探索全同态加密
- Vitalik Buterin
- 发布于 2020-07-22 12:55
- 阅读 1805
文章深入探讨了全同态加密(FHE)的概念、分类及其在区块链等领域的应用,详细介绍了部分同态加密、部分同态加密和全同态加密的区别,以及如何通过自举、重线性化和模数转换等技术来实现和优化全同态加密。
探索全同态加密
探索全同态加密
特别感谢 Karl Floersch 和 Dankrad Feist 的审阅
长期以来,全同态加密一直被认为是密码学的圣杯之一。全同态加密(FHE)的承诺非常强大:它是一种允许第三方对加密数据进行计算并获得加密结果的加密方式,第三方可以将结果返回给拥有原始数据解密密钥的人,而无需第三方能够解密数据或结果本身。
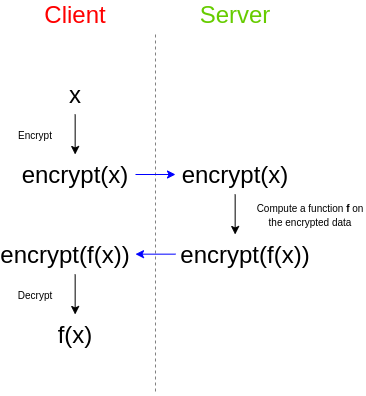
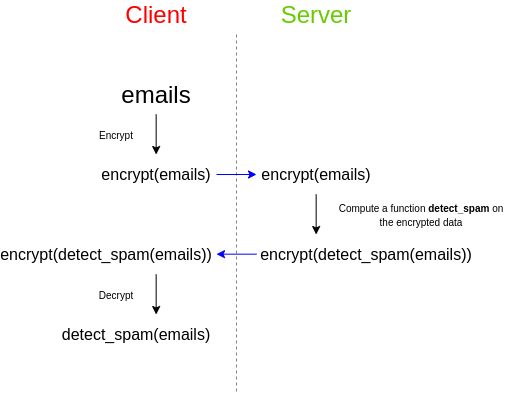
举个简单的例子,假设你有一组电子邮件,你想使用第三方垃圾邮件过滤器来检查它们是否是垃圾邮件。垃圾邮件过滤器希望保护其算法的隐私:要么垃圾邮件过滤器提供商希望保持其源代码的封闭性,要么垃圾邮件过滤器依赖于一个非常大的数据库,他们不想公开这个数据库,因为这会使得攻击变得更加容易,或者两者兼有。然而,你关心数据的隐私,并且不想将未加密的电子邮件上传到第三方。那么你可以这样做:
全同态加密有许多应用,包括在区块链领域。一个关键的例子是它可以用于实现隐私保护的轻客户端(轻客户端向服务器发送一个加密的索引 i,服务器计算并返回 data[0] * (i = 0) + data[1] * (i = 1) + ... + data[n] * (i = n),其中 data[i] 是块或状态中的第 i 个数据及其 Merkle 分支,(i = k) 是一个表达式,如果 i = k 则返回 1,否则返回 0;轻客户端获得所需的数据,而服务器无法得知轻客户端请求了什么)。
它还可以用于:
- 更高效的隐形地址协议,以及更一般的隐私保护协议的可扩展性解决方案,这些协议目前要求每个用户亲自扫描整个区块链以查找传入的交易
- 隐私保护的数据共享市场,允许用户对其数据进行某些特定计算,同时保持对数据的完全控制
- 更强大的密码学原语的组成部分,例如更高效的多方计算协议,甚至可能最终实现混淆
事实证明,全同态加密在概念上并不难理解!
