
node,
local_variables_instances,
all_local_variables_instances,
state_variables_instances,
all_state_variables_instances,
)update_lvalue()中进行递增操作
new_var = StateIRVariable(lvalue)
new_var.index = all_state_variables_instances[lvalue.canonical_name].index + 1
all_state_variables_instances[lvalue.canonical_name] = new_var
state_variables_instances[lvalue.canonical_name] = new_var最后更新φ函数中全局变量的依赖,由于函数调用中可能更新全局变量的值,因此一个依赖于全局变量的节点同时依赖于新的下标的全局变量:
def fix_phi(self):
last_state_variables_instances = {}
initial_state_variables_instances = {}
for v in self._initial_state_variables:
last_state_variables_instances[v.canonical_name] = []
initial_state_variables_instances[v.canonical_name] = v
# 更新了一下函数中的调用造成的状态变量的改变
for func in self.functions + self.modifiers:
result = func.get_last_ssa_state_variables_instances()
for variable_name, instances in result.items():
last_state_variables_instances[variable_name] += instances
for func in self.functions + self.modifiers:
# 替换phi函数中参数
func.fix_phi(last_state_variables_instances, initial_state_variables_instances)计算依赖:compute_dependency()
主要调用compute_dependency_function()计算每个函数的参数依赖:
def compute_dependency_function(function: Function) -> None:
if KEY_SSA in function.context:
return
function.context[KEY_SSA] = {}
function.context[KEY_SSA_UNPROTECTED] = {}
is_protected = function.is_protected()
for node in function.nodes:
for ir in node.irs_ssa:
if isinstance(ir, OperationWithLValue) and ir.lvalue:
if isinstance(ir.lvalue, LocalIRVariable) and ir.lvalue.is_storage:
continue
if isinstance(ir.lvalue, ReferenceVariable):
lvalue = ir.lvalue.points_to
if lvalue:
add_dependency(lvalue, function, ir, is_protected)
add_dependency(ir.lvalue, function, ir, is_protected)
# 转化为非ssa版本
function.context[KEY_NON_SSA] = convert_to_non_ssa(function.context[KEY_SSA])
function.context[KEY_NON_SSA_UNPROTECTED] = convert_to_non_ssa(
function.context[KEY_SSA_UNPROTECTED]
)最终依赖以键值对形式保存在函数的上下文中,其中
- KEY_SSA为SSA形式依赖:

- KEY_NON_SSA为普通形式依赖:

两种形式都为 def-use 链,即根据使用的参数能像上回溯找到流经的参数
在计算完函数以来后会调用propagate_function(),整合所有依赖关系:
def transitive_close_dependencies(
context: Context_types, context_key: str, context_key_non_ssa: str
) -> None:
# transitive closure
changed = True
keys = context.context[context_key].keys()
while changed:
changed = False
to_add = defaultdict(set)
# &: 计算交集,取出每个依赖的变量的依赖,追溯回最初的依赖
[ # pylint: disable=expression-not-assigned
[
to_add[key].update(context.context[context_key][item] - {key} - items)
# print(key, ":", item,[ a.__str__() for a in context.context[context_key][item]],key, [ a.__str__() for a in items], context.context[context_key][item]-{key}-items)
for item in items & keys
]
for key, items in context.context[context_key].items()
]
for k, v in to_add.items():
# Because we dont have any check on the update operation
# We might update an empty set with an empty set
if v:
changed = True
context.context[context_key][k] |= v
