探索加密数据 III:数据堆栈
- 2077 Research
- 发布于 2024-05-23 21:15
- 阅读 1506
本文探讨了三种数据管理策略,分别是精益栈、索引引擎(子图)和数据湖,强调它们在区块链数据处理中的独特优势和适用场景。随着数据处理和分析需求的增加,这些方法有助于组织优化数据工作流,以满足特定的业务目标和需求。
这篇文章是关于加密数据系列的一部分。你可以在这里找到第一部分:第一部分 - 理解数据流架构和第二部分:第二部分:外包数据类型
在不断发展的数据处理和分析领域,针对特定用例进行优化至关重要。随着组织面对大量数据,建立精简、高效和有目的性的数据管理系统的需求变得越来越迫切。本文深入探讨了三种不同的数据处理方法,每种方法都提供了独特的优势,并适用于不同的需求。结合在前一篇文章中讨论的外包数据提取,这些数据管理系统将帮助你使数据工作流程与特定目标和需求保持一致。
精益堆栈 代表了一种优化的方法,旨在通过精简的请求管道、解码过程和转换引擎仅传递必要的度量标准。通过最小化不必要的数据提取和处理,这种方法确保了效率,但高度依赖于其初步设计,因此在应对不断变化的需求时灵活性较低。
索引引擎或子图 提供了一种标准化的方式来结构化和查询区块链数据,允许在多个应用程序中实现更大的灵活性和重用。通过使用预定义的规则和用户定义的脚本,这些引擎将原始数据转化为可以通过 GraphQL API 访问的结构化实体,使其非常适合需要频繁和多样化数据查询的应用程序。
另一方面,数据湖 采用 ELT(提取,加载,转化)方法,强调存储大量原始数据以便后续分析和转换。这种方法的特点是具有探索能力,允许用户深入分析广泛的数据集,过滤相关信息,并建模数据以得出有意义的洞察。
这些数据管理策略各自满足独特需求,提供不同的优势和权衡。 本章深入探讨每种方法的工作原理、优点和用例,帮助你了解如何使数据工作流程与特定目标和要求保持一致。
精益堆栈
它是什么? - 精益堆栈是一种请求管道、解码过程和转换引擎精心设计的方法,仅提供所需的度量标准,不进行额外的数据处理或存储。它是最不灵活的方法,因为该堆栈专门为处理其最初设计的数据而定制,而不包括其他内容。
从概念上讲,精益堆栈高度可定制,能够使用任意语言。它遵循经典的 ETL(提取、转换、加载)过程,仅提取必要的数据而不产生多余的数据。该方法消除了超出所需输出度量标准的广泛数据存储或处理,使系统高度高效且“精益”。
在此配置中,系统流程通常共享相同的基础设施,模糊数据流每个阶段之间的界限(在系列的第一部分中探讨)。例如,在需要解码时,ABI 被作为源数据输入,相同的引擎管理将原始数据转化为可读参数,并执行必要的转换,所有这些过程都在一个集成的流程中完成。精益堆栈还可以利用“按需节点”解决方案,使用 NaaS API 与之交互,而不是直接进行节点 RPC 调用。
尽管如此,我们所称的精益堆栈,可能是一个非常复杂的系统。它可以将工作流程细分为不同步骤,为每个阶段部署不同的解决方案,并在需要优化时存储中间数据。然而,它的主要优势仍在于其流线型、目标导向的设计,专注于以最小的开销产生所需的度量标准。
索引引擎(子图)
它是什么? 索引引擎提供了一种标准化的方式来管理数据流,使其能够在各种输出和应用程序中重用。通过预先定义这些流,数据处理可以外包给第三方,只要他们实现所需的堆栈即可。
使用索引引擎的主要优势是将操作外包给“索引器”,由其维护索引服务,保持其在线和运行。这种方法对小团队特别有吸引力,因为它消除了任何专用数据基础设施的需求,这类似于“索引数据提供商”的外包(在系列的第二部分中讨论)。在这种情况下,堆栈是指索引器使用的系统,而不是最终数据用户的系统。
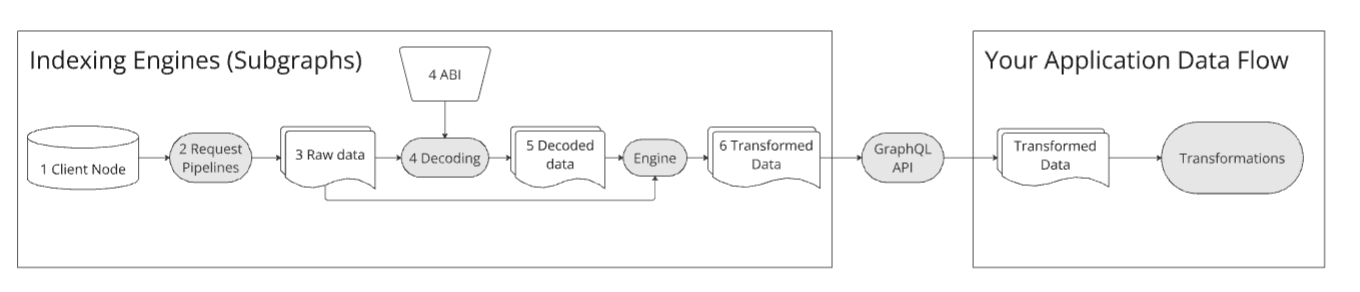