部分、半、全同态加密
首先,关于定义的一点说明。同态加密有不同类型,有些比其他更强大,它们之间的区别在于可以对加密数据执行哪些类型的函数。
- 部分同态加密 只允许对加密数据执行非常有限的操作:要么只是加法(因此给定
encrypt(a)和encrypt(b),你可以计算encrypt(a+b)),要么只是乘法(给定encrypt(a)和encrypt(b),你可以计算encrypt(a*b))。 - 半同态加密 允许执行加法以及有限次数的乘法(或者,最高到某个有限次数的多项式)。也就是说,如果你有
encrypt(x1) ... encrypt(xn)(假设这些是“原始”加密,而不是同态计算的结果),你可以计算encrypt(p(x1 ... xn)),只要p(x1 ... xn)是一个次数< D的多项式,其中D是某个特定的次数限制(D通常非常低,比如 5-15)。 - 全同态加密 允许无限次的加法和乘法。加法和乘法允许你复制任何二进制电路门(
AND(x, y) = x*y,OR(x, y) = x+y-x*y,XOR(x, y) = x+y-2*x*y或者如果你只关心奇偶性则为x+y,NOT(x) = 1-x...),因此这足以对加密数据执行任意计算。
部分同态加密相当容易;例如,RSA 具有乘法同态性:enc(x)=x^e,enc(y)=y^e,因此 enc(x)*enc(y)=(xy)^e=enc(xy)。椭圆曲线可以提供类似的加法性质。事实证明,允许同时执行加法和乘法要困难得多。
一个简单的半同态加密算法
在这里,我们将介绍一个非常简单的半同态加密算法(即支持有限次乘法的算法)。Craig Gentry 在 2009 年使用这种技术的更复杂版本创建了第一个全同态加密方案。最近的努力已经转向使用基于向量和矩阵的不同方案,但我们仍然会首先介绍这种技术。
我们将所有这些加密方案描述为密钥方案;也就是说,相同的密钥用于加密和解密。任何密钥同态加密方案都可以轻松转换为公钥方案:“公钥”通常只是许多零的加密集合,以及一个一的加密(可能还有更多的二的幂次)。要加密一个值,通过添加适当的非零加密子集来生成它,然后添加一个随机的零加密子集以“随机化”密文,使其无法辨认。
这里的密钥是一个大素数 p(假设 p 有数百甚至数千位)。该方案只能加密 0 或 1,并且“加法”变为 XOR,即 1 + 1 = 0。要加密一个值 m(要么是 0,要么是 1),生成一个大的随机值 R(通常比 p 更大)和一个较小的随机值 r(通常比 p 小得多),并输出:
enc(m) = R * p + r * 2 + m要解密密文 ct,计算:
dec(ct) = (ct mod p) mod 2要添加两个密文 ct1 和 ct2,你只需将它们相加:ct1 + ct2。而要乘以两个密文,你再次...将它们相乘:ct1 * ct2。我们可以证明同态性质(加密的和是和的加密,乘积也是如此)如下。
设:
ct1 = R1 * p + r1 * 2 + m1
ct2 = R2 * p + r2 * 2 + m2我们相加:
ct1 + ct2 = R1 * p + R2 * p + r1 * 2 + r2 * 2 + m1 + m2可以重写为:
(R1 + R2) * p + (r1 + r2) * 2 + (m1 + m2)这与 m1 + m2 的密文形式完全相同。如果你解密它,第一个 mod p 移除第一项,第二个 mod 2 移除第二项,剩下的就是 m1 + m2(记住如果 m1 = 1 且 m2 = 1,那么 2 将被吸收到第二项中,你将得到零)。所以,瞧,我们有加法同态性!
现在让我们检查乘法:
ct1 * ct2 = (R1 * p + r1 * 2 + m1) * (R2 * p + r2 * 2 + m2)或者:
(R1 * R2 * p + r1 * 2 + m1 + r2 * 2 + m2) * p +
(r1 * r2 * 2 + r1 * m2 + r2 * m1) * 2 +
(m1 * m2)这只是将上述乘积展开,并将所有包含 p 的项分组,然后将所有剩余的包含 2 的项分组,最后剩下的项是消息的乘积。如果你解密,那么 mod p 再次移除第一组,mod 2 移除第二组,只剩下 m1 * m2。
