在RISC Zero中验证全同态加密(FHE),第一部分
- L2IV
- 发布于 2023-11-17 14:52
- 阅读 2194
本文探讨了使用零知识证明(ZKP)验证全同态加密(FHE)的过程,重点分析了TFHE在RISC Zero平台上的实现,以及如何通过优化数据加载和计算来提高效率。文章呈现了核心概念、实施细节和代码示例,为后续优化提供基础。
我们最近研究了如何使用零知识证明(ZKP)来验证全同态加密(FHE),因为这在两个新兴用例中至关重要。
-
fhEVM 的链下计算: Fhenix 和 Inco 正在开发 L1 链,它们通过基于 Zama 的 fhEVM 对 EVM 进行完善的同态加密扩展,fhEVM 代表全同态以太坊虚拟机(EVM)。链下计算可以节省验证者重新运行 FHE 计算的需求(可扩展性),并可能进一步隐藏函数(隐私)。
-
FHE 挖矿: 受 Aleo 的简洁工作证明(PoSW)和 ZPrize 计划的启发,我们认为 FHE 挖矿是一个值得关注的未来方向,以激励 FHE 的 ASIC 制造并鼓励 FHE 挖矿者成为 fhEVM 网络的验证者。FHE 挖矿的核心任务是在 FHE 背景下为 PoSW 开发一个 ZKP 系统。
在不同的 FHE 方案中,我们对 Zama 使用的 TFHE 特别感兴趣。此 TFHE 实现使用的模数为 p = 2^64,因其在现代 CPU 和其他硬件平台上的计算效率而被选择。我们对在此背景下验证 FHE 的兴趣源于其在 fhEVM 中的即时适用性。
然而,采用模数 $p = 2^{64}$ 给 ZKP 带来了重大挑战,因为目前兼容该模数的零知识证明系统有限。
-
大多数零知识证明系统的设计都是在域内运行的,但模数 p = 2^64 不能构成一个域,正如 2 缺乏模逆的例子所示,这使得它只是一个环。我们有一个为环设计的零知识证明系统,名为 Rinocchio,但它在这里不起作用,因为它仅支持(1)任意环,如果 ZKP 是指定验证者,这不适合区块链应用和(2)与安全、复合阶的配对友好曲线相关的环,这将与 p = 2^64 不兼容。
-
另一种选择是使用一个适合的域来模拟 64 位整数计算,尽管这也带来了一套成本。目前只有少数虚拟机设计为支持 64 位整数,包括 RISC Zero 和 Aleo 的 Leo。还可以通过将 32 位整数模拟成 64 位整数,从而扩大虚拟机支持的选择,包括像 Polygon Miden 这样的平台(例如,参见 这个 Miden 汇编文件)和 Valida。
我们选择 RISC Zero 有三个原因。
-
工具链和开发生态系统特别成熟和稳定。
-
在 RISC Zero 上生成证明的性能,尤其在使用 Apple M2 芯片时,令人印象深刻。
-
我们恰好拥有一个极为珍贵且有限的 Bonsai API 密钥,允许我们将证明生成过程转移到 RISC Zero 的专用 Bonsai 服务器,从而减轻了本地证明生成的需求。
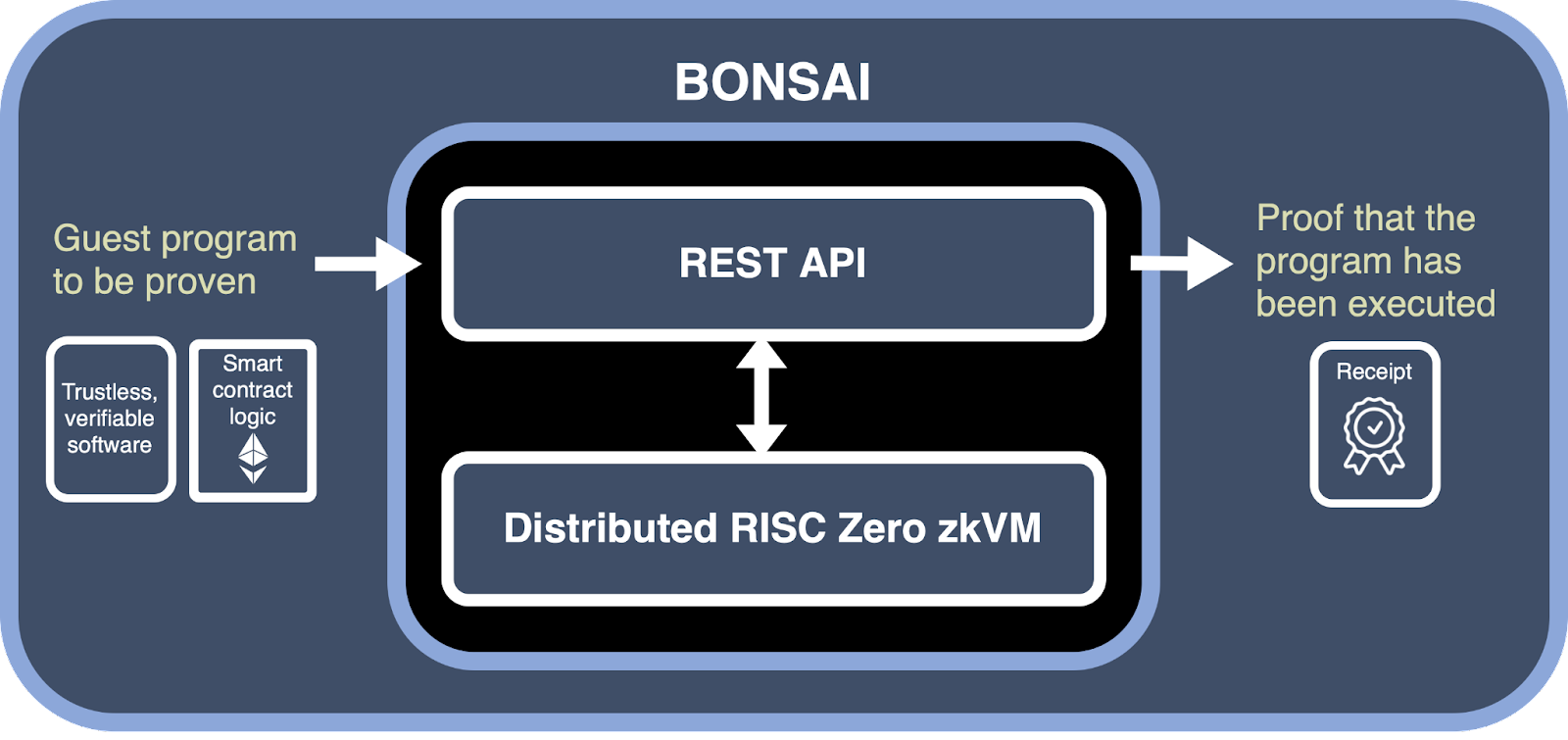
图 1:RISC Zero 的 Bonsai 委托证明生成服务。
本文的第一部分将记录我们实现一个功能性但未经优化的原型的历程。在后续文章中,我们将深入探讨我们优化实现的努力。此外,我们还将探索在与 RISC Zero 开发者的深入交谈中获得的各种未来方向。
什么是 TFHE?