索引引擎的流程类似于“索引数据提供商”。但是,不同于提供者定义规定输出的代码,索引引擎的用户创建自己的代码脚本来定义所需的输出,并遵循特定的子图规范。处理后的数据通过 GraphQL API 进行访问,因为用户通常不直接管理引擎。
子图 本质上是一组旨在生成特定输出的代码脚本。它由多个组件共同工作:
- 清单 包含有关数据源、模板和一些子图元数据(例如描述、存储库等)。清单定义将由子图进行索引的合约、相关事件和函数调用,以及如何将原始数据转化为将被存储并稍后交付给用户的实体。
- 架构 定义子图输出数据的结构,并详细说明如何使用 GraphQL 进行查询。它包括实体定义,并指定每个实体的结构化数据。
- AssemblyScripts 映射 是在特定事件发生时执行的脚本,如清单中详细说明。这些映射定义了事件处理程序,用于转化来自事件或函数调用的输入数据,随后将处理的数据存储在 Graph 节点存储中。
示例 : The Graph, Alchemy, Sentio, Ponder, Subsquid (Solana)。
数据湖
它是什么? 数据湖堆栈采用 ELT(提取,加载,转化)过程,区别于在精益堆栈和索引引擎中看到的 ETL 方法。该堆栈利用数据仓库来存储大量的原始和解码数据,其中许多数据可能不会立即被使用。它提供了请求管道、解码、存储和转换等过程之间的明确分离。可以将原始和解码的流媒体外包,绕过需要在内部处理请求和解码过程的需求。
由于使用了数据仓库,SQL 通常是数据转换的首选语言。使用数据湖堆栈生成度量的过程包括以下步骤:
- 探索:鉴于数据湖包含比严格必要更多的数据,初步步驟是探索并识别与所需输出相关的合约和事件。所有数据均可轻松访问,你可以直接调查参数,无需查阅项目文档。
- 过滤:数据湖通常使用广泛的、统一的模式存储类似数据类型的数据。过滤涉及缩小这些庞大数据集,仅包括协议所需的特定合约和函数。此步骤旨在将数据集大小最小化,以降低计算成本,过滤是根据需要执行的,仅针对将要使用的数据。
- 建模:此阶段涉及利用来自多种源的数据创建你的协议模型,包括原始数据、解码数据、离线数据和定制导入的数据。根据需要可以生成多个模型,并保存的转化可以用于稍后的聚合,从而进行全面和灵活的数据分析。
示例:Allium, Flipside, Dune, Chainbase, Zettablock, Transpose
在线 SQL
最后,我们强调在线 SQL 工具,尽管它本身不是一种堆栈,但在分析和利用区块链网络生成的大量数据方面已变得至关重要。
它是什么? - 在线 SQL 工具为使用数据湖堆栈的过程提供必要的基础设施,这对于普通用户来说既昂贵又繁琐。这些平台使用户能够分析、转换和创建区块链数据的度量,作为后端过程,并提供可视化工具和仪表板等附加功能以展示洞察。
它如何工作? - 用户通过提供访问基础数据仓库的在线界面进行交互。通过 SQL 查询,用户可以转换和组合可用数据,以得出有意义的度量。该平台处理数据摄取和存储,用户提交的查询通常会成为平台的知识产权。这些工具管理某些查询的物化,形成转化数据表,以便于高效的访问和分析。提供商通常通过多种渠道获利,包括出售 API 访问、计算服务和提供优质数据访问。
示例:Flipside, Dune, Chainbase, Zettablock, Transpose
结论
在多样的加密数据世界中,找到一个纯粹堆栈的方式严格遵循所展示的类型是很少见的。大多数数据提供商和组织采用混合方法,结合这些解决方案以满足具体需求。这通常包括混合不同堆栈和外包各种数据流程,以优化其业务提案、可扩展性和成本效益。能够融合这些方法的灵活性使数据参与者能够定制他们的系统,以确保能够适应区块链领域不断变化的需求,并在各种应用程序中提供准确、可靠的洞察。
- 原文链接: research.2077.xyz/explor...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





