探索Circle STARK技术
- Vitalik Buterin
- 发布于 2024-07-25 14:25
- 阅读 1632
本文深入探讨了Circle STARKs的工作原理及其在零知识证明中的应用,特别是在小字段上的优化和效率提升。
探索 Circle STARKs
探索 Circle STARKs
本文假设读者熟悉 SNARK 和 STARK 的基本工作原理;如果不熟悉,推荐先阅读这篇文章的前几部分。特别感谢 Eli ben-Sasson、Shahar Papini、Avihu Levy 和 Starkware 的其他成员提供的反馈和讨论。
过去两年中,STARK 协议设计最重要的趋势是转向小字段(small fields)。最早的 STARK 生产实现使用 256 位字段 —— 算术模大数如 21888...95617 ≈1.51∗2253 ,这使得这些协议天然兼容基于椭圆曲线的签名验证,并且易于推理。但这导致了低效:在大多数情况下,我们实际上无法充分利用这些大数,因此它们最终成为空间浪费,甚至更大的计算浪费,因为处理 4 倍大的数的算术需要约 9 倍的计算时间。为了解决这个问题,STARK 开始使用更小的字段:首先是 Goldilocks(模数 264−232+1),然后是 Mersenne31 和 BabyBear(分别为 231−1 和 231−227+1)。
这一转变已显著提升了证明速度,最引人注目的是 Starkware 在 M3 笔记本电脑上能够每秒证明 620,000 次 Poseidon2 哈希。特别是,这意味着如果我们愿意信任 Poseidon2 作为哈希函数,那么构建高效 ZK-EVM 最困难的部分之一实际上已经解决。但这些技术如何运作?通常需要大数来保障安全的密码学证明如何在这些小字段上构建?与更奇特的构造如 Binius 相比,这些协议如何?本文将探讨其中一些细节,特别关注称为 Circle STARKs 的构造(已在 Starkware 的 stwo、Polygon 的 plonky3 和我的 Python 实现中应用),它具有一些独特属性,旨在与高效的 Mersenne31 字段兼容。
小字段的共性问题
基于哈希的证明(或任何类型的证明)最重要的“技巧”之一是:通过证明多项式在随机点的求值来代替对底层多项式的证明。
例如,假设证明系统要求你生成对多项式 A 的承诺,且 A 必须满足 A3(x)+x−A(ω∗x)=xN(ZK-SNARK 协议中常见的证明类型)。协议可以要求你选择一个随机坐标 r,并证明 A(r)+r−A(ω∗r)=rN。接着,为了证明 A(r)=c,你需要证明 Q=A−cX−r 是一个多项式(而非分式表达式)。
如果提前知道 r,你总是可以欺骗这些协议。例如,你可以将 A(r) 设为零,调整 A(ω∗r) 以满足等式,然后让 A 成为通过这两点的直线。类似地,在第二步中,如果提前知道 r,你可以生成任意 Q,然后调整 A 来匹配它,即使 A 是分式(或其他非多项式表达式)。
为了防止这些攻击,我们需要在攻击者提供 A 之后选择 r("Fiat-Shamir 启发式" 就是将 r 设为 A 的哈希值)。关键的是,我们需要从足够大的集合中选择 r,使得攻击者无法猜测它。
在基于椭圆曲线的协议和 2019 年代的 STARK 中,这很简单:所有数学运算都在 256 位数上进行,因此我们选择 r 作为随机 256 位数即可。但在小字段的 STARK 中,我们面临问题:r 的可能取值只有约 20 亿个,攻击者只需尝试 20 亿次即可伪造证明 —— 虽然工作量巨大,但对有决心的攻击者来说是可实现的!
对此有两种自然解决方案:
- 多次随机检查
- 扩展字段
多次随机检查的方法直观且简单:不在一个坐标点检查,而是在四个随机坐标点重复检查。理论上可行,但存在效率问题。如果在大小为 p 的字段上处理次数 < N 的多项式,攻击者可能构造在 N 个位置上“看似”良好的坏多项式。因此,他们单次攻破协议的概率为 N/p。例如,若 p=231−1 且 N=224,攻击者每轮仅有 7 位安全性,因此需要约 18 轮而非 4 轮才能充分防御。理想情况下,我们希望做 k 倍工作但仅从安全级别中减去 N 一次。
这引出了另一种方案:扩展字段。扩展字段类似于有限域上的复数:我们引入一个新值 i,并定义 i2=−1。乘法变为:(a+bi)∗(c+di)=(ac−bd)+(ad+bc)i。我们现在可以操作数对 (a,b) 而非单个数字。假设我们使用 Mersenne 或 BabyBear 等 ≈231 大小的字段,r 的选择范围将扩展到 ≈262。为了进一步扩展,我们再次应用相同技术:在 Mersenne31 中,我们选择 w 满足 w2=−2i−1。此时的乘法变为 (a+bi+cw+diw)∗(e+fi+gw+hiw)=...

