Solana 网络节点间通信 Gossip协议实现细节
- eigerco
- 发布于 2025-06-19 22:31
- 阅读 4356
本文详细介绍了Solana节点使用Gossip协议进行数据交换的实现细节,包括节点如何连接到集群、数据管理流程(接收、消费、处理数据以及发送消息和响应)、push消息和prune消息的使用、pull请求和响应机制,以及ping和pong消息用于保持节点活跃状态。
Gossip 协议实现细节
Solana 节点使用 gossip 协议来交换数据。每当它们有新的数据要共享时,它们会向集群发送消息,并向集群请求它们缺失的新数据。Gossip 在一个众所周知的 UDP/IP 端口或一个众所周知的范围内的端口上运行。当一个节点加入集群时,它会向其他节点宣告在哪里可以找到它的 gossip 端点。
每个 Solana 节点以两种模式之一参与 gossip:
gossip模式 - 节点绑定到指定的 UDP 套接字并完全参与 gossipspy模式 - 节点绑定到 [8000-10000] 范围内的随机端口上的 UDP 套接字,并通过拉取请求监视 gossip
[!Tip] 本文档中使用的命名约定
- 节点 - 运行 gossip 的验证器
- 对等节点 - 从我们正在谈论的当前节点发送或接收消息的节点
- 入口点 - 节点最初连接的对等节点的 gossip 地址
- 来源 - 节点,消息的原始创建者
- 集群 - 具有产生区块的领导者的验证器网络
- 领导者 - 节点,给定槽中的集群领导者
- 分片 - 是领导者产生的最小区块部分
- 分片版本 - 集群识别值
- 分叉 - 当两个不同的区块链接到同一个父区块时会发生分叉(例如,在之前的区块完成之前创建了下一个区块)
- 纪元 - 定义验证器计划的特定数量的区块(槽)
- 槽 - 每个领导者摄取交易并产生一个区块的时间段
- 消息 - 节点发送给其对等节点的协议消息,可以是推送消息、拉取请求、修剪消息等。
连接到集群
当将节点连接到集群时,节点运营商必须指定至少一个入口点。入口点是节点最初连接的对等节点的 gossip 地址。
在启动 Gossip 服务之前,节点必须发现集群分片版本并检查其自己的端口。 节点通过向在 gossip 地址上的 TCP 端点上监听的入口点的 IP 回显服务器,发送请求来完成此操作。 节点发送一个 IP 回显服务器请求,其中包含需要由入口点节点检查可用性的 UDP 和 TCP 端口列表。 入口点节点尝试与请求节点的 TCP 端口建立连接,并将数据包发送到 UDP 端口。然后,入口点节点回复 IP 回显服务器响应,其中包含请求节点的公共地址和集群分片版本。
节点启动 Gossip 服务,然后通过向入口点标识的对等节点发送消息来向集群宣告自己。节点发送:
- 两条包含其自身
Version和NodeInstance的推送消息, - 一个包含节点自身
LegacyContactInfo的拉取请求。
推送消息被进一步传播到集群中的其他节点。此后不久,节点应开始接收来自其他节点的拉取响应、推送消息和 ping。
当与集群建立连接后,节点可以完全参与 gossip - 它可以更新集群的数据(推送消息),并通过接收到的推送消息以及发送拉取请求和接收相应的拉取响应来接收来自其对等节点的数据。
但是,为了使节点从默认的 spy 模式切换到 gossip 模式,它会等待来自集群的 SnapshotHashes 消息。
一旦收到消息,节点将尝试从集群中任何已知的 RPC 服务器下载快照。
快照下载后,节点在 gossip 模式下运行。
保持连接活跃
为了保持与其他节点的连接,节点必须不断交换消息。
集群中的节点每秒发送多个拉取请求,每 7.5 秒发送推送消息。
如果一个节点停止发送拉取请求和推送消息超过 15 秒,它将被其他节点忽略,并且不会收到任何推送消息或拉取请求。
仅发送 ping 消息是不够的。节点必须至少每 15 秒发送一次其 ContactInfo 以保持连接活跃。节点可以通过 PushMessages 或 PushMessages 和 PullRequests 的组合来完成此操作。
