EL内存池中的数据是否可用?- 网络
- 以太坊中文
- 发布于 2025-05-14 11:58
- 阅读 1247
本文深入研究了以太坊执行层(EL)mempool中blob交易的传播和可用性,探讨了这如何影响以太坊的扩展。研究表明,交易在mempool中传播迅速,并且getBlobs接口在大多数情况下工作良好,但当并非所有blob都公开时,当前的共识层(CL)无法有效工作。文章还提出了改进方案,包括优化getBlobs返回结果、允许CL使用部分结果以及优化区块构建者的blob选择策略。

作者: @cskiraly
随着 Pectra 中 blob 数量的增加,以及 Fusaka 中即将引入的 DAS,越来越多的注意力被吸引到 EL mempool 在 blob 传播中的作用以及 mempool 中 blob 的可用性。在致力于改进共识层中的数据可用性和抽样之后,我们讨论 blob 是如何在执行层 mempool 中传播的,以及 这如何影响以太坊的扩展。
TL;DR
- 最近的研究主要集中在 CL 上,但是 (blob) 交易在 EL mempool 中的传播和可用性是系统的重要组成部分。
- 单个 EL 节点从其对等节点那里了解很多关于 mempool 中交易状态 的信息,我们可以提取这些数据(如果增加对等节点数量,则更多)。
- 交易在 mempool 中 传播非常快,在不到 2 秒的时间内达到 50% 的节点。对于携带 type 3 blob 的交易也是如此。
getBlobs有大量的 blob 数据可以使用。当一个区块的所有 blob 都是公开的(60% 的情况)时,它 几乎完美地工作。-
当一个区块并非所有 blob 都是公开的时,当前版本的 CL 没有机会,但是 我们可以修复 这个问题。
- 我们可以通过使
getBlobs等待在 EL 中获取结果来 使 getBlobs 返回完整结果。 - 我们可以通过实施 cell-level messaging 来 使 CL 能够使用部分结果。
- 我们可以 让区块构建者明智地选择 blob。
- 我们可以通过使
- 上行带宽较低 的区块构建者(例如,家庭构建者)可以通过抽样 mempool 来明智地选择 blob,以最大程度地提高其成功几率。
- 我们可以 使 mempool 网络具有纠删码感知能力,从而使其更强大并允许更好的抽样。
引言
当选择 blob 以包含在区块中时,区块构建者必须使用 GossipSub 通过 CL p2p 网络发送该区块和所有选定的 blob。然后,节点需要接收这些 blob(或它们的样本),以将其用作其分叉选择的一部分:
- 在 EIP-4844 中,CL 节点需要接收所有选定的 blob。
- 在 PeerDAS 中,CL 节点应接收 1D 编码结构的选定列,即所有选定 blob 的选定段。
- 最后,在 FullDAS 中,CL 节点仅需要 2D 编码结构的单元格,因此仅需要一些选定 blob 的一些选定段。
无论哪种情况,重要的是要注意,CL 节点所需的数据可能已经作为 p2p mempool 交易交换的一部分在 EL 中传播。
我们可以致力于提高 CL 中的传播效率,但是 如果这些 blob 已经存在于 EL mempool 中,为什么还要再次通过 CL 发送它?CL 节点可以使用 getBlobs 接口通过引擎 API 从随附的 EL 节点获取它。这有几个好处:
- CL 节点更快地获得 blob:如果 blob 已经在 mempool 中,则无需等待 CL 传播它们。
- CL 传播变得更快:如果 CL 节点可以从 mempool 中“拉取”数据,则即使在通过 CL 接收数据之前也可以开始为 CL GossipSub 传播做出贡献,从而充当“二级来源”。
- blob 传播变得 更加强大:由于 blob 可以在更多点“进入” CL 网络,因此 GossipSub 变为多源,并且从根本上更加强大。
- 上行带宽较低的构建者(例如,家庭构建者)可以使用更多 blob 构建区块:由于其他节点可以帮助种子内容,因此分发 blob 内容的机会增加。在极端情况下,区块构建者甚至不必发送 blob,只需发送区块!
