引介:并行区块构建
- flashbots
- 发布于 2024-11-14 10:18
- 阅读 2338
并行区块构建
- 原文链接:writings.flashbots.net/parallel-bui...
- 译者:AI翻译官,校对:翻译小组
- 本文链接:learnblockchain.cn/article…

在这篇博客文章中,我们介绍了一种新的区块构建方法:并行区块构建。与传统的顺序构建算法将所有交易视为潜在冲突不同, 并行区块构建认识到区块中的大多数交易实际上是独立的。当用户用 ETH 兑换 USDC 时,这并不影响某人铸造 NFT——那么为什么要顺序处理它们呢?
并行构建不会这样做。它提前识别出哪些交易组确实存在冲突,然后并行处理这些冲突。并行处理为我们带来了几个关键好处:
- 更快的构建:通过隔离冲突的交易,我们可以同时处理独立的冲突组,从而减少整体延迟
- 更好的排序:可以并行尝试多种构建算法,而不需要将单一算法应用于整个区块
- 资源最大化:可用的计算能力灵活地在必要的和投机的优化之间转移,确保资源使用最大化
- 流水线(Pipelining):关键组件独立且并发地操作——从订单流处理到冲突解决再到区块组装
这篇文章描述了我们的开源实现并分享了测试的早期结果:在生产环境中,它已经能够在 19% 的时间内构建出更有价值的区块,而在回测中显示出高达 50% 的潜力。
让我们深入了解它是如何工作的。
感谢 Robert Anessi 提供的许多启发性想法,以及 Daniel 和 Vitaly 的贡献。
架构
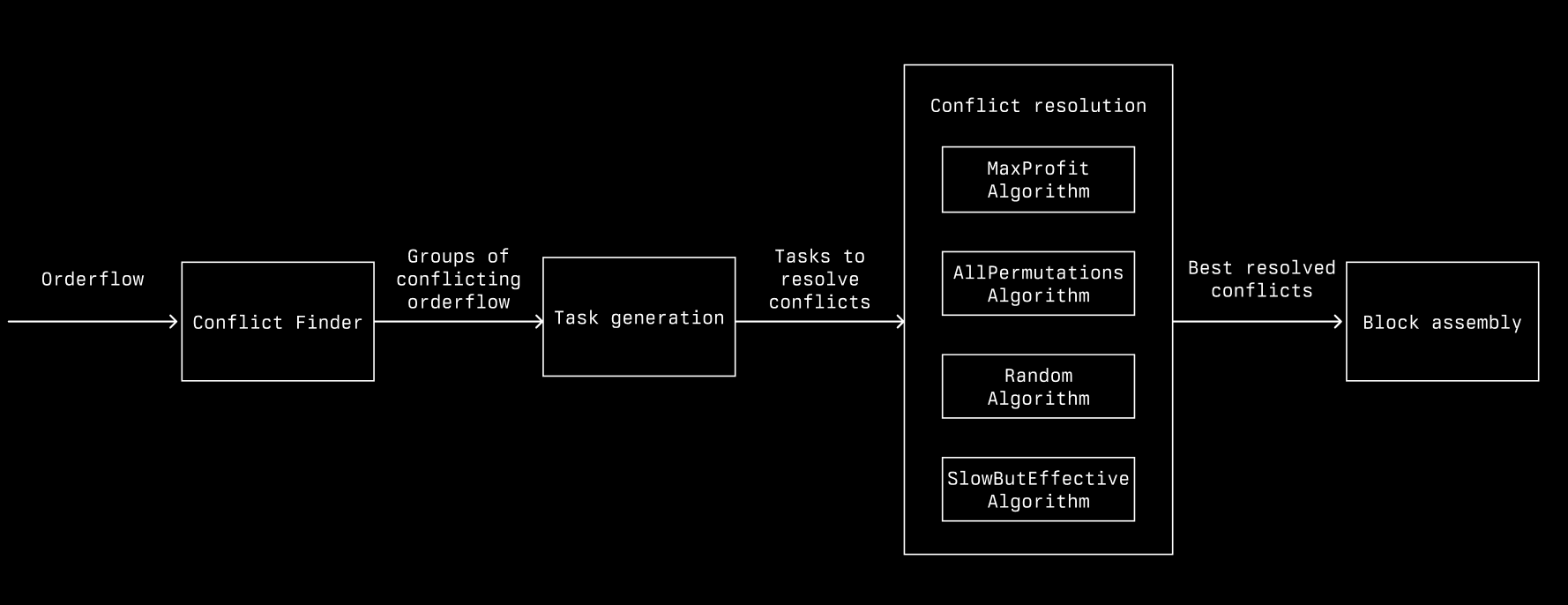
上图是我们的高层架构
- 冲突查找:识别并分组具有重叠存储读取和写入的交易,使我们能够将冲突交易组分开以进行解决。
- 任务生成:创建任务以解决冲突,并帮助战略性地管理资源利用。
- 冲突解决:一组共享任务队列的工作线程尝试并行解决冲突。
- 区块组装:通过组合最佳解决的冲突和独立交易来组装最终区块。
下面我们将详细介绍每个组件。
冲突查找
第一步,冲突识别,隔离可能基于共享存储读取和写入而冲突的交易组。我们的实现使用 ConflictFinder 快速通过维护存储槽和交易组之间的映射来分组交易。对于每个交易,它识别潜在冲突,并根据冲突的数量采取三条路径之一:
- 无冲突:该交易形成一个新的独立组。
- 单一冲突:该交易加入现有组。
- 多个冲突:该交易将所有冲突组合并为一个更大的组。
结果是一组 ConflictGroup 结构,每个结构包含其成员交易以供解决。
/// ConflictGroups 描述了一组冲突的订单.
pub struct ConflictGroup {
pub id: usize,
