算术化 II
- starkware
- 发布于 2020-09-03 14:42
- 阅读 1437
本文是STARK数学系列的第三篇,深入探讨了如何通过多项式约束的组合,从执行轨迹中构造低度多项式,并展示其在验证过程中的应用。作者介绍了误差纠正码在提高验证器查询效率中的作用,并通过简单的布尔执行轨迹和斐波那契数列示例说明了相关原理,最后讨论了多列多约束情况的处理。文章在理论和实践中都有深度和详实的分析,是理解STARKs的重要资源。
“我们需要更深入了解”
这是我们 STARK 数学系列的第三篇文章,如果你还没有阅读 第一篇 和 第二篇,我们建议你在继续阅读之前先阅读它们。温馨提示:这一篇的数学内容比前两篇要复杂一些。

照片由 Iswanto Arif 贡献,来源于 Unsplash
回顾
在 上一篇文章 中,我们介绍了算术化 — 将计算完整性(CI)语句转化为检查多项式是否低度的过程。这种转化使我们能够实现紧凑的验证,CI 语句的验证者所需的资源比简单重放所需的资源少得多。在上一篇文章中,我们通过将 CI 语句关于 Collatz 序列 的实例进行了详细说明,即如何转化为执行轨迹和一组多项式约束。在这一篇中,我们将进一步展示——使用 Fibonacci 序列 作为例子——证明者如何结合执行轨迹和多项式约束来获取一个多项式,只有当执行轨迹满足我们最初得到的多项式约束时,这个多项式才能保证是低度的。此外,我们还将展示多项式被考虑的域将如何允许验证者进行紧凑的评估。我们还简要讨论了差错纠正码在 STARKs 中的作用。
我们将假设对于有限群体、有限域上的多项式以及本系列之前的文章你有一定的了解。
查询与差错纠正码
请记住,我们的目标是让验证者能够对证明者询问非常少量的问题,并以保证的高精度来决定接受或拒绝证明。理想情况下,验证者希望向证明者询问执行轨迹中的几个(随机)位置的值,并检查在这些位置上多项式约束是否成立。正确的执行轨迹自然会通过这一测试。然而,构造一个完全错误的执行轨迹并不困难,该执行轨迹只在某一个位置违反约束,从而得出一个完全远离且不同的结果。通过少量随机查询识别这一错误是非常不可能的。
解决类似问题的常见技巧是 差错纠正码。
差错纠正码的作用是将一组字符串(其中一些可能彼此非常相似)转换为一组字符串,这些字符串在成对比较时非常不同,通过用更长的字符串替换原始字符串。
有趣的是,多项式可以用于构造良好的差错纠正码,因为在一个域上评估两个度为 d 的多项式时,如果该域的规模远大于 d,则几乎在所有地方都不同¹。这些代码被称为 Reed-Solomon 码。
观察到这一点后,我们可以通过将执行轨迹视为对某个多项式在某个域的评估来扩展它,然后在一个更大的域上评估同一个多项式。以类似的方式扩展一个 错误的 执行轨迹,会产生一个完全不同的字符串,这反过来使验证者能够通过少量的查询区分这些情况。
我们的计划因此是 1)将执行轨迹重新表述为多项式,2)将其扩展到一个大的域,3)使用多项式约束将其转换为另一个保证低度的多项式,如果且仅当执行轨迹有效时成立。
玩具示例:布尔执行轨迹
假设相关的 CI 语句是“证明者有一个包含 512 个数字的序列,这些数字都是 0 或 1”,我们希望通过读取远少于 512 个数字来验证这一点。让我们看看什么样的执行轨迹和多项式约束可以表示这个玩具示例:
- 执行轨迹有 512 行,每行包含一个单元,单元内为零或一。
- 我们在这里使用的多项式约束是简单的 Aᵢ ⋅ Aᵢ-Aᵢ=0,其中 Aᵢ 表示这个单列执行轨迹中的第 i 个单元(一个数字的平方等于它本身当且仅当它是 0 或 1)。
为了将此 执行轨迹 重新表述为多项式,我们指定将要操作的域 — 我们选择 Z₉₆₇₆₉,从整数集 0,1,…,96768 中得到,使用 96769 下的加法和乘法。接下来,我们选择 Z₉₆₇₆₉* 的一个子群 G(我们使用 F* 表示 F 的乘法群体²)使得 |G|=512,以及某个 g 的生成元³。由于 512 是这个组的大小(96768)因数,因此可以保证存在这样一个子群。
我们现在可以将执行轨迹中的元素视为某个度小于 512 的多项式 f(x) 的评估,具体的方式是,第 i 个单元包含了 f 对生成元 i 次幂的评估。
正式来说:

这样的多项式,度至多为 512,可以通过插值法计算,然后我们继续在更大的域上评估它⁴,形成 Reed-Solomon 码字的特殊案例。
最后,我们使用这个多项式再构造一个多项式,其低度特性依赖于在执行轨迹上约束的满足。
为了做到这一点,我们必须暂时改变方向,讨论多项式的根。
多项式的根
关于多项式及其根的一个基本事实是,如果 p(x) 是一个多项式,则 p(a)=0 对某个特定值 a 成立,当且仅当 存在一个多项式 q(x),使得 (x-a)q(x)=p(x),且 deg(p)=deg(q)+1。
而且,对于所有 x≠a 的情况,我们可以通过计算来评估 q(x):

通过归纳法,对于 k 个根也是类似的事实。也就是说,如果 aᵢ 是 p 的一个根,对于所有 i=0..k-1,那么存在一个度为 deg(p)-k 的多项式 q,并且在除这 k 个值外,q 恰好等于

综合起来
将多项式约束以 f 的形式重新表述,会得到以下多项式:

我们已定义 f,使得当且仅当执行轨迹中的单元是 0 或 1 时,这个表达式的根是 1, g, g², …, g⁵¹¹。我们可以定义:

我们知道从前面的段落中,有一个度至多为 2· deg(f)-512 的多项式,它在所有不属于{ 1, g, g², …, g⁵¹¹} 的 x 上与 p 一致,当且仅当 执行轨迹确实是一个 512 位的列表(即 0 或 1)。请注意,早些时候,证明者已经将执行轨迹扩展到更大的域,因此在 该 域中查询多项式值是合理的。
如果存在一种协议,证明者可以使验证者确信这个多项式是低度的,以至于验证者只询问执行轨迹外的值,那么实际上只有在 CI 语句为真时,验证者才能相信其真实性。实际上,在下一篇文章中,我们将展示一种恰好做到这一点的协议,其错误概率非常小。与此同时——让我们来看另一个例子,同样简单但不完全琐碎,看看在这种情况下如何减缩。
Fibonacci
我们接下来使用的示例是正确计算 Z₉₆₇₆₉ 中到第 512 位的 Fibonacci 序列。该序列正式定义为:

我们的主张(即 CI 语句)是 a₅₁₁=62215。
我们可以为这个 CI 语句创建一个 执行轨迹,只需写下所有 512 个数字:

我们使用的 多项式约束 是

转换为多项式
在这里,我们同样定义一个度至多为 512 的多项式 f(x),使得 执行轨迹 中的元素是在一些生成元 g 的幂上对 f 的评估。
正式来说:

将 多项式约束 表达为 f 而不是 A,我们得到:

由于多项式的组合仍然是多项式 — 将约束中的 Aᵢ 替换为 f(gⁱ) 仍然意味着这些是多项式约束。
请注意,1、2 和 4 是指单个 f 值的约束,我们称它们为 边界约束。
Fibonacci 递推关系,反之,体现了对整个执行轨迹的一组约束,它可以另行表述为:
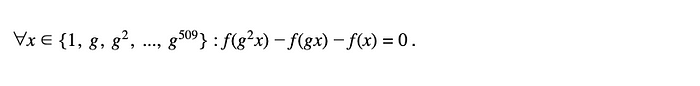
使用生成元来索引执行轨迹的行使我们可以将“下一行”的概念编码为一个简单的代数关系。如果 x 是执行轨迹中的某一行,则 gx 是下一行,g²x 是下一行,g⁻¹x 是上一行,以此类推。
递推关系多项式:f(g²x)-f(gx)-f(x) 对于每个索引执行轨迹的一行的 x 除最后两行外都是零。这意味着 1, g, g², …, g⁵⁰⁹ 都是这个递推关系多项式的根(且它的度至多为 510),因此我们可以构造 q(x) 如下:

在 STARK 传说中,这通常被称为 组合多项式。实际上,当原始执行轨迹遵循 Fibonacci 递推关系时,该表达式在除了这 510 个值以外的所有值上与某个度至多为 2 的多项式一致(请记住 f 的度至多为 512)。不过,组合 多项式 这个术语有些误导,因为当执行轨迹不满足多项式约束时 — 该表达式的评估在许多地方与 任何低度多项式 不同。换句话说,只有在原始 CI 正确时,它才接近于低度多项式,这的确是我们的目标。
这总结了所承诺的减缩过程,它将检查某些多项式约束在某个执行轨迹上是否得到满足的问题转化为检查某个已知于证明者的多项式是否为低度的问题。
紧凑性
拥有非常高效的验证技术是 STARKs 的关键,它可以看作由两个部分组成 — 使用少量的查询,并让验证者在每个查询上执行少量的计算。前者通过差错纠正码来实现,它允许在非常少的地方进行查询,而后者我们在整个帖子的前面部分对此进行了稍微的掩盖,直到现在。验证者的工作可以总结为 1)在随机位置查询组合多项式,2)根据这些查询检查低度特性。低度特性紧凑检查将在下一篇文章中处理,但我们究竟所说的“查询组合多项式”是什么意思?热衷的读者可能对这个表达有所怀疑,这是有道理的。毕竟,证明者可能是恶意的。当验证者询问组合多项式在某个 x 处的评估时,证明者可能会回复某个真正的低度多项式的评估,这将通过任何低度测试,但并不是 组合多项式。
为防止这种情况,验证者明确在某行 w 上查询 Fibonacci 执行轨迹,通过询问三个位置的 f 值:f(w), f(gw), f(g²w)。
现在,验证者可以通过以下方式计算 w 上组合多项式的值:

其中,分子可以使用从证明者获得的值计算,而分母... 好吧,这就是复杂之处(之前被掩盖起来了)。
一方面,分母与执行轨迹完全无关,因此验证者可以在与证明者通信之前计算它。
另一方面,在实际上 — 执行轨迹可能包含数十万行,计算分母将导致验证者花费大量的运行时间。
在此,算术化对紧凑性至关重要 — 因为计算这一表达在 g 的幂形成子群时可以非常高效地完成,如果我们注意到:

这个等式成立,因为两侧的多项式的根恰好是 G 的元素。
计算该方程右侧似乎需要的操作数是与 |G| 成正比的 线性 运算。然而,如果我们采用 快速幂 方法,该方程的左侧可以在保证运行时间与 |G| 的 对数 成比例的情况下计算。
而所讨论 Fibonacci 组合多项式的实际分母可以通过将其改写为:
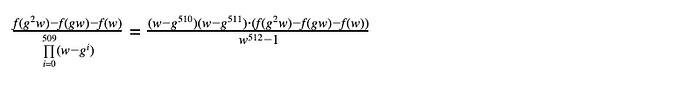
这个似乎的技术细节正是验证者能够在多对数时间内运行的核心,而这仅仅是因为我们将执行轨迹视作对某个域的子群的多项式评估,并且所涉及的多项式约束在该子群上成立。
类似的技巧可以用于更复杂的执行轨迹,但至关重要的是,约束的重复模式与领域的某个子群相一致。
更多约束,更多列!
本文中的例子故意简单,以突出算术化的核心方面。自然会产生的问题是:如何处理多列和多约束的情况。答案很简单:多列仅意味着有多个多项式可供操作,而多个组合多项式 — 由多个约束导致的 — 会结合为一个多项式,即所有多项式的随机线性组合,以便于 STARK 最后阶段的低度测试。以高概率,线性组合的低度性当且仅当其所有组成部分都具备低度性。
总结
我们展示了如何在给定执行轨迹和约束多项式的情况下,证明者可以构造一个多项式,当且仅当原始 CI 语句成立时,该多项式才是低度的。此外,我们还展示了验证者如何有效地查询该多项式的值,确保证明者没有将真正的多项式替换为某个假低度多项式。
在下一篇文章中,我们将详细探讨低度测试,展示如何实现查询少量值以及确定某个多项式是否为低度的魔法。
谢尔·佩莱德
StarkWare
¹ 要看到这一点,请注意不同度 d 的多项式之间的差异是一个非零的度 d 多项式,因此最多有 d 个零。
² 提醒:乘法群是通过从域中省略零元素获得的。
³ 生成元是子群中的一个元素,其幂张成整个子群。
⁴ 选择该域的大小直接影响到可靠性错误,域越大 — 可靠性错误越小。
⁵ 确保验证者相信当且仅当证明者没有作弊时。
- 原文链接: medium.com/starkware/ari...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