要理解 TFHE,首先必须掌握全同态加密(FHE)的概念。FHE 的核心是一种加密算法,记作 E,用于数据加密。例如,给定明文 a,加密将给我们密文 E(a) 。
a→E(a)
全同态的意思是我们可以在密文上进行计算,包括加法、减法和乘法。
加法:E(a),E(b)→E(a+b)
减法:E(a),E(b)→E(a−b)
乘法:E(a),E(b)→E(a×b)
当明文为二进制比特(0 和 1)时,可以使用 FHE 代表所有的二进制逻辑门。这包括像 XOR 和 AND 这样的基本门,因为它们构成了在 FHE 中任何二进制逻辑运算的基础。
XOR:E(a),E(b)→E(a+b−a×b)
AND:E(a),E(b)→E(a×b)
鉴于其能够表示所有二进制门,FHE 因此能够在有限大小内执行任意计算。在区块链应用中,由于能够在去中心化金融(DeFi)应用中实现隐私,FHE 正越来越受到关注。例如,在隐私增强的去中心化交易所(DEX)中,FHE 可以在自动化做市商(AMM)中机密地处理计算。
FHE 的计算开销主要来自管理和减少“噪声”。所有现有的 FHE 构造都依赖于带有错误的学习假设(LWE)或其变体,这些构成了这些密码系统的基础。对于计算的每一步,输出——例如 E(a + b - a × b)——将比输入 E(a) 和 E(b) 具有更多的噪声,而这个输出可能成为后续步骤的输入。随着计算的进展,密文会积累越来越大的噪声。如图 2 所示,一旦密文中的噪声达到某个阈值,就会使得密文无法解密。
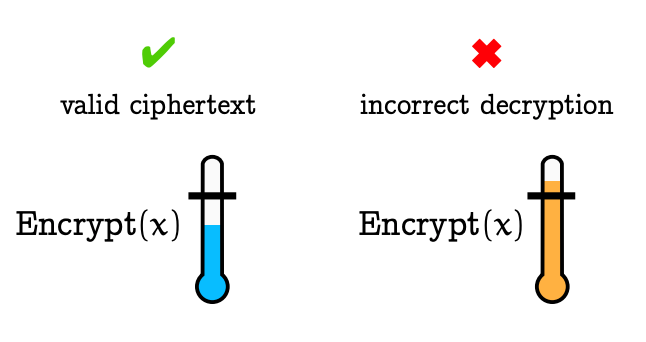
图 2:FHE 中噪声的示意图,摘自 Marc Joye (Zama) 的 论文。
为了实现 FHE 中的无界计算,必须找到一种在噪声变得过大之前消除噪声的方法。这种技术被称为“引导”(bootstrapping),它由 Craig Gentry 在 2009 年通过其开创性的 FHE 论文首次提出。引导的过程涉及使用加密版本的 FHE 秘钥,通常称为“引导密钥”,对噪声密文进行解密并刷新,从而产生一个新的密文,该密文包含相同的数据,但噪声更少。
可以想象,FHE 的计算就像是对密文进行一场非常耗费精力的运动——就像马拉松,而密文需要停下来以避免“过度疲劳”,我们在图 3 中对此进行了说明。

图 3:将 FHE 的引导过程视为一个人需要在马拉松中休息以避免过度疲劳(插图由 Midjourney 制作)。
在不同的全同态加密(FHE)算法中,TFHE 引起了广泛关注,因为 TFHE 中的引导效率高,并且 TFHE 非常适合对加密数据进行布尔电路评估。Zama、Fhenix 和 Inco 都在使用 TFHE。
因此,验证 FHE 的一个主要挑战在于准确验证引导过程。在 TFHE 中,引导涉及使用引导密钥“盲转”(blind rotate)一个多项式,以与正在引导的密文一致,随后从这个旋转的多项式中提取出一个刷新的密文。
尽管这开始看起来像是高级密码学的探讨,但令人欣慰的是,整个过程主要围绕多项式和矩阵的操作展开,如图 4 所示,摘自 Marc Joye 的 入门。对于希望深入了解的读者,我们强烈推荐 Marc Joye 关于 TFHE 的这一入门,适合那些仅具有基础线性代数知识的人。

图 4:来自 Marc Joye 的 入门 中 TFHE 引导算法的总结。
现在我们对 FHE 有了一些基本背景,让我们看看 RISC Zero 在这里是如何有用的。
什么是 RISC Zero?