pub orders: Arc<Vec<SimulatedOrder>>,
pub conflicting_group_ids: Arc<HashSet<usize>>,
}任务生成
一旦定义了冲突组,ConflictTaskGenerator 生成优先级任务以解决它们。我们并不是采用单一策略,而是同时探索多种方法,这带来了几个好处:
- 多种并行策略:不同的冲突组可以用不同的算法进行优化,因此我们同时运行多种算法,并为每个冲突组选择最佳结果。
- 快速结果 + 深度搜索:贪婪启发式方法提供快速的初步解决方案,而我们可以并行运行更深入的算法,以便后续找到更高价值的结果。
- 资源最大化:工作线程不应闲置。当高优先级任务完成时,工作线程可以将重点转移到低优先级的投机任务上。
这是我们用来定义每个任务的结构
/// ConflictTask 提供一个用于解决特定 [ConflictGroup] 的任务,使用特定的 [Algorithm].
pub struct ConflictTask
{
pub group_idx: usize,
pub algorithm: Algorithm,
pub priority: TaskPriority,
pub group: ConflictGroup,
pub created_at: Instant,
}
/// 定义任务的优先级
pub enum TaskPriority {
Low = 0,
Medium = 1,
High = 2,
}
/// Algorithm 提供用于解决 [ConflictGroup] 的算法.
pub enum Algorithm {
Greedy, // 最大 gas 价格,最大利润
ReverseGreedy,
Length,
AllPermutations,
Random { seed: u64, count: usize },
}这种灵活的方法使我们能够尝试多种算法并有效地处理它们的优先级,在快速和全面结果之间取得平衡。
冲突解决
冲突解决利用一组工作线程,每个线程从共享任务队列中提取任务。每个线程并行执行其任务的指定算法,然后将结果写入共享的“最佳结果”存储。这里的一个关键优化是 模拟缓存:在评估相同交易的不同排序时,我们重用先前计算的结果以减少冗余。
/// 这不是实际代码,但它展示了核心过程
self.thread_pool.spawn(move || {
while !cancellation_token.is_cancelled() {
if let Some(task) = task_queue.pop() {
// 处理任务并找到最佳排序
let result = process_task(task);
result_sender.send(result);
}
}
});
...