现在,r 的可选值达到 ≈2124,足以满足安全需求:若处理次数 < 220 的多项式,单轮可获得 104 位安全性。若需达到更严格的 128 位安全级别,可在协议中添加工作量证明。
注意,扩展字段仅用于 FRI 协议和其他需要随机线性组合的场景。大部分数学运算仍在“基字段”(模 231−1 或 15∗227+1)上进行,且哈希数据多为基字段值,因此每个值仅哈希四字节。这让我们既能享受小字段的效率,又能在需要时使用大字段保障安全。
常规 FRI
构建 SNARK 或 STARK 时,第一步通常是算术化:将任意计算问题转化为变量和系数为多项式的方程(例如,方程常形如 C(T(x),T(next(x)))=Z(x)∗H(x),其中 C、next 和 Z 已知,求解者需提供 T 和 H)。方程的解即对应原计算问题的解。
为了证明解存在,需证明所提出的值确实是多项式(而非分式或在某处表现为不同多项式的数据集等),且次数不超过上限。为此,我们迭代应用随机线性组合技巧:
- 假设有多项式 A 的求值,需证明其次数 <220
- 构造多项式 B(x2)=A(x)+A(−x) 和 C(x2)=A(x)−A(−x)x
- 令 D 为随机线性组合 B+rC
本质上,B 提取了 A 的偶次项系数,C 提取了奇次项系数。根据 B 和 C 可恢复 A:A(x)=B(x2)+xC(x2)。若 A 的次数确实 <220,则 (i) B 和 C 的次数 <219。而作为随机线性组合,D 的次数也必须 <219。
我们将“证明次数 <220”的问题简化为“证明次数 <219”。重复此过程 20 次,即得到称为快速里德-所罗门交互式预言邻近证明(FRI)的技术。若尝试传入非次数 <220 的多项式,则第二轮输出(概率≈1−12124)将不是次数 <219 的多项式,后续检查将失败。在多数位置等于次数 <220 多项式但略有缺陷的数据集可能通过,但构造此类数据集需知悉底层多项式,因此这种轻微缺陷的证明仍能表明证明者可以生成“真实”证明。过去五年,学术 STARK 研究的重点之一是验证此方法对所有输入的鲁棒性。
深入分析,此过程需要哪些属性?每一步都将次数减半,并将域(所考察的点集)减半。前者是 FRI 的核心,后者则使其高效:每轮规模减半,总成本为 O(N) 而非 O(N∗log(N))。
为此,我们需要二对一映射:{x,−x}→x2。这种映射的优点是可重复:若从乘法子群(集合 {1,ω,ω2...ωn−1})开始,则对任何 x,−x 也在集合中(若 x=ωk,则 −x=ωk±N2),平方后得到 {1,(ω2),(ω2)2...(ω2)n2−1},同样具有此性质,因此可一直缩减到单个值(实践中通常提前停止)。
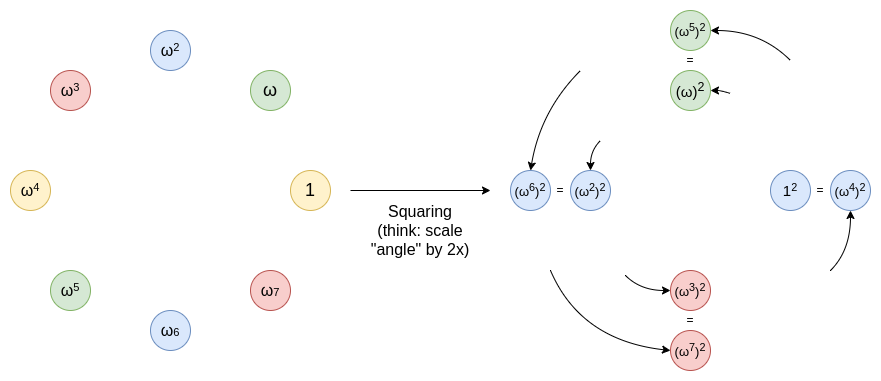
这类似于将绕圆环的线拉伸为两圈。0...179 度的点与 180...359 度的点重叠。此过程可重复。