RISC Zero 是一个多功能的零知识证明系统,专为 RISC-V 架构设计。换句话说,任何可以编译为ELF(可执行和链接格式)程序的程序,若是针对 riscv32im(带有“M”扩展以进行整数乘法和除法的 RISC-V 32 位)都是兼容的。在虚拟机执行时,RISC Zero 会生成此执行的零知识证明,称为“收据”。图 5 说明了此过程。
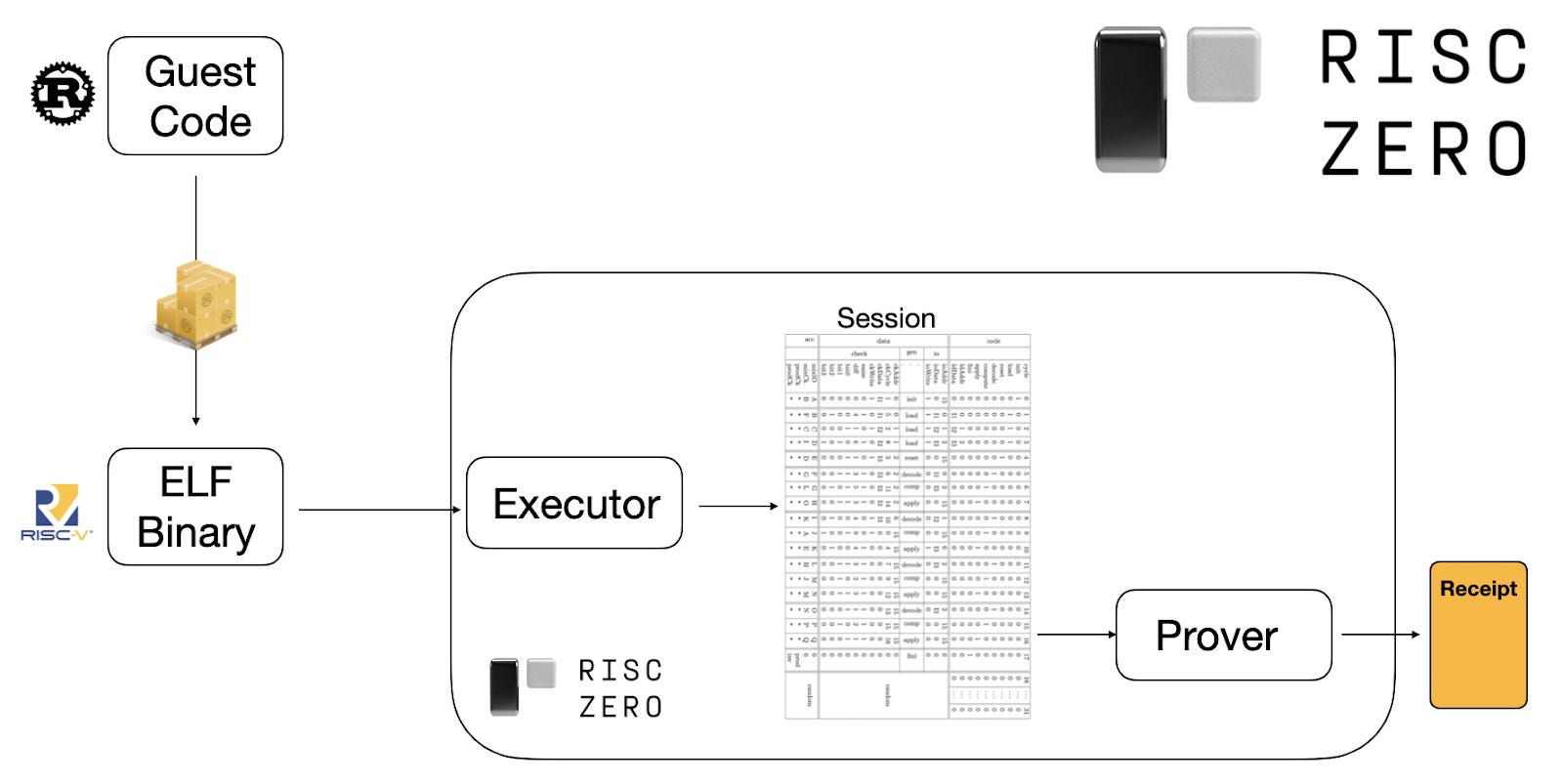
图 5:RISC Zero 的工作流程。
关于 RISC Zero,一个常见的问题是它为何更倾向于 RISC-V 而非其他指令集。我们找到两个关键原因。
首先,RISC-V 有一个简单但通用的指令集。 RISC Zero 仅需支持以下来自 riscv32im 的 46 条指令。
LB, LH, LW, LBU, LHU, ADDI, SLLI, SLTI, SLTIU, XORI, SRLI, SRAI, ORI, ANDI, AUIPC, SB, SH, AW, ADD, SUB, SLL, SLT, SLTU, XOR, SRL, SRA, OR, AND, MUL, MULH, MULSU, MULU, DIV, DIVU, REM, REMU, LUI, BEQ, BNE, BLT, BGE, BGEU, JALR, JAL, ECALL, EBREAK
这远远比 现代 Intel x86 好得多——x86 有 1131 条指令,而现代 ARM 可能有数百条指令。RISC-V 也与其他极简指令集(如 MIPS(MIPS 公司最终转向了 RISC-V)、WASM 和早期的 ARM 架构如 ARMv4T)差别不大。
其次,借助 LLVM,编译各种语言到 RISC-V 变得容易。 LLVM 是一个编译工具链,它在后端(“ISA”)和前端(“编程语言”)之间实现了一个中间层(称为“中间表示”)。由于 RISC-V 是支持的后端之一,LLVM 使得包括 C、C++、Haskell、Ruby、Rust、Swift 等多种前端可以被编译为 RISC-V。
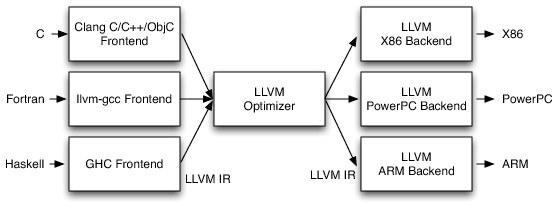
图 6:LLVM 的三阶段设计(来自 Chris Lattner 的书,RISC-V 也是一个可用的 LLVM 后端)。
换句话说,通过自下而上的方法,RISC Zero 能够支持使用现有 Web2 编程语言编写的程序。开发者也可以构建自己的 ZKP 特定领域语言(DSL)——这可以包括 ZoKrates、Cairo、Noir 和 Circom——并创建一个将它们转换为 RISC-V 的编译器。对于那些直接编译到 RISC-V 较为困难的语言,另一种选择是先将 DSL 编译成中间语言,如 C/C++,然后使用现有的 LLVM 编译器最终转换为 RISC-V。
人们可能还会问,为什么即使 RISC-V 是一个有利的选择,我们还要使用虚拟机?难道不能直接在现有的 ZK 特定 DSL 中,比如 ZoKrates、Cairo、Noir 和 Circom 中编写“约束系统”吗?