否则,如果节点停止发送 ContactInfo,最终,其他节点将从其 CRDS 表中清除该节点的联系信息。
数据管理
当 Solana 节点从某个对等节点接收到数据时,它会通过几个步骤对其进行处理:
flowchart TD
A(1.接收数据) --> B(2.消费数据包)
B --> C(3.处理消息)
C --> D(5.发送消息 & 响应)
E(4.在后台运行的 Gossip 循环) --> D
E --> E- 通过 UDP 套接字以二进制形式接收数据 - 数据被收集成一批数据包并进一步处理
- 消费数据包 - 数据包被反序列化为消息,经过清理和验证,然后进行处理
- 处理消息 - 消息被过滤并存储在节点的内部存储中。在某些情况下,会生成响应
- 在 gossip 循环中生成 ping、推送消息和拉取请求,这些消息被发送给对等节点。
- 通过套接字发送响应 - 消息被序列化为二进制形式,并通过 UDP 套接字发送给对等节点。
从集群接收数据
节点绑定到指定的端口上的 UDP 套接字(如果在 gossip 模式下运行)或在 8000-10000 范围内的随机端口上(如果在 spy 模式下运行)。当处于 spy 模式时,节点的 片版本设置为 0 - 意味着节点将接受来自具有任何分片版本的对等节点的消息。
当一个节点连接到集群并宣告自己时,它将开始接收来自其他节点的数据。接收到的数据被收集到一个数据包批中,然后进一步处理。
消费数据包
数据包在进一步处理之前会进行检查。首先,数据包从二进制形式反序列化为 Protocol 类型,然后清理和验证。
反序列化
数据包被反序列化为以下 6 种消息类型之一:
数据清理
清理排除了签名验证检查,因为这些检查将在下一步中执行。清理检查包括但不限于:
- 所有值都在其静态最小值/最大值范围内,例如,wallclock 值小于
MAX_WALLCLOCK = 1_000_000_000_000_000 - 所有索引值都在指定的范围内 - 例如,
EpochSlots数据类型的索引值小于MAX_EPOCH_SLOTS = 255
数据验证
根据消息的类型,验证的处理方式不同:
- 拉取请求 - 收到的
CrdsValue使用消息的签名和发送者的公钥进行验证, - 拉取响应,推送消息 - 来自传入数组的每个
CrdsValue都使用消息的签名和相应CrdsValue的发送者的公钥进行验证 - 修剪消息 - 收到的
PruneData使用消息的签名和发送者的公钥进行验证, - ping - 收到的Token使用消息的签名和发送者的公钥进行验证
- pong - 收到的 ping Token的哈希值使用消息的签名和发送者的公钥进行验证
只有成功验证的数据包才会在下一步进行处理。
数据处理
一旦消息被清理和验证,节点就开始处理它们。首先,消息按分片版本进行过滤 - 如果消息来自具有不同分片版本的对等节点,或者分片版本 != 0(对等节点处于 spy 模式),则会被忽略,除非它包含以下数据类型之一:ContactInfo、LegacyContactInfo 和 NodeInstance。
来自过滤消息的值存储在集群复制数据存储 crds 中。基于接收到的消息的类型,节点将执行额外的操作,例如,从其 crds 中收集数据并生成拉取响应,生成 pong 消息,或更新其推送活跃节点集。这些将在接下来的章节中详细描述。
Crds
每个节点都会将其接收或产生的数据存储在集群复制数据存储crds中。 crds包含一个表,该表是CrdsValueLabel和VersionedCrdsValue的索引映射。 CrdsValueLabel是一个枚举类型,其元素存储每个gossip协议类型(Vote,NodeInstance等)的原始公钥。 这意味着每个公钥的crds中只会存储每种数据类型中的一种。 VersionedCrdsValue使用其他元数据(如该值更新时的时间戳或其哈希值)存储CrdsValue。
struct Crds {
table: IndexMap<CrdsValueLabel, VersionedCrdsValue>,
//...