为此,原始乘法子群的规模需包含 2 的高次幂。BabyBear 的模数为 15∗227+1,最大子群为所有非零值(规模 15∗227),非常适合此技术。可选取 227 规模的子群,或使用完整集合并将多项式缩减到次数 15 后直接检查。但 Mersenne31 的模数为 231−1,乘法子群规模为 231−2,仅能被 2 除一次,无法使用上述技术进行 FFT。
这十分遗憾,因为 Mersenne31 能通过现有 32 位 CPU/GPU 运算高效实现算术。加法运算结果可能超过 231−1,但可通过 x→x+(x>>31) 缩减。乘法运算类似,但需使用特殊指令获取结果的高位(即 floor(xy232))。这使得运算效率比 BabyBear 高约 1.3 倍。若能在 Mersenne31 上实现 FRI,将显著提升效率。
Circle FRI
这正是 Circle STARKs 的巧妙之处。给定素数 p,我们可以轻松获得规模为 p+1 且具有类似二对一性质的群:满足 x2+y2=1 的点 (x,y)。以模 31 为例:
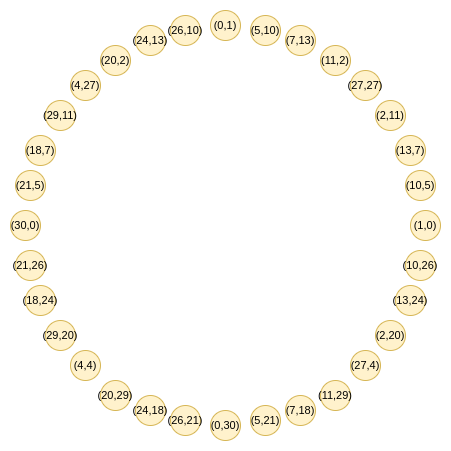
(x1,y1)+(x2,y2)=(x1x2−y1y2,x1y2+x2y1)
倍点公式为:
2∗(x,y)=(2x2−1,2xy)
现在,我们仅关注圆上“奇数”位置的点:
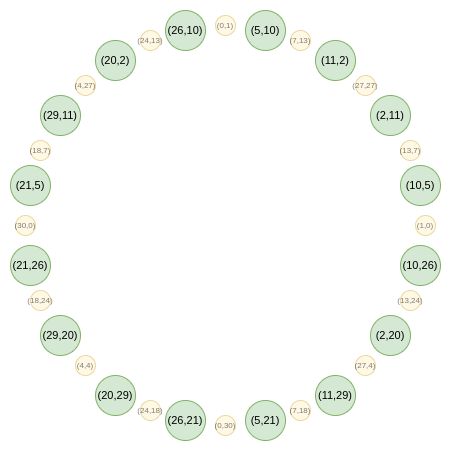
以下是我们的 FFT。首先,将所有点折叠到一条线上。常规 FRI 中的 B(x2) 和 C(x2) 公式在此对应:
f0(x)=F(x,y)+F(x,−y)2
f1(x)=F(x,y)−F(x,−y)2y
然后取随机线性组合,得到一维 F,其定义在 x 线的子集上:
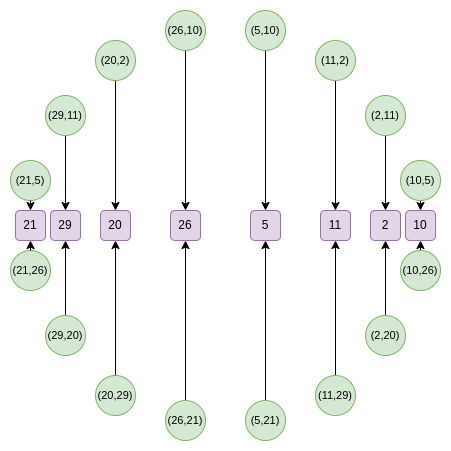
从第二轮开始,映射变为:
f0(2x2−1)=F(x)+F(−x)2
f1(2x2−1)=F(x)−F(−x)2x
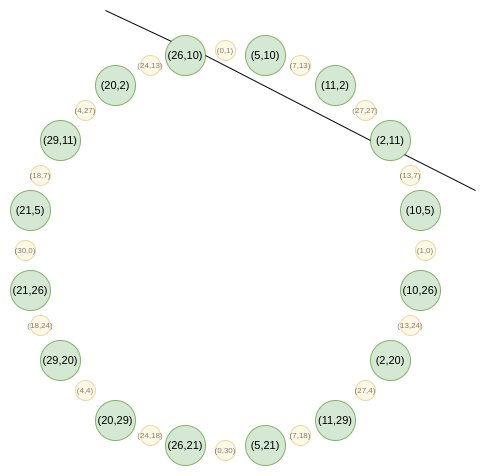
此映射将上述集合规模逐轮减半!这里,每个 x 实际上“代表”两个点:(x,y) 和 (x,−y)。而 x→2x2−1 是上述倍点法则。因此,我们将圆上两个对称点的 x 坐标转换为倍点的 x 坐标。
例如,对第二个最右侧的值 2 应用映射得到 2(22)−1=7。回到原圆环,(2,11) 是从右开始逆时针的第三个点,加倍后得到第六个点 (7,13)。
这可以二维实现,但一维运算更高效。
Circle FFT
与 FRI 密切相关的算法是快速傅里叶变换(FFT),它将次数 <n 多项式的 n 个求值转换为多项式的 n 个系数。FFT 遵循与 FRI 相同的路径,但在每步中不是生成随机线性组合 f0 和 f1,而是递归地对两者应用半长 FFT,并将 FFT(f0) 的输出作为偶次项系数,FFT(f1) 作为奇次项系数。
圆群也支持 FFT,其构造与 FRI 类似。但关键区别在于,Circle FFT(和 Circle FRI)处理的对象在技术上并非多项式。它们是数学家所称的 Riemann-Roch 空间:此处为模圆 (x2+y2−1=0) 的“多项式”。即,我们将 x2+y2−1 的倍数视为零。另一种理解是:只允许 y 的一次项,遇到 y2 时替换为 1−x2。