但这里有两个问题:首先,密文本身的大小增加了(当你乘以时,长度大约翻倍),其次,较小的 *2 项中的“噪声”(通常也称为“误差”)也以平方级增加。将这种误差添加到密文中是必要的,因为该方案的安全性基于近似 GCD 问题:
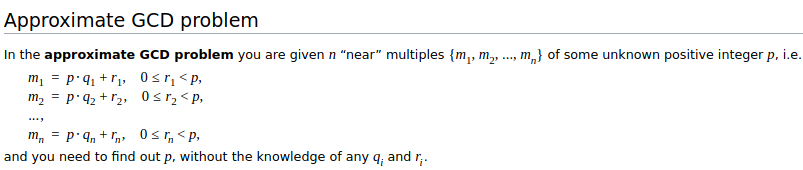
如果我们使用“精确 GCD 问题”,破解系统将很容易:如果你只有一组形式为 p * R1 + m1, p * R2 + m2... 的表达式,那么你可以使用欧几里得算法有效地计算最大公约数 p。但如果密文只是 p 的近似倍数,并且带有一些“误差”,那么快速提取 p 就变得不切实际,因此该方案可以是安全的。
不幸的是,误差引入了一个固有的限制:如果你将密文相互乘以足够多次,误差最终会增长到超过 p,此时 mod p 和 mod 2 步骤会相互“干扰”,使得数据无法提取。这将是所有这些同态加密方案中的一个固有权衡:从近似的“带有误差”的方程中提取信息比从精确方程中提取信息要困难得多,但你在加密数据上执行计算时添加的任何误差都会迅速增加,限制了你在误差变得无法控制之前可以执行的计算量。这就是为什么这些方案只是“半”同态的。
自举
这个问题有两种解决方案。首先,在许多半同态加密方案中,有一些巧妙的技巧可以使乘法仅将误差增加一个常数因子(例如 1000 倍),而不是平方。将误差增加 1000 倍听起来仍然很多,但请记住,如果 p(或其他方案中的等效项)是一个 300 位的数字,这意味着你可以将数字相互乘以 100 次,这足以计算非常广泛的计算类别。其次,有 Craig Gentry 的“自举”技术。
假设你有一个密文 ct,它是某个 m 在密钥 p 下的加密,并且有大量误差。我们的想法是通过将其转换为另一个密钥 p2 下的 m 的新密文来“刷新”密文,这个过程“清除”了旧的误差(尽管它会引入固定量的新误差)。这个技巧非常巧妙。p 和 p2 的持有者提供了一个“自举密钥”,它由在密钥 p2 下加密的p 的位组成,以及 p2 的公钥。任何在 p 下加密的数据上进行计算的人都会获取密文 ct 的位,并分别将这些位在 p2 下加密。然后,他们会同态地计算在 p 下的解密,使用这些密文,并得到单个位,这将是 m 在 p2 下的加密。
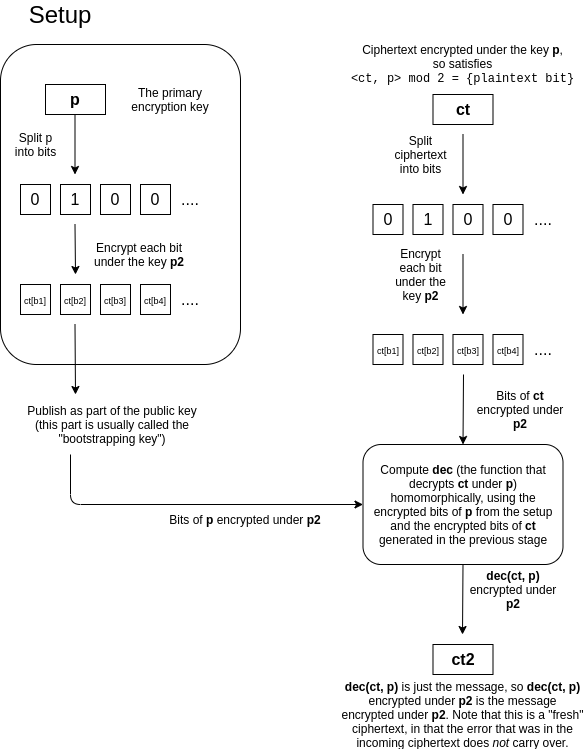
这很难理解,所以我们可以重新表述如下。解密过程 dec(ct, p) 本身就是一个计算,因此它本身可以作为一个电路实现,该电路将 ct 的位和 p 的位作为输入,并输出解密的位 m ∈ {0, 1}。如果有人有一个在 p 下加密的密文 ct,p2 的公钥,以及在 p2 下加密的 p 的位,那么他们可以“同态地”计算 dec(ct, p) = m,并得到 m 在 p2 下的加密。注意,解密过程本身清除了旧的误差;它只输出 0 或 1。解密过程本身是一个电路,其中包含加法或乘法,因此它会引入新的误差,但这个新的误差不依赖于原始加密中的误差量。
但是...有一个问题。在上述方案中(无论是否使用循环安全性),误差增长得如此之快,以至于即使方案本身的解密电路也无法处理。也就是说,m 在 p2 下的新加密已经有太多误差,以至于无法读取。这是因为每个 AND 门将误差的位长加倍,因此使用 d 位模数 p 的方案只能处理少于 log(d) 次乘法(串联),但解密需要在一个由这些二进制逻辑门组成的电路中计算 mod p,这需要...超过 log(d) 次乘法。
Craig Gentry 想出了一些巧妙的技巧来绕过这个问题,但它们可能过于复杂,无法解释;相反,我们将直接跳到 2011 年和 2013 年的新工作,它们以不同的方式解决了这个问题。
带误差学习