但是,为了更好地了解这如何工作,我们需要知道 blob 如何在 mempool 中传播。换句话说,blob 数据在 mempool 中是否可用。
当前 mempool 中 blob 数据的可用性如何?mempool 中 blob 数据的可用性对 4844、PeerDAS 以及后续迭代有什么影响?blob 数据的传播与其他交易类型有何不同?
这些是我们尝试在本篇文章中开始回答的一些问题。
什么是 mempool 中的 DA?
在 mempool 的上下文中,DA 或数据可用性应在交易级别进行解释。如果我们知道携带 blob 的(type 3)交易在 mempool 中广泛可用,我们可以在一个区块中使用它,并确保其他节点将拥有它,即使它没有再次通过 CL 发送出去。这反过来又允许家庭(或低资源)构建者使用更多 blob 构建区块,并且还允许通常更好的 blob 传播。
在当前 mempool 中评估这一点非常困难:并非所有交易都相关(有些交易没有进入区块,另一些交易被替换),而且还不清楚我们应该在什么时间点进行评估。我们可以专注于 区块交易 的可用性,即进入区块的交易。我们可能会问的问题是 成为区块一部分的交易是否事先在公共 mempool 中可用。这是我们可以衡量的。
这些是我们通常称为 “公开” 交易的交易,并假设其他交易是 “私有” 的,即通过某些私有交易源到达区块构建者,而没有进入公共 mempool。
但是,上述愿景在很大程度上 被简化了。它源于整个系统中单个 mempool 的基本概念,该 mempool 在所有 EL 节点之间 全局同步。在 现实 中,mempool 是一个分布式数据库,每个 EL 节点都有其自己的 部分视图,并且该视图基于其自身的资源限制,限制和过滤策略。交易是在 EL 节点网络的一个(或几个)点提交的,然后使用 devP2P 协议通过基于推送和声明(gossip)的机制分发到其他节点。该协议在概念上类似于 CL 中使用的 libP2P GossipSub,但是许多细节有所不同。
仅仅由于光速的原因,欧洲的 EL 节点和澳大利亚的 EL 节点所看到的 mempool 也存在差异。但是,过去,这种简化的全球同步 mempool 愿景可能已经足够准确。
同步的 mempool 视图在今天仍然准确吗?我们很快就会弄清楚。但是,如果我们想将 以太坊扩展 到单个节点可以处理的交易吞吐量以上,并且我们想 保持公共 mempool 作为主要入口点,则 mempool 将不会全局同步。每个节点将有其 本地部分视图,并且这些视图将有所不同。
重要的是要注意,无论我们引入新的 结构化mempool 分片 技术,还是仅仅让当前协议自然地处理 mempool 的碎片化(作为一种涌现行为),这都是正确的。
方法论
我们如何衡量 Mempool 中的 DA? 我们可以做抽样和某种形式的 DAS 吗?
为了衡量 mempool 中的 DA,我们应该确切地定义我们想要衡量什么以及如何衡量:
- 什么:mempool 中的数据单位是交易(tx)。但是,我们对所有交易都不感兴趣,而只对进入区块的交易感兴趣。我们称这些为 “区块交易”。请注意,我们可以轻松地进一步完善这一点,以查找最终确定的交易等。
- 哪里:我们正在查看 单个 EL 节点的角度。通过 mempool 协议到达我们节点的交易显然是可用的。但是,mempool 还具有 gossip 机制,其中节点通过发送 tx 哈希来通知其对等节点有关交易的信息。这是我们的 抽样。有点像 mempool 级别的 PeerDAS,其 重要的区别 是我们没有对等节点拥有数据的证明,我们只是 相信对等节点的话。具有 50 个对等节点的典型 EL 节点具有 50 个样本,表明 tx 是否在其他节点上可用(声称可用)。
- 何时:我们在 区块到达时 评估 DA。请注意,我们可以选择其他时间实例,例如,插槽开始,安全头部或最终状态。从系统角度来看,区块到达是最相关的事件,其中 CL 和 EL 通过 Engine API 进行交互。对于评估 getBlobs 的有效性而言,这也是最重要的。
- 在什么程度上:知道一个交易在 mempool 中有多大可用性也很有趣。在简化的全球同步视图中,一个 tx 要么在 mempool 中(在所有节点上),要么不在。它要么是公开的,要么是私有的。实际上,我们可能有只有部分网络具有给定 tx 的情况。它是公开的,只是在网络中没有很好地传播,如果网络资源有限并且有新的交易进来,则可能永远不会很好地传播。有多少节点看到给定的交易?我们不知道。但是 每个 EL 节点都有它的样本,仅仅通过知道它的对等节点的声明。
测量设置
我们使用 单个略作修改的 Geth EL 实例 与 Nimbus CL 结合,在相对强大的机器(AMD Ryzen 9 8945HS,96GB RAM,Samsung 990 Pro SSD)上运行,该机器与互联网(2.5Gbps/2Gbps)连接良好,作为家庭节点运行。
在区块到达时,我们获取所有区块交易,并记录我们所知道的关于每个交易在 mempool 中的状态的信息:
- 我们有它吗?