/// 在并发环境中收集和管理每组的最佳结果.
pub struct ResultsAggregator {
result_receiver: std_mpsc::Receiver<(GroupId, (ResolutionResult, ConflictGroup))>,
best_results: Arc<BestResults>,
}
/// 共享最佳结果实例
pub struct BestResults {
pub data: DashMap<GroupId, (ResolutionResult, ConflictGroup)>,
pub version: AtomicU64,
}ResultsAggregator 监控工作线程发送的结果,并仅保留每个冲突的最高价值解决方案。
区块组装
在冲突解决后,BlockBuildingResultAssembler 将每个冲突组的最佳解决方案与独立交易结合起来,创建最终区块。这个步骤很简单:由于冲突已经解决,组装过程涉及的排序约束最小,我们可以简单地将组合并在一起。
结果
对并行构建器的测试产生了令人鼓舞的结果。
在高 MEV 环境中的回测
在高 MEV 日(复杂有序区块更可能出现)中,对 2000 个区块进行回测,发现并行构建器构建出比仅使用贪婪算法更好的区块的概率为 50%,产生了 40 个额外的 ETH 价值。有趣的是,这些额外价值大多集中在少数几个区块中:前 20 个区块产生了 25 个额外的 ETH,前 75 个区块产生了 35 个 ETH。