原因有两个。
首先,使用 RISC Zero 显著减少了开发时间。 在传统上,为 ZKP 制作约束系统是一个繁琐的任务,只有熟练的开发人员才能完成,通常需要数周的时间。更糟糕的是,调试约束系统可能需要更长时间,并且难以确保约束系统没有错误。这也是限制零知识证明开发和采用的主要因素之一——因为很难构建应用。
最初,打造历史证明项目以验证比特币或以太坊的历史 ,或者证明 AI 游戏机器人输出的零知识,可能被视作一项雄心勃勃的创业项目。如今,RISC Zero 使得曾经的雄心勃勃的追求变成了即便是黑客马拉松项目都可行的行为。例如,验证 Zama 的 FHE——一个非常复杂且之前从未为其编写过 ZKP 约束系统的应用——可以通过 RISC Zero 仅需几行代码完成。
这种转变也简化了招募开发人员的过程。拥有 Rust 使用经验的人可以轻松将现有的 Rust 代码迁移到 RISC Zero,而这人不需要过多的 Rust 知识。
其次,RISC Zero 甚至在某些方面可能超越人类的表现。 RISC Zero 的关键优势在于它 专门针对 32 位和 64 位整数计算进行了优化,并且能够管理大量存储器和内存,即便是一位熟练的 ZKP 工程师也无法与之匹敌。
在 RISC Zero 出现之前,进行这样的优化需要顶尖的 ZKP 研究者和工程师,诸如此类的技术极为新颖且从未文档化。该优化至少需要数月才能完成,因为它可能需要对查找参数的最具创造性的使用。
RISC Zero 已将这些尖端技术封装到其 Bonsai 框架中,使其既可访问又实惠。如果密码学被比作烹饪,那么 RISC Zero 则仿佛是微波炉。
回到我们的最初讨论,让我们探索如何利用 RISC Zero 来验证 Zama 的 FHE 计算的零知识。我们似乎只需复用来自 Zama 团队的一些代码,然后添加几行代码。
代码
在我们系列的第一部分中,我们演示了如何验证引导 FHE 密文的主要步骤:使用引导密钥对多项式进行“盲转”,如下所示。
#![no_main]
risc0_zkvm::guest::entry!(main);
// 从 Louis Tremblay Thibault(Zama)加载玩具 FHE Rust 库
use ttfhe::{N,
ggsw::{cmux, GgswCiphertext},
glwe::GlweCiphertext,
lwe::LweCiphertext
};
// 加载引导密钥和要引导的密文
static BSK_BYTES: &[u8] = include_bytes_aligned!(8, "../../../bsk");
static C_BYTES: &[u8] = include_bytes_aligned!(8, "../../../c");
pub fn main() {
// 一个零拷贝技巧,将密钥和密文加载到 RISC Zero
let bsk = unsafe {
std::mem::transmute::<&u8, &[GgswCiphertext; N]>(&BSK_BYTES[0])
};
let c = unsafe {
std::mem::transmute::<&u8, &LweCiphertext>(&C_BYTES[0])
};
// 初始化待盲转的多项式
let mut c_prime = GlweCiphertext::trivial_encrypt_lut_poly();
c_prime.rotate_trivial((2 * N as u64) - c.body);
// 执行盲转
for i in 0..N {
c_prime = cmux(&bsk[i], &c_prime, &c_prime.rotate(c.mask[i]));
}
eprintln!("test res: {}", c_prime.body.coefs[0]);
}排除加载依赖项或常量数据时的简单操作行,实际代码行数只有 5 行——包括多项式的初始化和盲转。
let mut c_prime = GlweCiphertext::trivial_encrypt_lut_poly();
c_prime.rotate_trivial((2 * N as u64) - c.body);
for i in 0..N {
c_prime = cmux(&bsk[i], &c_prime, &c_prime.rotate(c.mask[i]));
}执行 FHE 步骤的关键函数和算法,如 trivial_encrypt_lut_poly、rotate_trivial 和 cmux,均直接来自于 Louis Tremblay Thibault 在 Zama 开发的玩具 FHE Rust 库 (ttfhe)。
利用 RISC Zero,我们能够生成对该 RISC-V 程序执行的证明。以下来自 RISC Zero 的代码执行 RISC-V 程序(一个 ELF 格式的可执行文件)并生成一份证明(称为“收据”),以证明执行。让我们查看这段代码片段,以理解它如何完成这些任务:
let env = ExecutorEnv::builder().build().unwrap();
let prover = default_prover();
let receipt = prover.prove_elf(env, METHOD_NAME_ELF).unwrap();