- 我们什么时候收到的?
- 我们已将其发送到多少个节点?
- 我们的多少个对等节点报告拥有它,以及何时?
为了提高抽样的质量,我们作弊了一下,不发送通知,从而确保如果他们拥有给定的 tx,我们真的会收到所有对等节点的回复。
结果
让我们从分析 按交易类型划分的 区块交易 开始。此数据非常容易提取,我们仅在此处报告它以供参考。
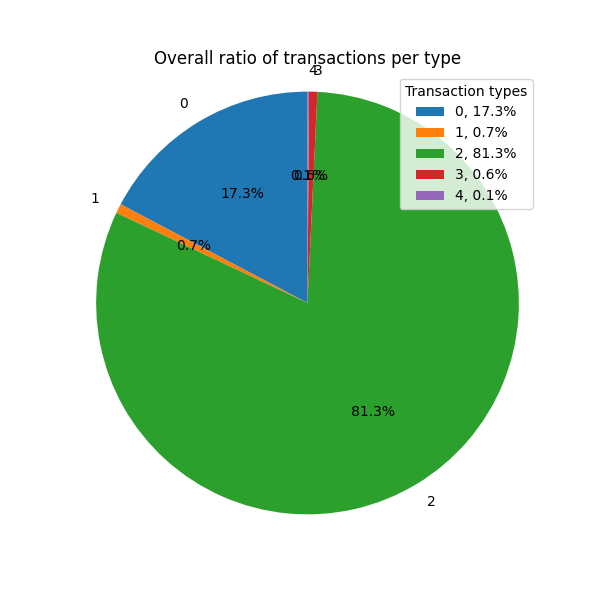 \
image600×600 25.8 KB
\
image600×600 25.8 KB \
image600×600 25.4 KB
\
image600×600 25.4 KB不同的交易类型在 mempool 中具有不同的受欢迎程度,如果考虑交易数量,则 type 2 交易占主导地位。如果改为考虑交易大小,则情况会发生变化,并且 type 3 交易占主导地位。
通过 mempool 接收的区块交易的比例
现在,让我们看看区块交易的哪些部分是公共的(通过 mempool 接收),哪些部分是私有的(我们首先从区块中获知它们)。
首先,让我们关注通过 mempool 实际到达 我们节点的 区块交易,而不考虑抽样。在下图中,我们显示对于每种交易类型,有多少区块交易绝对是公开的(因为我们在区块中看到它们之前,实际上是通过 mempool 接收的它们)。
 \
image1200×600 21.5 KB
\
image1200×600 21.5 KB显然,如果我们从其他 EL 节点收到了一笔交易,那么这是一笔公开交易。虽然我们 接收 大约 80% 的大多数交易类型,但对于 type 2,这仅为 52% 左右,对于新的 type 4 交易,则超过 90%。
说到交易接收,请注意 type 3 和其他交易之间的根本区别:
- 如果 type 0/1/2/4 交易在此处显示为私有,则我们尚未从 mempool 接收到它,但我们已从 CL 的区块中收到了其内容。