为了进一步推进,我们将介绍 Brakerski 和 Vaikuntanathan 在 2011 年引入的一种不同类型的半同态加密,并展示如何自举它。在这里,我们将不再将密钥和密文视为整数,而是将它们视为向量。给定一个密钥 k = k1, k2....kn,要加密一个消息 m,构造一个向量 c = c1, c2...cn,使得内积(或“点积”)<c, k> = c1k1 + c2k1 + ... + cnkn,模某个固定数 p,等于 m + 2e,其中 m 是消息(必须为 0 或 1),e 是一个小的(比 p 小得多)“误差”项。如前所述,可以通过构造一组零的加密来构造允许加密但不允许解密的“公钥”;加密者可以随机组合这些方程的子集,并在他们加密的消息为 1 时添加 1。要解密密文 c,知道密钥 k,你可以计算 <c, k> 模 p,并查看结果是奇数还是偶数(这是我们之前使用的“模 p 模 2”技巧)。注意,这里的 mod p 通常是一个“对称”模,即它返回一个介于 −p/2 和 p/2 之间的数字(例如,137 mod 10 = -3,212 mod 10 = 2);这允许我们的误差为正或负。此外,p 不一定必须是素数,但它必须是奇数。
| 密钥 | 3 | 14 | 15 | 92 | 65 |
|---|---|---|---|---|---|
| 密文 | 2 | 71 | 82 | 81 | 8 |
在这个例子中,我们设置模数 p = 103。点积是 3 * 2 + 14 * 71 + 15 * 82 + 92 * 81 + 65 * 8 = 10202,而 10202 = 99 * 103 + 5。5 本身当然是 2 * 2 + 1,所以消息是 1。注意,在实践中,密钥的第一个元素通常设置为 1;这使得生成特定值的密文更容易(看看你是否能弄清楚为什么)。
该方案的安全性基于一个称为“带误差学习”(LWE)的假设——或者,用更专业但更容易理解的术语来说,求解带有误差的方程组的难度。

密文本身可以被视为一个方程:k1c1 + .... + kncn ≈ 0,其中密钥 k1...kn 是未知数,密文 c1...cn 是系数,而等式只是近似的,因为既有消息(0 或 1)又有误差(2e 对于某个相对较小的 e)。LWE 假设确保即使你访问了许多这样的密文,你也无法恢复 k。
密文相乘
很容易验证加密是加性的:如果 <ct1, k> = 2e1 + m1 且 <ct2, k> = 2e2 + m2,那么 <ct1 + ct2, k> = 2(e1 + e2) + m1 + m2(这里的加法是模 p)。更难的是乘法:与数字不同,没有自然的方法将两个长度为 n 的向量相乘成另一个长度为 n 的向量。我们能做的最好的方法是外积:一个包含所有可能对的乘积的向量,其中第一个元素来自第一个向量,第二个元素来自第二个向量。即,a ⊗ b = a1b1 + a2b1 + ... + anb1 + a1b2 + ... + anb2 + ... + anbn。我们可以使用方便的数学恒等式 <a ⊗ b, c ⊗ d> = <a, c> * <b, d> 来“相乘密文”。
给定两个密文 c1 和 c2,我们计算外积 c1 ⊗ c2。如果 c1 和 c2 都是用 k 加密的,那么 <c1, k> = 2e1 + m1 且 <c2, k> = 2e2 + m2。外积 c1 ⊗ c2 可以被视为 m1 * m2 在 k ⊗ k 下的加密;我们可以通过尝试用 k ⊗ k 解密来看到这一点:
<c1 ⊗ c2, k ⊗ k> = <c1, k> * <c2, k> = (2e1 + m1) * (2e2 + m2) = 2(e1m2 + e2m1 + 2e1e2) + m1m2所以这种外积方法是有效的。但你可能已经注意到,有一个问题:密文和密钥的大小以平方级增长。
重新线性化
我们通过重新线性化过程来解决这个问题。私钥 k 的持有者作为公钥的一部分提供了一个“重新线性化密钥”,你可以将其视为 k ⊗ k 在 k 下的“噪声”加密。我们的想法是,我们向执行计算的人提供这些加密的 k ⊗ k 片段,允许他们计算方程 <c1 ⊗ c2, k ⊗ k> 以“解密
- 原文链接: vitalik.eth.limo/general...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