receipt.verify(METHOD_NAME_ID).unwrap();这份收据可以传送给第三方,后者可以在不获取程序详细工作原理的情况下验证 RISC-V 程序的执行。对于需要更紧凑证明格式的情况,RISC Zero 也能够生成简洁的证明,同时保持其可验证性,同时更加简洁。
起点:Louis Tremblay Thibault 的 VFHE
我们的起点是 Louis Tremblay Thibault 开发的玩具 FHE Rust 库(https://github.com/tremblaythibaultl/ttfhe/),他是 Zama 的研究工程师。该库相当适合两个原因。
-
它非常接近 Zama 在生产中使用的 fhEVM 的库。
-
它是用 Rust 编写的,便于将其编译到 RISC-V。
图 7:Louis 的玩具 FHE Rust 库。
玩具 FHE Rust 库极为简约——它只有 6 个文件,包含 800 行代码——但为我们将使用的三种不同类型的 FHE 密文提供了全面支持。
-
LWE 密文(lwe.rs),其结构在这里是一个包含 1024 个 64 位整数的向量。
-
一般 LWE(GLWE)密文(glwe.rs),其结构在这里也是一个包含 1024 个 64 位整数的向量。
-
一般 Gentry–Sahai–Waters(GGSW)密文(ggsw.rs),其结构在这里是一种大小为 4 x 1024 的 64 位整数矩阵。
这足以让我们用 RISC Zero 开始我们的开发,因为我们主要需要的是一个高效的 Rust 实现,能够无缝编译为 RISC-V。Louis 已在 VFHE 库中(https://github.com/tremblaythibaultl/vfhe)开发了这些概念的初步版本,作为我们的基础起点。
#![no_main]
use risc0_zkvm::guest::env;
use ttfhe::{ggsw::BootstrappingKey, glwe::GlweCiphertext, lwe::LweCiphertext};
risc0_zkvm::guest::entry!(main);
pub fn main() {
// bincode 可以将 `bsk` 序列化为一个在磁盘上占39.9MB的 blob。
// 这个 `env::read()` 调用似乎不会停止——内存分配直到进程耗尽内存(OOM)。
let (c, bsk): (LweCiphertext, BootstrappingKey) = env::read();
let lut = GlweCiphertext::trivial_encrypt_lut_poly();
// `blind_rotate` 是一个相当重的计算,在 M2 MBP 上需要约 2 秒才能完成。
// 这可能就是进程耗尽内存的原因?
let blind_rotated_lut = lut.blind_rotate(c, &bsk);
let res_ct = blind_rotated_lut.sample_extract();
env::commit(&res_ct);
}然而,这仅仅是一个起点,因为代码中注释指出了两个重大问题。
第一个问题与数据加载有关。 我们面临的一个尚未解决的挑战是如何高效地加载引导密钥和密文——这些可能是巨大尺寸——到 RISC-V 程序中。
Louis 的解决方案是使用 RISC Zero 的 env::read 通道,这是在证明生成期间将数据外部馈送到 RISC-V 机器的标准方法。然而,正如 Louis 所指出的那样,这种方法并不是最优的,主要由于其巨大的内存要求以及仅用于数据加载所需的广泛的虚拟机 CPU 周期,导致的内存不足(OOM)问题。Parker Thompson 在 RISC Zero 也承认这可能是问题的来源:“一般来说,将大块数据读入客户程序是非常昂贵的。”(这里,客户是指将生成证明的 RISC-V 程序。)
为了规避这些数据加载开销,我们建议将数据直接嵌入到 RISC-V 程序中。在 Rust 中,典型的解决方案涉及使用 include_bytes_aligned! 宏,指示编译器将数据集成到 RISC-V 可执行文件中。随后,我们可以从字节中反序列化这些数据,例如,使用 bincode::deserialize。代码如下所示。
static BSK_BYTES: &[u8] = include_bytes_aligned!(8, ("../../../bsk");
let bsk: BootstrappingKey = bincode::deserialize(BSK_BYTES);然而,一个重大挑战来自于为整个 64MB 引导密钥分配内存并复制数据所需的大量周期。我们的基准测试显示,仅证明密钥的正确加载就至少需要 2 小时。
在本文中,我们揭示了一种在 RISC Zero 中处理大量数据加载的“零拷贝”技巧,它几乎不消耗 CPU 周期。我们将在本文中详细讨论这一技术。
第二个重大问题涉及计算。 正如 Louis 在代码中评论的那样,盲转的效率(这是引导的主要步骤)可能是一个问题,因为它本身并不是一个轻量级的计算(“在 M2 MBP 上需要 2 秒才能完成”)。这是整个“在 RISC Zero 中验证 FHE”的更大挑战。