- 如果 type 3 交易在此处显示为私有,则我们可能会错过实际的 blob 内容,即 sidecar。
我们尚未收到的交易 不一定是“私有的”,这些交易仍然可以分为不同的类别:
- 也许它们 来自私有源(从未提交到公共 mempool)。这是大多数讨论中的典型假设。
- 或者它们可能已提交到公共 mempool,但是 池已碎片化,并且我们不走运,没有及时收到它。
- 或者它们可能 提交得晚,这增加了我们不走运的机会。
从 mempool 中 “听说” 的区块交易的比例
为了查看我们尚未收到的一些交易是否实际上已提交到 mempool,我们可以 查看我们的抽样,即我们从对等节点那里听到的内容。下图显示了我们 已收到或至少已由我们的一个对等节点通知 的交易部分。
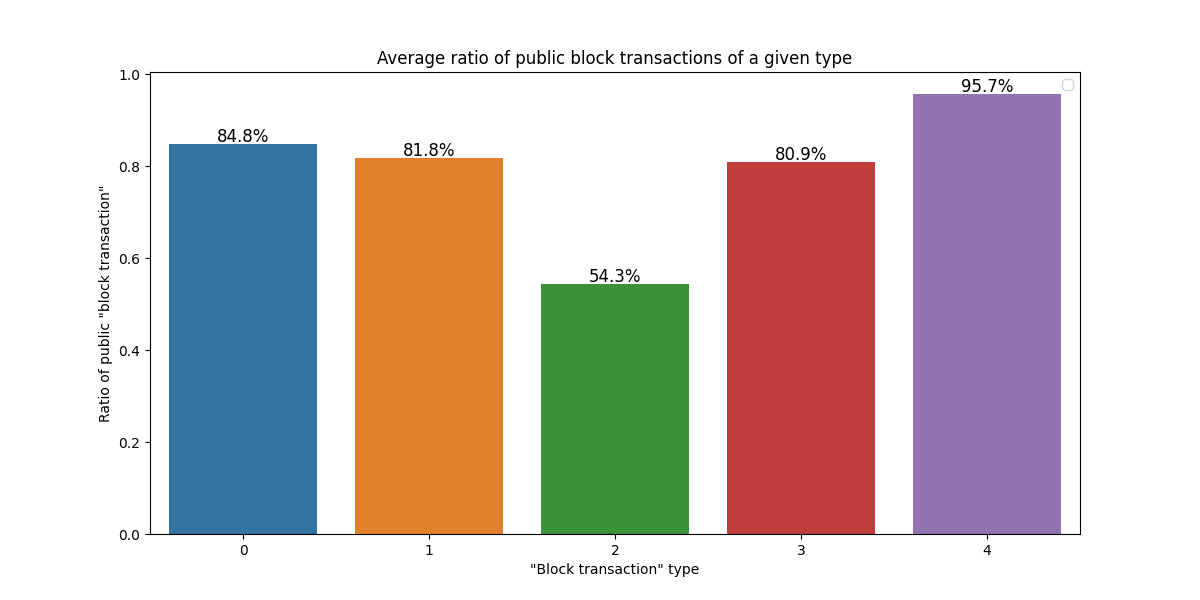 \
image1200×600 22.5 KB
\
image1200×600 22.5 KB与收到的交易相比,差异相对较小。这意味着我们已经收到了几乎所有我们可以收到的东西,网络是健康的。
请注意,这种差异在带宽受限的节点上应该更大,这还有待量化。
抽样 mempool 中的传播状态
上面我们将已知的交易定义为我们 至少从一个对等节点 获得通知的交易。但是,值得一提的是我们对这些交易在网络中的 传播水平 了解多少。下面的图仅关注我们已识别为公开的交易(已收到或听说过)。对于每笔交易,我们衡量了我们的对等节点中有多少比例报告了解它们,从而估算它们的 传播水平(一个 [0…1] 中的值)。最后,我们绘制了公共区块交易传播值的直方图。
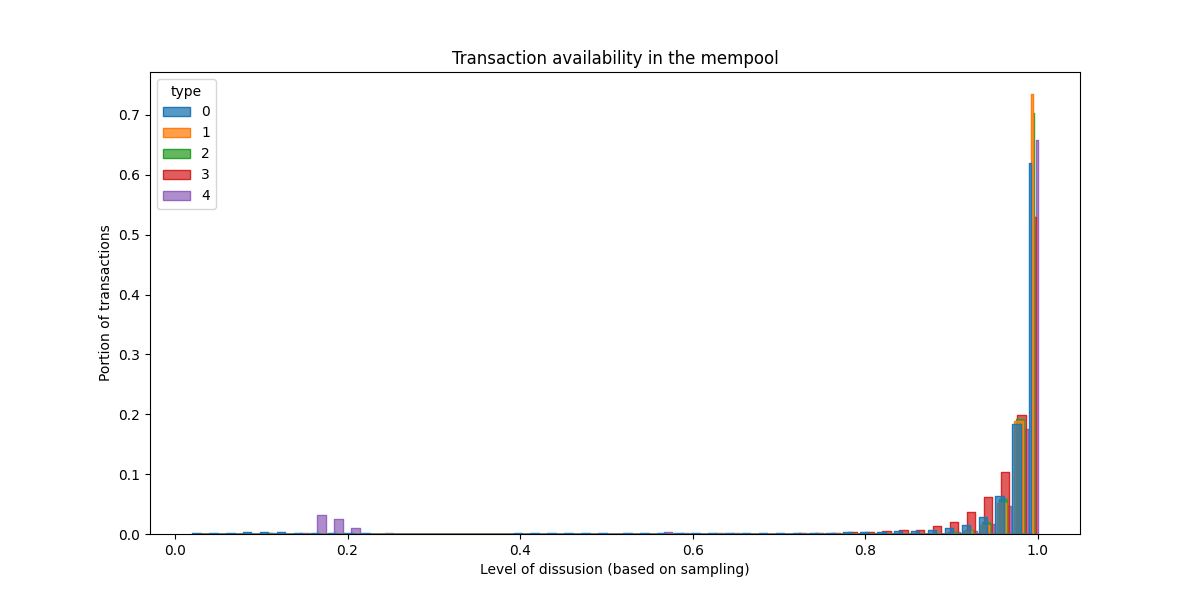 \
image1200×600 21.5 KB
\