此外,Circle FFT 输出的“系数”并非常规 FRI 中的单项式(例如常规 FRI 输出 [6,2,8,3] 表示 P(x)=3x3+8x2+2x+6),而是特定于 Circle FFT 的奇异基:
{1,y,x,xy,2x2−1,2x2y−y,2x3−x,2x3y−xy,8x4−8x2+1...}
好消息是开发者几乎无需关心这些。STARK 不要求知道系数,只需将“多项式”存储为特定域上的求值集合。唯一需要 FFT 的场景是执行低度扩展:给定 N 个值,生成同一多项式上的 k∗N 个值。此时,可执行 FFT 生成系数,追加 (k−1)n 个零,再执行逆 FFT 得到更大的求值集合。
Circle FFT 并非唯一的“异域 FFT”。椭圆曲线 FFT 更强大,因其适用于任何有限域(素数域、二元域等)。但 ECFFT 更复杂且低效,因此我们在 p=231−1 时使用 Circle FFT。
接下来,探讨实现 Circle STARKs 时与常规 STARKs 的不同细节。
商式处理
STARK 协议中常见操作是在特定点(随机或固定)取商式。例如,若需证明 P(x)=y,可通过 Q=P−yX−x 并证明 Q 是多项式(而非分式)。随机选择求值点用于 DEEP-FRI 协议,以更少的 Merkle 分支确保 FRI 安全。
此处存在微妙挑战:在圆群中,没有类似于常规 FRI 中 X−x 的单点线性函数。几何上可见:
可构造与单点 (Px,Py) 相切的线性函数,但该函数会“以重数 2”通过该点 —— 即多项式必须满足更严格条件才能成为该线性函数的倍数。因此,无法仅在一个点证明求值。解决方案是:在两个点进行证明,并添加一个不关心的虚拟点。

若多项式 P 在 P1 处为 v1,在 P2 处为 v2,则选择插值函数 I:在 P1 为 v1,P2 为 v2 的线性函数。例如 v1+(v2−v1)∗y−y1(P2)y−(P1)y。通过减去 I(使 P−I 在两点为零),除以 L(P1 和 P2 间的线性函数),并证明商式 P−IL 为多项式,即可完成证明。
消失多项式
在 STARK 中,待证明的多项式方程通常形如 C(P(x),P(next(x)))=Z(x)∗H(x),其中 Z(x) 是在整个原始求值域上为零的多项式。常规 STARK 中,Z(x)=xn−1。Circle STARK 中,对应函数为:
Z1(x,y)=y
Z2(x,y)=x
Zn+1(x,y)=(2∗Zn(x,y)2)−1
注意,消失多项式可从折叠函数推导:常规 STARK 中重复 x→x2,此处重复 x→2x2−1,但首轮处理不同。
逆比特序
STARK 中,多项式求值通常不按“自然”顺序(P(1), P(ω), P(ω2)...P(ωn−1)),而是采用逆比特序:
P(1), P(ωn2), P(ωn4), P(ω
- 翻译
- 学分: 0
- 分类: 密码学
- 标签: STARKs Circle STARKs 零知识证明 小字段 FRI Mersenne31