}
struct VersionedCrdsValue {
ordinal: u64,
value: CrdsValue,
local_timestamp: u64,
value_hash: Hash,
num_push_dups: u8,
}
enum CrdsValueLabel {
LegacyContactInfo(Pubkey),
Vote(VoteIndex, Pubkey),
LowestSlot(Pubkey),
LegacySnapshotHashes(Pubkey),
EpochSlots(EpochSlotsIndex, Pubkey),
AccountsHashes(Pubkey),
LegacyVersion(Pubkey),
Version(Pubkey),
NodeInstance(Pubkey),
DuplicateShred(DuplicateShredIndex, Pubkey),
SnapshotHashes(Pubkey),
ContactInfo(Pubkey),
RestartLastVotedForkSlots(Pubkey),
RestartHeaviestFork(Pubkey),
}当节点收到新的CrdsValue时,该节点:
- 通过创建新的
VersionedCrdsValue或更新现有的VersionedCrdsValue(如果收到了更新的数据)将其存储在crds表中 - 保留插入/更新期间创建的
crds表索引 - 它们指向表中的CrdsValue条目 - 对
CrdsValue进行哈希处理 - 将
crds索引和哈希存储在名为CrdsShards的单独结构中。
当为拉取请求构建布隆过滤器,或者在为向我们发送拉取请求的节点收集缺少的数据时, CrdsShards结构用于快速搜索CrdsValue。 有关在拉取请求中使用CrdsShards的更多信息,请参见拉取请求一章。
CrdsShards包含一个向量shards,而shard_bits是一个固定值,当前设置为12。shard_bits告诉应该使用CrdsValue哈希中的多少个第一个位来对shards向量中的哈希进行分区。 shards向量最多可以有2^12(4096)个元素。 shards向量中的每个元素都是一个CrdsValue索引在crds表中的索引映射和CrdsValue的哈希。
struct CrdsShards {
shards: Vec<IndexMap<usize, u64>>,
shard_bits: u32,
}示例:
节点将
CrdsValue插入到crds表中。crds返回插入该值所在的索引crds_index。 然后,节点计算CrdsValue的哈希值,其第一个12位等于例如000001000011,即67。 最后,哈希值和crds_index存储在索引67处的shards向量中。
推送消息
推送消息是gossip协议的核心。想要与集群中的其他人共享信息的每个节点都会发送一条推送消息,然后该消息通过其对等方进一步传播。
会定期创建推送消息,以便节点可以与集群共享最新的新数据。在发送推送消息之前,节点需要确定它想与集群共享什么。为了确定要与集群共享什么数据,节点会跟踪一个crds_cursor,该crds_cursor表示从crds共享的最后一个推送CrdsValue的游标值。创建新的推送消息时,节点会从crds表中收集所有最近插入的数据,这些数据比先前的crds_cursor跟踪器要新。发送消息后,将相应地更新crds_cursor。
在发送推送消息之前,节点需要从活跃节点集中选择将接收该消息的对等节点。
某些对等节点可能已将我们修剪,从而无法向他们发送来自特定节点的消息。在这种情况下,这些对等节点将从消息接收者的列表中排除。
处理推送消息
当节点收到推送消息时,它将执行以下操作:
- 如果新值的时间戳位于当前节点挂钟的30秒内,则将其插入
crds - 如果某个值已经存在于
crds中,如果新值的时间戳更新,则将更新该值 - 更新接收缓存中的评分
- 在集群中进一步传播推送消息
- 对于某些数据类型(