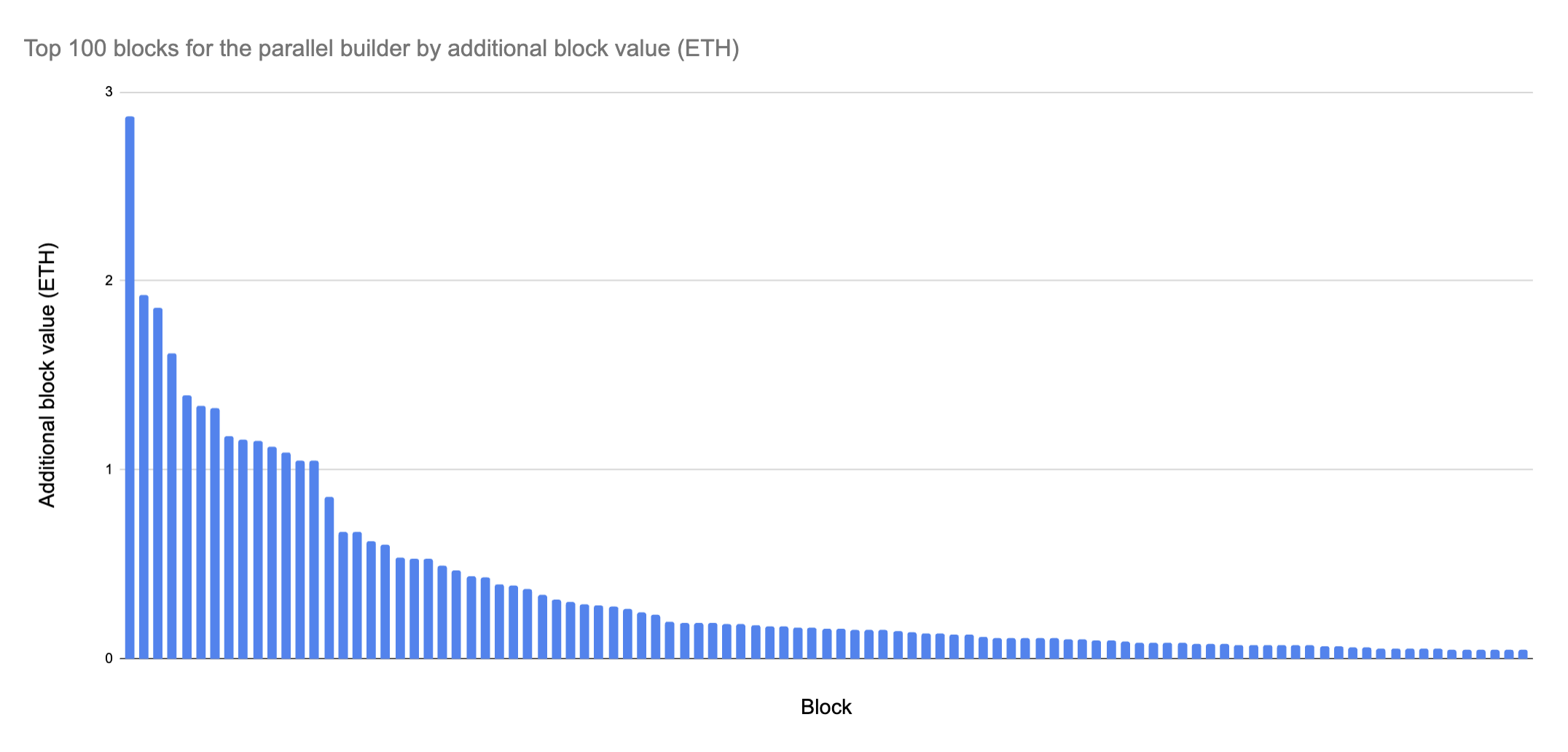
如果我们查看按区块价值百分比增长的前几个区块,可以观察到类似的分布,少量区块中有大量集中,而价值急剧下降。
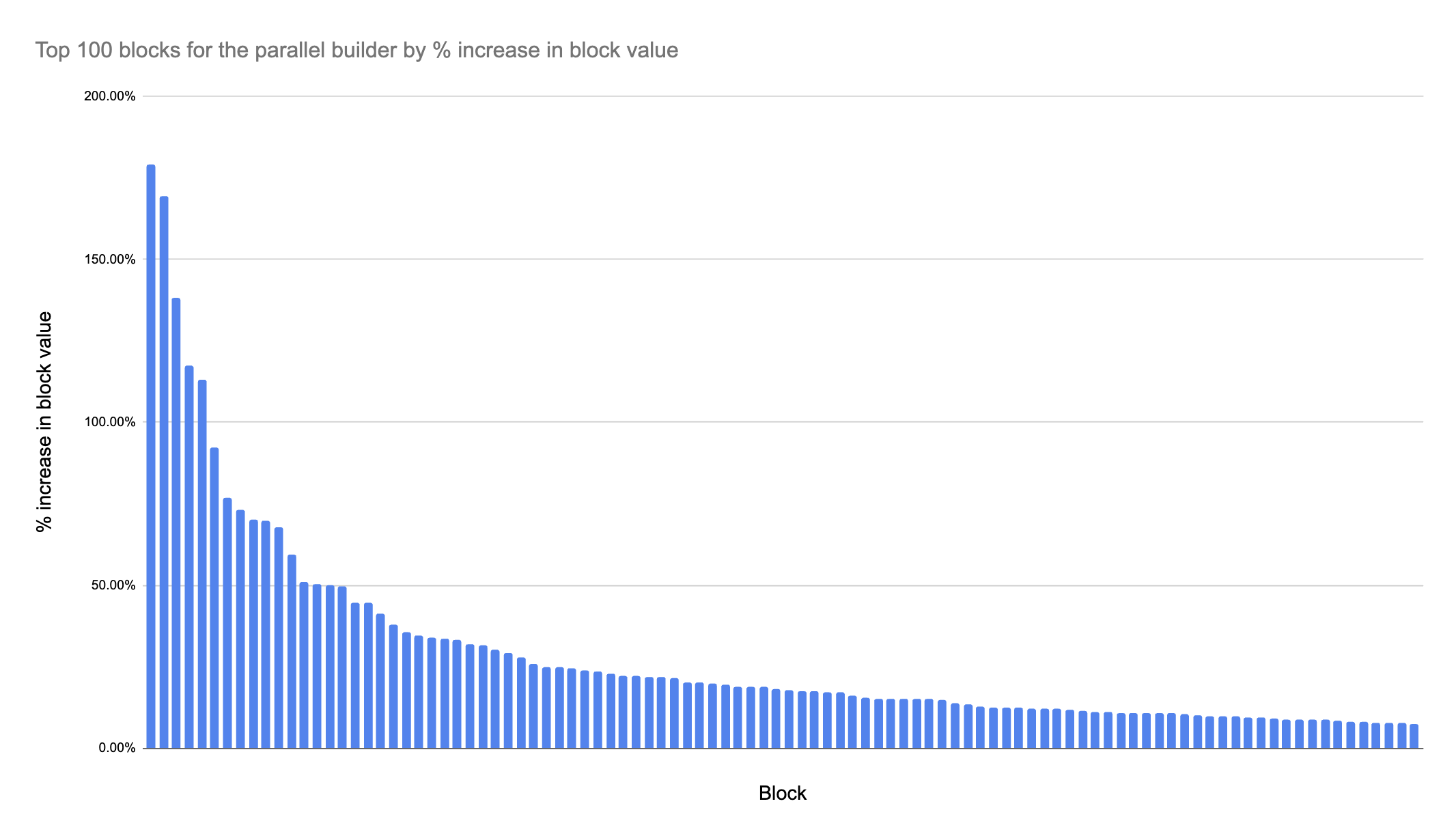
这种模式表明,少量区块从更复杂的排序中显著受益,而大多数区块则获得很少或适度的收益。
最后,我们观察到我们的实现还有改进的空间:一些交易被贪婪算法包含,而并未被并行构建器包含。理论上这不应该发生,因此这明显表明某处存在 bug。
在低 MEV 环境中的回测
在低 MEV 环境中对 2000 个区块进行回测,60% 的区块中并行构建器的结果优于任何贪婪算法。然而,这些改进带来的额外价值非常有限。最多每个区块有 0.05 个额外的 ETH,但具有额外价值的中位数区块的盈利能力低于 0.005 ETH。这些结果表明,当活动较少时,贪婪算法是足够的,这在直觉上是合理的。
来自实时生产(低 MEV)环境的结果
在生产部署的第一周——一个相对低 MEV 的时间段——并行构建器构建更好区块的频率为 19%。对于一小部分区块,它的盈利能力更高:在 3% 的区块中,并行构建器的价值比下一个最佳算法高出 100%!这大致与我们在回测中看到的结果相匹配,其中更好的合并不成比例地影响少量区块。
然而,并行构建器仅在 20% 的时间内生成更好区块而不是 50-60% 的事实表明,实时版本还有改进的空间。直觉上这可能是由于寻找冲突和异步通信的延迟开销,但需要更多分析。