context.context[context_key_non_ssa] = convert_to_non_ssa(context.context[context_key])
如SSA依赖:
b_1 : ['b_2', 'b_0']
TMP_0 : ['d_1']
a_1 : []
TUPLE_0 : ['add_1']
a_2 : ['a_2', 'a_1']
b_2 : ['b_2', 'b_1']
TMP_2 : ['c_0']
c_1 : ['TMP_2']
TMP_3 : ['a_2', 'b_2']
c_2 : ['TMP_3']第一次循环后to_add为:
b_1 []
a_2 []
b_2 ['b_0']
c_1 ['c_0']
TMP_3 ['a_1', 'b_1']
c_2 ['a_2', 'b_2']整体依赖变为:
b_1 ['b_2', 'b_0']
TMP_0 ['d_1']
a_1 []
TUPLE_0 ['add_1']
a_2 ['a_2', 'a_1']
b_2 ['b_2', 'b_0', 'b_1']
TMP_2 ['c_0']
c_1 ['c_0', 'TMP_2']
TMP_3 ['a_1', 'a_2', 'b_2', 'b_1']
c_2 ['a_2', 'TMP_3', 'b_2']第二次循环后to_add为:
b_1 []
a_2 []
b_2 []
c_1 []
TMP_3 ['b_0']
c_2 ['b_0', 'a_1', 'b_1']整体依赖变为:
b_1 ['b_2', 'b_0']
TMP_0 ['d_1']
a_1 []
TUPLE_0 ['add_1']
a_2 ['a_2', 'a_1']
b_2 ['b_2', 'b_0', 'b_1']
TMP_2 ['c_0']
c_1 ['c_0', 'TMP_2']
TMP_3 ['b_2', 'b_0', 'a_1', 'a_2', 'b_1']
c_2 ['TMP_3', 'b_2', 'b_0', 'a_1', 'a_2', 'b_1']第三次循环后to_add变为:
b_1 []
a_2 []
b_2 []
c_1 []
TMP_3 []
c_2 []整体依赖不变,结束循环,此时非SSA依赖变为:
b ['b']
TMP_0 ['d']
a ['a']
TUPLE_0 ['add']
TMP_2 ['c']
c ['TMP_2', 'b', 'a', 'c', 'TMP_3']
TMP_3 ['b', 'a']将与全局变量或函数传参的依赖添加进依赖关系中
5. 漏洞检测
整合所有漏洞检测器:_run_all_detectors()
在调用run_detectors()检测前,需先对所有检测器进行注册:
def _run_all_detectors(slither: Slither):
detectors = [getattr(all_detectors, name) for name in dir(all_detectors)]
detectors = [d for d in detectors if inspect.isclass(d) and issubclass(d, AbstractDetector)]
for detector in detectors:
slither.register_detector(detector)
slither.run_detectors()共有81种检测器:
ABIEncoderV2Array
ArbitrarySendErc20NoPermit
ArbitrarySendErc20Permit
ArbitrarySendEth
ArrayByReference
ArrayLengthAssignment
Assembly
AssertStateChange
Backdoor
BadPRNG
BooleanConstantMisuse
BooleanEquality
BuiltinSymbolShadowing
ConstCandidateStateVars
ConstantFunctionsAsm
ConstantFunctionsState
ConstantPragma
ControlledDelegateCall
CostlyOperationsInLoop
DeadCode
DelegatecallInLoop
DeprecatedStandards
DivideBeforeMultiply
DomainSeparatorCollision
EnumConversion
ExternalFunction
FunctionInitializedState
IncorrectERC20InterfaceDetection
IncorrectERC721InterfaceDetection
IncorrectSolc
IncorrectStrictEquality
IncorrectUnaryExpressionDetection
LocalShadowing
LockedEther
LowLevelCalls
MappingDeletionDetection
MissingEventsAccessControl
MissingEventsArithmetic
MissingInheritance
MissingZeroAddressValidation
ModifierDefaultDetection
MsgValueInLoop
MultipleCallsInLoop
MultipleConstructorSchemes
NameReused
NamingConvention
PredeclarationUsageLocal
ProtectedVariables
PublicMappingNested
RedundantStatements
ReentrancyBenign
ReentrancyEth
ReentrancyEvent
ReentrancyNoGas
ReentrancyReadBeforeWritten
ReusedBaseConstructor
RightToLeftOverride
ShadowingAbstractDetection
ShiftParameterMixup
SimilarVarsDetection
StateShadowing
StorageSignedIntegerArray
Suicidal
Timestamp
TooManyDigits
TxOrigin
TypeBasedTautology
UncheckedLowLevel
UncheckedSend
UncheckedTransfer
UnimplementedFunctionDetection
UnindexedERC20EventParameters