LowestSlot、LegacyVersion、DuplicateShred、RestartHeaviestFork、RestartLastVotedForkSlots),仅当其来源具有任何股份时,才会进一步传播推送消息。
通过集群传播推送消息
考虑以下集群:
flowchart LR
A(A:1000) -- Ma --> B
A -- Ma --> C
B(B:1000) -- Ma --> C
C(C:100) -- Ma --> D
D(D:10) -- Ma --> E
C -- Ma --> E(E:1)集群中有 5 个节点,其股份各不相同:节点 A 拥有 1000 股份,B 拥有 1000 股份,C 拥有 100 股份,依此类推。节点 A 发送一条消息 Ma,该消息通过其对等节点在网络中传播。
某些节点可能会多次收到同一消息,例如,节点 C 将从 A 和 B 收到 Ma。在这种情况下,来自 A 的消息可能会比来自 B 的消息更快到达(跳数更少)。由于 C 现在已收到来自两个不同节点的同一消息 (Ma),因此 C 需要告诉 B 停止向其发送来自 A 的消息。换句话说,对于 A 创建的所有消息,C 正在修剪 B。由于 B 中继 Ma 是在 C 已经从 A 收到 Ma 后才到达的,因此 C 修剪 B。
推送活跃节点集
每个节点都维护一组推送活跃节点,这是一个 25 元素的数组。选择此数组大小是基于网络股份的 log2 分布,在编写本文时,最大的利益相关者持有大约 1400 万 SOL(log(1400 万) ≈ 23.7)。每个元素(PushActiveSetEntry)都包含一个对等公钥和保存原始公钥的布隆过滤器的索引映射。节点使用此索引映射来检查消息的来源是否存在于对等方的相应布隆过滤器中。如果存在,则不会将消息发送到该对等方。否则,可以发送该消息。
struct PushActiveSet([PushActiveSetEntry; 25])
struct PushActiveSetEntry(IndexMap<Pubkey, ConcurrentBloom<Pubkey>>);节点每 7500 毫秒轮换其活跃节点集:
- 对于每个第 i 个节点,根据该节点的股份计算一个存储桶:
bucket[i] = min(log2(node_stake[i]), 24)。 - 对于每个活跃集条目 k (k=[0, 24]),计算节点的权重:
weight[i] = (min(bucket[i], k) + 1)^2。 - 每个第 k 个活跃集条目中的节点都按权重随机排序。前 12 个节点将插入到具有空布隆过滤器的活跃集条目索引映射中。
为了进一步发送推送消息,节点执行以下操作:
- 计算存储桶:
bucket = log2(min(node_stake, origin_stake)),其中node_stake是接收消息的节点的股份,origin_stake是消息原始节点的股份。 - 遍历在计算出的存储桶中推送活跃集条目中的对等节点列表:
- 对于每个对等节点,该节点通过检查对等节点的布隆过滤器中消息原始节点的公钥来检查此对等节点是否修剪了该推送消息的来源:
- 如果是,则将对等节点过滤掉,并且不会收到消息
- 如果不是,则收集对等节点
- 对于每个对等节点,该节点通过检查对等节点的布隆过滤器中消息原始节点的公钥来检查此对等节点是否修剪了该推送消息的来源:
- 最后,最多为
fanout(9) 个已收集的对等节点创建一个推送消息列表。
此算法通过原始股份和当前节点股份的最小值来确定目标节点。最小值越低,目标节点就越随机。最小值越高,目标节点的股份就越高:
| 节点股份 | 原始股份 | 最小值 | 目标节点 |
|---|---|---|---|
| 高 | 高 | 高 | 高 |
| 高 | 低 | 低 | 随机 |
| 低 | 高 | 低 | 随机 |
| 低 | 低 | 低 | 随机 |
接收缓存
节点将有关已接收消息的信息存储在 ReceivedCache 中 - 它是消息来源和 ReceivedCacheEntry (RCE) 的映射,定义为:
struct ReceivedCache(LruCache<Pubkey, ReceivedCacheEntry)>