我们在 RISC Zero 中设计和实施了一些技巧和技术来优化这部分。这段在 RISC Zero 中优化 FHE 计算的旅程十分广泛,我们计划在本系列中 dedicating 若干篇文章详细解释每一个技巧和技术。请关注本系列即将推出的文章!为确保你不会错过,请考虑订阅我们的 Substack。
订阅
加载大量数据的零拷贝技巧
在本节中,我们将深入探讨如何克服 RISC-V 程序中的数据加载挑战,强调显著减少 RISC-V CPU 周期的方法。
核心思想是在 RISC-V 中避免拷贝数据。这一点至关重要,因为拷贝一组 64MB 数据集在 RISC-V 中将需要超过 5000 万条指令——一条指令来读取数据,一条指令来写入数据,以及一条指令来更新指针。所有这些指令在某种程度上都是不必要的,因为数据现在已由 Rust 编译器作为 RISC-V 程序的一部分合法包含。
在 Rust 中实现这一点是有挑战的,因为其固有的设计是为了内存安全。Rust 中的标准实践涉及通过严格的过程初始化数据结构:在堆栈或堆中分配数据结构,零化数据结构的内存(通过逐字填充整个内存填写为零),并逐个拷贝这些数据。可以看到,Rust在消费计算周期时是更加奢侈的,因为零化内存至少还需另花费 3400 万条指令。
我们的解决方案使用某些低级 Rust 原语,使我们能够“绕过”Rust LLVM 编译器施加的限制,从而更有效地编程 RISC-V。
在与 Greater Heat 合作进行 Aleo 挖矿的时候,我学习到了一种有价值的技术,涉及 ‘std::mem::transmute’。"这是一种特殊的 Rust 函数,用于重新解释一种类型的位到另一种类型。特别是,它可以用于修改指针的类型。
对于我们的应用,我们将引导密钥(BSK_BYTES)和待引导密文(C_BYTES)的内存区域字节明确嵌入(或者,更确切地说,硬编码)直接写入 RISC-V 文件。为了避免数据复制的需求,我们直接操纵指针的类型,如下所示。
let bsk = unsafe {
std::mem::transmute::<&u8, &[GgswCiphertext; N]>(&BSK_BYTES[0])
};
let c = unsafe {
std::mem::transmute::<&u8, &LweCiphertext>(&C_BYTES[0])
};如前式代码所示,我们获得了硬编码数据的 ELF 段指针,最初是一个字节指针(&u8)。然后,我们将其转换为引导密钥指针(&[GgswCiphertext; N])或 LWE 密文指针(&LweCiphertext)。此外,必须将这段代码包裹在 unsafe 语句块中,因为 Rust 将此低级函数视作不安全,并要求明确承认操作的潜在风险。使用 unsafe 的方式并不意味着危险;而是表明处理如此低级操作需要特定专业知识。
对于熟悉 C/C++ 的读者而言,此过程可以类比于类型转换。在 C/C++ 中,等价的代码如下所示。
/* C */
BootstrappingKey *bsk = (BootstrappingKey*) &BSK_BYTES[0];
LweCiphertext *c = (LweCiphertext*) &C_BYTES[0];
/* C++ */
BootstrappingKey *bsk = reinterpret_cast<BootstrappingKey*>(&BSK_BYTES[0]);
LweCiphertext *c = reinterpret_cast<LweCiphertext*>(&C_BYTES[0]);我们的实验结果表明,使用此方法进行数据加载通常消耗的周期几乎被消除了。在随后的分析中,我们将通过使用 RISC-V 反编译器进一步验证这一零拷贝操作。
关注 RISC-V
我们已经解决了 Zama 的 Louis 在使用 RISC Zero 来执行 FHE 引导验证时遇到的初始挑战。在本系列即将出版的文章中,我们将进一步深入探讨性能优化及其细节。
当我们结束这一部分时,我们的下一步是使用 RISC-V 反编译器检查 RISC Zero 在零知识背景下验证的程序。我们的目标是双重的:
-
确认我们的方法在 RISC-V 汇编级别有效地实现了零拷贝。
-
充分了解我们 RISC-V 程序的整体结构。
为此,我们利用 Ghidra(https://github.com/NationalSecurityAgency/ghidra),这是由美国国家安全局(NSA)开发的综合、免费使用的逆向工程框架,显著地包括对 RISC-V 的支持。
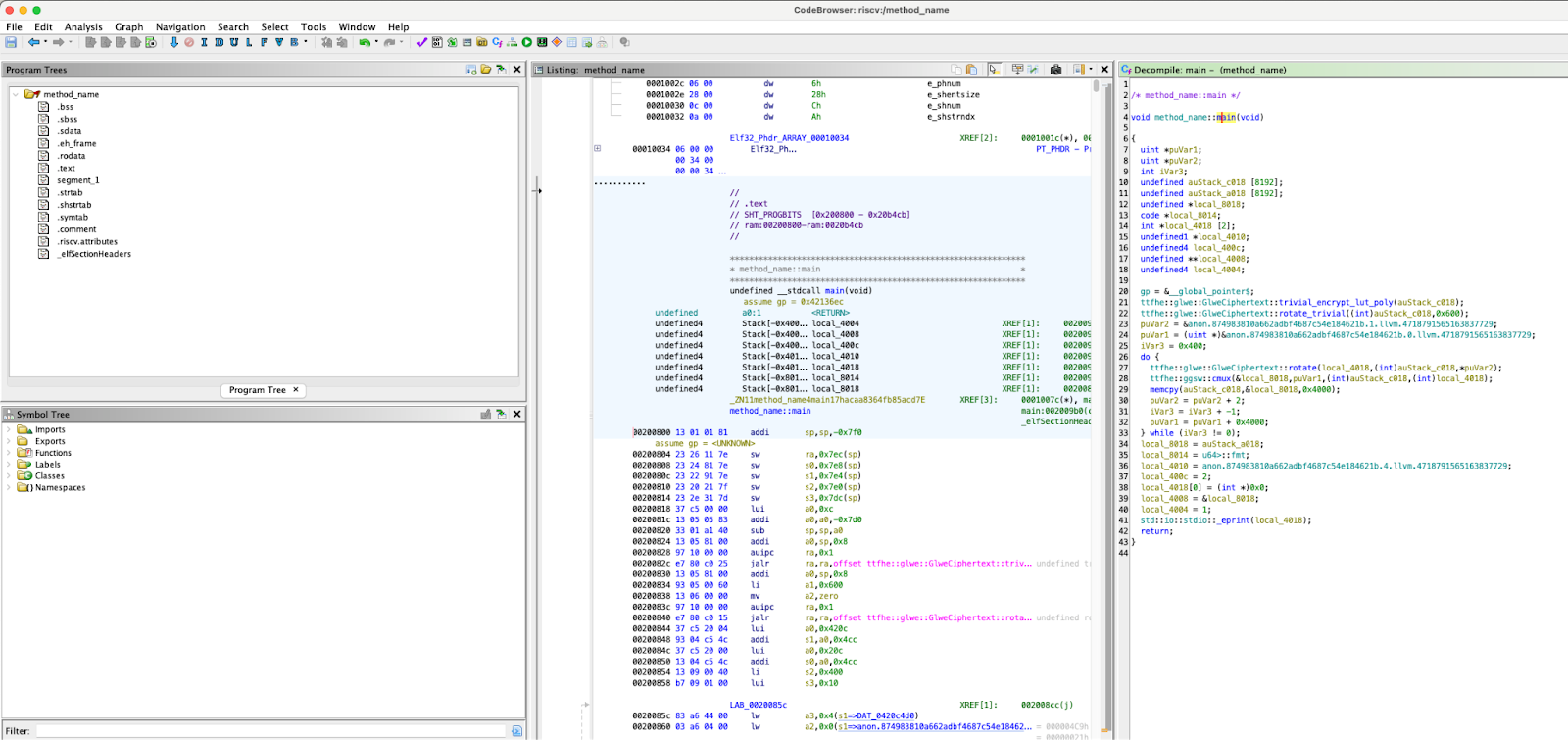
图 8:Ghidra 的 CodeBrowser 展示了 RISC Zero 正在验证的 RISC-V 程序。
Ghidra 允许我们查看 RISC-V 汇编代码——如中间面板所示——以及还原成 C 语言的代码——如右侧所示。回顾我们之前提到的 RISC-V 的 46 条指令,值得注意的是,我们分析的汇编代码正好利用了这些指令。
我们接下来将重点放在自动生成的还原代码上,进行详细分析。
/* method_name::main */
void method_name::main(void)
{
uint *puVar1;
uint *puVar2;
int iVar3;
undefined auStack_c018 [8192];
undefined auStack_a018 [8192];