UninitializedFunctionPtrsConstructor
UninitializedLocalVars
UninitializedStateVarsDetection
UninitializedStorageVars
UnprotectedUpgradeable
UnusedReturnValues
UnusedStateVars
VoidConstructor
WriteAfterWrite以重入漏洞ReentrancyEth演示检测过程:
各重入型漏洞均继承于Reentrancy,初始化时首先调用父类的_explore()方法:
def _explore(self, node: Optional[Node], skip_father: Optional[Node] = None) -> None:
if node is None:
return
fathers_context = AbstractState()
fathers_context.merge_fathers(node, skip_father, self)
# Exclude path that dont bring further information
if node in self.visited_all_paths:
if self.visited_all_paths[node].does_not_bring_new_info(fathers_context):
return
else:
self.visited_all_paths[node] = AbstractState()
# 合并
self.visited_all_paths[node].add(fathers_context)
node.context[self.KEY] = fathers_context
contains_call = fathers_context.analyze_node(node, self)
node.context[self.KEY] = fathers_context
sons = node.sons
if contains_call and node.type in [NodeType.IF, NodeType.IFLOOP]:
if _filter_if(node):
son = sons[0]
self._explore(son, skip_father=node)
sons = sons[1:]
else:
son = sons[1]
self._explore(son, skip_father=node)
sons = [sons[0]]
for son in sons:
self._explore(son)主要作用为记录节点的读写变量、是否有函数调用、是否发送以太坊信息,其中读变量、是否有函数调用、是否发送以太坊均继承于父节点,这是合理的,因为这些操作同样会影响子节点。
接着返回子类,继续检测逻辑:
reentrancies = self.find_reentrancies()查找可能存在重入的节点:
def find_reentrancies(self) -> Dict[FindingKey, Set[FindingValue]]:
result: Dict[FindingKey, Set[FindingValue]] = defaultdict(set)
for contract in self.contracts: # pylint: disable=too-many-nested-blocks
variables_used_in_reentrancy = contract.state_variables_used_in_reentrant_targets
for f in contract.functions_and_modifiers_declared:
for node in f.nodes:
# dead code
if not self.KEY in node.context:
continue
if node.context[self.KEY].calls and node.context[self.KEY].send_eth:
# 在调用节点以后的节点
if not any(n != node for n in node.context[self.KEY].send_eth):
continue
read_then_written = set()
for c in node.context[self.KEY].calls:
if c == node:
continue
read_then_written |= {
FindingValue(
v,
node,
tuple(sorted(nodes, key=lambda x: x.node_id)),
tuple(
sorted(
variables_used_in_reentrancy[v], key=lambda x: str(x)
)
),
)
for (v, nodes) in node.context[self.KEY].written.items()
# 判断该变量在调用函数时是否用到
if v in node.context[self.KEY].reads_prior_calls[c]
and (f.is_reentrant or v in variables_used_in_reentrancy)
}
if read_then_written:
# calls are ordered
finding_key = FindingKey(
function=node.function,
calls=to_hashable(node.context[self.KEY].calls),
send_eth=to_hashable(node.context[self.KEY].send_eth),
)
result[finding_key] |= set(read_then_written)
return result即在满足以下情况时认为存在重入漏洞:
- 存在外部调用
- 外部调用读取某变量
- 该变量在外部调用以后的语句中被重写
但此处明显看出存在不严谨处,如:
contract A{
uint c = 100;
function g(uint d, address payable add) internal returns(uint){
if(d > 0){
add.call.value(100)("");
c = c - 100;
}
return c;
}
}此时由于写入变量与调用时使用的变量不一致,工具无法检测出漏洞。
此处为降低误报率而作出的折中选择,如直接检测外部调用后是否存在状态变量的写入,则容易导致误报率大大升高。