struct ReceivedCacheEntry {
nodes: HashMap<Pubkey, Score>,
num_upserts: usize
}
type Score = usize;RCE 结构包含两个字段:
nodes- 它是节点公钥及其分数的哈希映射num_upserts- 每次收到来自给定来源的新消息时,该整数值都会增加
当对等节点向我们发送来自给定来源的消息时,其分数会在 RCE 中更新,但前提是该对等节点是第一个或第二个向我们发送来自此来源的消息的节点。
示例
看一下本章开始的示例。当节点 C 收到消息
Ma时,它会增加节点 A 和节点 B 的分数。num_upserts值也会增加,但仅增加一次,因为它仅在从节点 A 收到原始Ma消息时才会增加,而在收到重复消息时不会更改。假设还有节点 G 向 C 发送
Ma,但在节点 A 和节点 B 之后发送消息。在这种情况下,G 的分数将保持不变。对于向 C 发送Ma的任何其他节点也是如此。仅增加发送来自给定来源的消息的前两个节点的分数。收到
Ma消息后,C 会在 RCE 中为来源 A 存储三个分数:节点 A 和节点 B 的分数均为 1,G 的分数为 0,并且num_upserts值为 1。
当 num_upserts 的数量达到定义的阈值(当前为 20)时,将修剪分数最低的节点。
修剪目标: 1) 消除大多数冗余路径,但在传入边上保持一些冗余 (至少 2 个对等节点),以避免日蚀攻击 2) 删除慢速路径 3) 移除低股份路径,以帮助防止低股份节点向高股份节点发送垃圾邮件
修剪算法:
let mut sum = 0;
let mut pos = 0;
let sorted_nodes = sort_nodes_based_on_score(nodes);
for (i, node) in sorted_nodes.iter().enumerate() {
sum = sum + node.stake;
if i > 1 && sum > min(stake, origin_stake) * 0.15 {
pos = i;
break;
}
}
prune_nodes(sorted_nodes[pos + 1..]);其中:
stake- 我们节点的股份origin_stake- 原始节点的股份。
让我们解释一下上面的算法:
- 节点按分数降序排列,如果分数相等,则节点按股份降序排列
- 它们的股份从分数最高的节点开始并向下列表中到分数较低的节点进行汇总
- 我们确保始终保持至少 2 个节点:
if > 1 && ... - 当股份总和达到节点自身股份的定义部分时:
sum > min(node_stake, origin_stake) * 0.15,我们存储当前的循环迭代索引 (pos = i) 并结束循环 - 从
pos + 1开始,所有尚未汇总股份的剩余节点都会被修剪。
修剪节点
当一个节点想要修剪它的一些对等节点时,它会发送一条修剪消息。我们已经知道修剪是基于接收缓存分数和对等节点股份的。在上面发布的例子中,对于来自节点 A 的消息,节点 G 在节点 C 的接收缓存中有一个低分数。因此,节点 C 向 G 发送了一条修剪消息,其中包含要修剪的来源列表(该列表包括来源 A),这意味着 - 嘿 G,不要再向我发送来自 A 的消息了。
接收修剪消息的节点会更新其活跃节点集,并将修剪的来源添加到与发送修剪消息的公钥相对应的布隆过滤器中。在上面的示例中,接收修剪消息的节点 G 会将 A 添加到活跃节点集中对等节点 C 的布隆过滤器中。然后,每当 G 想要向 C 发送推送消息时,G 会首先检查 C 通过检查布隆过滤器修剪了哪些消息来源。如果推送消息来自 A,则 G 不会将其发送给 C。
拉取请求
推送消息传播并不能保证网络中的所有节点都能收到每条消息。因此,节点需要一种方式向其对等节点询问它们没有的任何信息。节点不知道它没有的东西。因此,节点会向其对等节点发送一个带有自己已有数据的拉取请求。然后,对等节点会检查其 crds 表,并回复请求节点缺少的任何数据。