undefined *local_8018;
code *local_8014;
int *local_4018 [2];
undefined1 *local_4010;
undefined4 local_400c;
undefined **local_4008;
undefined4 local_4004;
gp = &__global_pointer$;
ttfhe::glwe::GlweCiphertext::trivial_encrypt_lut_poly(auStack_c018);
ttfhe::glwe::GlweCiphertext::rotate_trivial((int)auStack_c018,0x600);
puVar2 = &anon.874983810a662adbf4687c54e184621b.1.llvm.4718791565163837729;
puVar1 = (uint *)&anon.874983810a662adbf4687c54e184621b.0.llvm.4718791565163837729;
iVar3 = 0x400;
do {
ttfhe::glwe::GlweCiphertext::rotate(local_4018,(int)auStack_c018,*puVar2);
ttfhe::ggsw::cmux(&local_8018,puVar1,(int)auStack_c018,(int)local_4018);
memcpy(auStack_c018,&local_8018,0x4000);
puVar2 = puVar2 + 2;
iVar3 = iVar3 + -1;
puVar1 = puVar1 + 0x4000;
} while (iVar3 != 0);
local_8018 = auStack_a018;
local_8014 = u64>::fmt;
local_4010 = anon.874983810a662adbf4687c54e184621b.4.llvm.4718791565163837729;
local_400c = 2;
local_4018[0] = (int *)0x0;
local_4008 = &local_8018;
local_4004 = 1;
std::io::stdio::_eprint(local_4018);
return;
}我们初步观察确认数据加载过程确实实现了零拷贝效率。使用 std::mem::transmute 进行数据加载的代码段编译为 16 字节的 RISC-V 机器代码序列:
37 c5 20 04 93 04 c5 4c 37 c5 20 00 13 04 c5 4c
反编译显示出四条汇编指令,负责将指针值存储到 s1 和 s0 寄存器。实际上,这段代码将值 0x420c4cc 分配给 s1 寄存器,0x020c4cc 分配给 s0 寄存器。
00200844 37 c5 20 04 lui a0,0x420c
00200848 93 04 c5 4c addi s1,a0,0x4cc
0020084c 37 c5 20 00 lui a0,0x20c
00200850 13 04 c5 4c addi s0,a0,0x4cc
接下来,我们可以进一步将这些汇编代码反编译为类似 C 的格式,以便更清晰地理解,如下所示。
uint *puVar1;
uint *puVar2;
puVar2 = &anon.874983810a662adbf4687c54e184621b.1.llvm.4718791565163837729;
puVar1 = (uint *)&anon.874983810a662adbf4687c54e184621b.0.llvm.4718791565163837729;在反编译代码中,第一个标签——anon.874983810a662adbf4687c54e184621b.1.llvm.4718791565163837729——特别表明了密文字节的位置,即 C_BYTES。借助 Ghidra,我们能够直接观察到这些密文字节位于代码中。

图 9:ELF 可执行文件在位置 0x420c4cc(即 s1 寄存器的初值)处的数据,即待引导的密文。
请记住,C_BYTES 是从一个名为 c 的文件中引入的。通过使用 Hex Fiend,一个用于十六进制编辑的工具,我们可以检查该文件的内容。检查过程如下,确认了数据的准确性。
static C_BYTES: &[u8] = include_bytes!("../../../c");
图 10:存储待引导密文的“c”文件,在十六进制编辑器中显示。
类似地,当我们导航到第二个标签—— anon.874983810a662adbf4687c54e184621b.0.llvm.4718791565163837729——我们可以找到引导密钥(BSK_BYTES)所对应的字节。图11:ELF 可执行文件在位置 0x020c4cc 的数据(即 s0 寄存器的初始值),用于引导密钥。
此外,我们可以通过将该数据与其源文件 'bsk' 进行交叉检查来验证这些数据,确保其与上述信息一致。

图10:存储引导密钥的 “bsk” 文件,在十六进制编辑器中显示。
接下来,让我们探索密钥和密文在程序中是如何使用的。请回顾 Rust 源代码,密钥和密文在 for 循环中都是必不可少的,特别是在调用 `cmux` 函数时。