总体而言,我们认为这些结果显示了这种区块构建模型的巨大潜力,特别是随着更复杂和专门构建的合并算法的实施。
未来工作
在这个架构上有许多令人兴奋的未来工作方向:
- 外包合并: 允许外部搜索者处理冲突解决,利用类似于 TDX 中的区块底部搜索者 的无权限结构。我们正在设计这个系统的早期阶段。如果你对此感兴趣,请在 Telegram 上联系 @astarinmymind。
- 新算法: 并行架构允许使用高级策略,如特定应用的合并规则(例如,DEX 特定规则)和在顺序处理下不可行的穷举算法。
- 改进冲突识别: 改进 ConflictFinder,以提供更细粒度的交易依赖数据,可以减少最佳排序的搜索空间。
- 更好的取消处理: 改进冲突识别中的取消处理,以及如何将其级联到系统的其他部分(待处理任务、最佳结果存储等)。
- 区块缓存: 类似于模拟缓存,为超快速的新区块缓存整个区块,当无冲突的订单流被更新时。
- 处理可变执行: 在区块中不同位置改变执行的交易难以处理,因为它们使得正确的冲突识别变得困难。我们可以改进如何识别和处理这些情况。
加入我们
- 代码是 开源的,如果你想查看或贡献。
- 我们正在招聘 构建器的员工级工程师,以研究类似的行业领先理念。如果你感兴趣并想了解更多,请随时联系。
- 我们还有许多其他 工程和产品职位开放。
- 如果你有兴趣在 隐私流上运行合并算法,类似于在 TDX 中的搜索,请在 Telegram 上联系 @astarinmymind。