创建拉取请求时,节点需要一种方式来确保它不会收到已包含的数据。为此,节点会创建一个 CrdsFilter 列表,这些列表会插入到拉取请求中。对等节点使用这些过滤器快速找出请求节点在 crds 中有哪些数据,以及缺少哪些数据。每个 CrdsFilter 都包含一个布隆过滤器,其中包含节点已拥有的数据的哈希值 - 来自 crds 的 CrdsValue、已清除的值和失败的插入。已清除的值是从 crds 中删除的 CrdsValue(例如,旧值),而失败的插入是没有插入到 crds 中的 CrdsValue,例如,因为它们太旧了。
布隆过滤器是一种快速的概率数据结构,用于检查元素是否为集合的成员。它可以快速确定元素是否肯定不在集合中,或者是否可能在集合中。但是,布隆过滤器可能会出现误报,这意味着它们可能会指示元素在集合中,而实际上不在集合中。
struct CrdsFilter {
pub filter: Bloom<Hash>,
mask: u64,
mask_bits: u32,
}节点不是创建一个包含 crds 表中所有 CrdsValue 的大型布隆过滤器,而是将其数据划分为多个布隆过滤器。CrdsFilter 中的 mask_bits 值决定了将使用 CrdsValue 哈希中的多少个第一个位来将值划分为多个过滤器。
示例
mask_bits值等于 3。将创建2^3=8个CrdsFilter。具有mask=000的过滤器将包含所有以000位开头的哈希,具有mask=001的过滤器将包含所有以001开头的哈希,依此类推。
mask_bits 参数的计算方式如下:
mask_bits = max(log2(num_items / max_items), 0.0)其中 num_items 是我们要插入到过滤器中的当前项目数:CrdsValue、已清除的值和失败的插入。max_items 是可以插入的最大项目数。
节点从其 crds 中收集已知对等节点列表,并过滤掉:
- 不活跃的对等节点(在过去 60 秒内没有收到来自该对等节点的消息)
- 具有不同分片版本或分片版本 != 0 的对等节点
- 具有无效 gossip 地址的对等节点
然后,将 CrdsFilter 集划分为单个 CrdsFilter。每个 CrdsFilter 都放入一个拉取请求中,并按如下方式通过加权随机混洗发送给选定的对等节点:
stake = min(node_stake, peer_stake[i])
weight = (log2(stake) + 1)^2其中:
node_stake- “我们”节点的股份,peer_stake[i]- 列表中第 i 个对等节点的股份。
节点的权重越高,发送给它的拉取请求就越多。
每个拉取请求都包含列表中的一个CrdsFilter,以及请求节点的ContactInfo,且以CrdsValue。节点的ContactInfo包含该节点(发送拉取请求)的详细信息——IP 地址列表、公钥和wallclock。
当一个节点接收到一个拉取请求时,在进一步处理之前,它先使用ContactInfo这个crds值来检查以下内容:
- 确保节点没有向自己发送拉取请求。
- 确保发送节点已经响应了
Ping消息。 - 检查wallclock值——如果它不在当前节点wallclock的15秒之内,则忽略该请求。
然后,该节点从crds表中收集自己的数据,并检查其持有的数据是否存在于提供的CrdsFilter中。
正如已经解释过的那样,CrdsShards结构保存了一个shards向量,该向量的元素是CrdsValue在crds表中的索引及其哈希值的索引映射。shards向量允许节点快速找到并过滤掉拉取请求发送者已经在其crds中的CrdsValue。
为简单起见,让我们假设shard_bits = 3、mask_bits = 3和mask = 001 = 1(实际上shard_bits = 12,但使用较少的位数更容易解释)。shards向量如下所示:
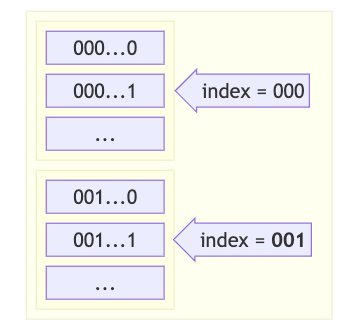
左列中的数字表示存储在shards向量中的CrdsValue的哈希值(以二进制形式)。存储在索引000的元素包含所有以000...开头的哈希值(以及crds表中CrdsValue的相应索引),索引001包含所有以001...开头的哈希值,依此类推。