// 执行盲轮换
for i in 0..N {
c_prime = cmux(&bsk[i], &c_prime, &c_prime.rotate(c.mask[i]));
}现在,让我们把注意力转向 Ghidra,以找到并检查相应的反编译代码。
puVar2 = &anon.874983810a662adbf4687c54e184621b.1.llvm.4718791565163837729;
puVar1 = (uint *)&anon.874983810a662adbf4687c54e184621b.0.llvm.4718791565163837729;
iVar3 = 0x400;
do {
ttfhe::glwe::GlweCiphertext::rotate(local_4018,(int)auStack_c018,*puVar2);
ttfhe::ggsw::cmux(&local_8018,puVar1,(int)auStack_c018,(int)local_4018);
memcpy(auStack_c018,&local_8018,0x4000);
puVar2 = puVar2 + 2;
iVar3 = iVar3 + -1;
puVar1 = puVar1 + 0x4000;
} while (iVar3 != 0);反编译代码涉及多个组件。
-
游标分配:
puVar2作为当前指向c的游标,而puVar1与bsk对齐。此设置便利了在密文和引导密钥之间的导航。 -
循环机制: 循环使用
iVar3,一个从 1024 开始递减的计数器,达到零时表示循环的终止。在每次迭代中,执行多个操作: -
密文操作:
c_prime存储在栈中的auStack_c018,首先使用c.mask[i](称为*puVar2)进行轮换,以产生放置在local_4018的结果。 -
`cmux` 函数调用: 这个关键函数接受
bsk[i](puVar1)、原始的c_prime和轮换后的c_prime作为输入,输出结果到local_8018。 -
优化机会: 有趣的是对
local_8018的处理,将其作为更新后的c_prime。它被复制回c_prime变量,暗示了潜在的优化机会。通过以原地方式执行cmux来消除此复制可能会提高效率。 -
游标更新: 循环还包括对
puVar2和puVar1的更新。puVar2向前移动两个双字(64 位),以指向下一个c.mask[i],而puVar1通过 16384 个双字(524288 位)向前推进,以指向下一个bsk[i]。
在 iVar3 变为零时循环结束,这些步骤共同构成了在 RISC-V 程序中处理 FHE 引导的过程。
进一步使用 Ghidra 的分析使我们能够审查程序的其他部分,提供对潜在优化机会的洞察。这个过程帮助我们评估 Rust RISC-V 编译器是否如预期生成 RISC-V 指令。
例如,让我们检查 cmux 函数的反编译代码。为提供背景,我们首先考虑原始的 Rust 代码,如下所示。
/// 密文多路复用器。如果 `ctb` 是 `1` 的加密,则返回 `ct1`。否则,返回 `ct2`。
pub fn cmux(ctb: &GgswCiphertext, ct1: &GlweCiphertext, ct2: &GlweCiphertext) -> GlweCiphertext {
let mut res = ct2.sub(ct1);
res = ctb.external_product(&res);
res = res.add(ct1);
res
}反编译代码显示,调用 `sub` 和 `add` 的函数在编译期间已有效内联。这种内联导致代码中出现可见的循环,负责模拟 64 位整数操作。此外,代码使用了多个对 `memset` 和 `memcpy` 的调用。值得注意的是,一些 `memset` 的实例被用于将内存清零,这并不总是必要的。这个观察为消除不必要的 `memset` 调用打开了潜在的优化途径。
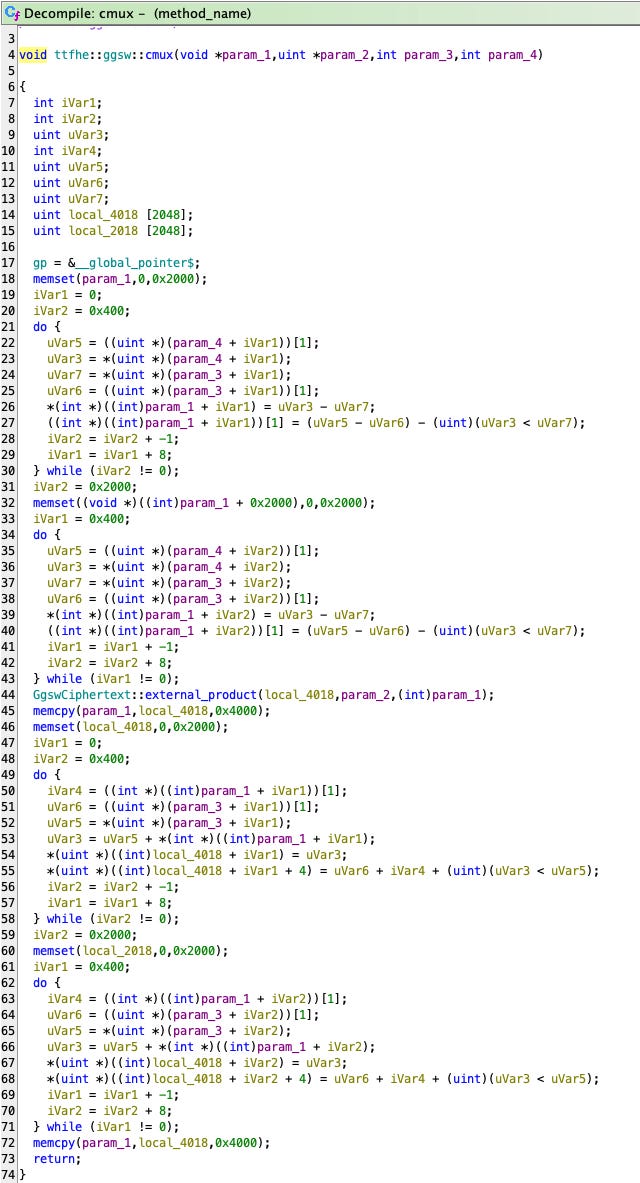
图11:`cmux` 函数的 RISC-V 指令的反编译代码。
至此,我们结束了对验证 RISC Zero 中 FHE 的技术深入分析第一部分。本文章概述了 FHE 和 RISC Zero,详细描述了将现有 Rust 代码适配到 RISC Zero 的过程,介绍了 RISC Zero 中一种新的数据加载优化技巧,并演示了使用 Ghidra 反汇编和分析 RISC-V 代码以识别进一步优化机会的方法。
请关注我们即将发布的关于“验证 RISC Zero 中 FHE”系列的文章,我们将深入探讨更高级的概念和优化。
更新于 2023年12月14日: 我们注意到 `include_bytes` 可能无法正确对齐数据,并可能导致对齐错误。因此,我们选择使用来自 这个库 的 `include_bytes_aligned`。
在 l2iterative.com 和 Twitter 上关注 L2IV @ l2iterative
作者: Weikeng Chen, L2IV 研究合作伙伴 ( @weikengchen)
- 原文链接: l2ivresearch.substack.co...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