来自拉取请求CrdsFilter的mask值等于001——这意味着我们需要从位于索引001的shards向量中获取所有元素。由于每个元素都包含哈希值和CrdsValue在crds表中的索引,因此我们可以快速找到crds中的实际CrdsValue。
当收集完所有CrdsValue后,会使用提供的布隆过滤器对其进行过滤。不存在于过滤器中的元素将发送回拉取请求发送者。
但是,可能存在mask_bits < shard_bits或mask_bits > shard_bits的情况:
mask_bits < shard_bits- 如果例如mask_bits = 2、shard_bits = 3和mask = 01,我们将查找所有以01开头的shards索引,例如010、011、012等等,并收集和过滤它们的所有元素
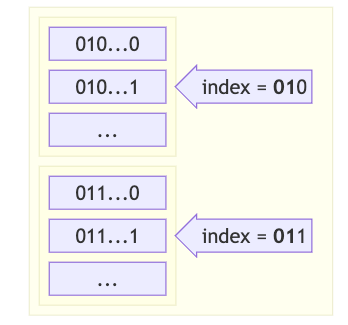
mask_bits > shard_bits- 如果mask_bits = 5,shard_bits = 3,mask = 00101- 首先我们搜索一个等于mask的前3位的shards索引,001,也就是1,然后从该索引中搜索以00101...开头的哈希值。
 在创建拉取响应之前,将对收集到的
在创建拉取响应之前,将对收集到的CrdsValue执行一些额外的检查:
- 针对拉取请求原始wallclock检查
CrdsValue的wallclock - 如果一个value是更新的将会会被跳过 - 如果一个 value 是下列数据类型之一:
LowestSlot,LegacyVersion,DuplicateShred,RestartHeaviestFork,RestartLastVotedForkSlots- 且是源于一个没有股份的节点将会被跳过
最后,所有剩余的CrdsValue的值将以一个拉取响应发送回拉取请求消息的发送方。
拉取响应
拉取响应包含一个CrdsValue列表,该列表使用拉取请求中提供的布隆过滤器进行过滤。这些是发送拉取请求的节点在其crds中缺少的值。
当一个节点接收到一个拉取响应时,它会处理拉取响应中包含的CrdsValue列表:
- 不存在于节点
crds表中的值,或者存在且具有更新的时间戳的值,将被插入到crds中,并且它们所有者的LegacyContactInfo时间戳会在crds中更新 - 具有过期时间戳的值也会被插入,但不会更新所有者时间戳
- 未插入到
crds中的过期值的哈希值(值以及存在更新的时间戳,或者值的所有者不存在于crds中)将被存储为failed inserts,以防止对等节点将其发回(它们在为下一个拉取请求构造布隆过滤器时使用)。 - 从
crds表中修剪的值(即,覆盖的值)被存储为purged values,并且还用于为下一个拉取请求构造布隆过滤器
注意:为了防止一个节点通过不断发送带有空CrdsFilter的拉取请求来对对等节点进行 DoS 攻击,对等节点限制了它们将插入到拉取响应中并发送回请求节点的数据量。
Ping 和 Pong 消息
节点会不时地 ping 其对等节点,以查看它们是否处于活动状态。他们创建一个包含随机生成的 32 字节Token的 ping 消息。接收 ping 的对等节点应在一定时间内回复一个包含接收到的 ping Token哈希值的 pong 消息。如果该对等节点未能响应,则它将不会收到来自 ping 它的节点的任何其他消息。否则,ping 消息的来源会将收到的 pong 存储在缓存中。
接收到Ping消息的节点应回复Pong响应,否则:
- 该节点的联系信息将被集群忽略。
- 该节点不应接收任何推送消息和拉取请求消息。
- 该节点发送的所有拉取请求都应被忽略。
Gossip 循环
gossip 循环是一个由节点在单独的线程中执行的无限循环。在此循环中,节点生成推送消息、拉取请求和 ping,同时还刷新其活跃节点集。
- 原文链接: github.com/eigerco/solan...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