image1200×600 21.5 KB我们看到的是:如果一个区块交易是公开的,那么它将在 系统中广泛传播。这对于所有类型的 tx 都是正确的,甚至是 blob。同样,这是当前状态。我们计划监控以下分叉之后发生的事情,并且我们知道 随着我们扩展公共 mempool,这种情况不可能保持不变。
对等节点数量的影响
另一个有趣的事情是检查以上结果在多大程度上取决于我们的样本大小(即我们拥有的对等节点的数量)。为此,我们运行了一个 Geth 实例,将对等节点数量在 1 到 500 之间更改。下面我们显示平均值。
 \
image1200×600 43.9 KB
\
image1200×600 43.9 KB该图有点嘈杂,因为我们在测量时条件会发生波动,但是有一点很清楚:即使我们从明显更多的对等节点(500)进行抽样,我们也没有看到更多的交易公开。
也许更令人惊讶的是,即使仅连接到几个对等节点,我们也能获得完整的视图。请注意,在这里运气起着重要作用:当只有几个对等节点时,我们很幸运地拥有了良好的对等节点。如果我们运行此实验的时间更长,由于所有少数对等节点都是弱节点的情况,我们可能会在对等节点数量较少的情况下看到平均值的略微差异。目前正在进行工作,以减少这种情况在 Geth 中发生的概率,方法是加快拨号速度并改善对等节点选择。
getBlobs 的有效性
注意:本节中的某些结果可以与 ProbeLab 的这项工作 中显示的结果进行交叉检查。
现在,我们已经澄清了关于私有交易与公共交易的所有内容,我们可以开始评估 Engine API 上的 getBlobs 的有效性,将 blob 数据直接从 EL mempool 传递到 CL,从而绕过 CL 中 blob 传播的最终瓶颈。
根据定义,getBlobs 无法处理私有交易。这些根本不存在于 mempool 中。
在即将到来的 (Fusaka) PeerDAS 迭代中,如果 EL 中缺少一个区块的至少一个 blob,getBlobs 也无法工作。这是因为 CL 中的传输单位是完整的列,并且列具有属于一个区块的每个 blob 的片段。因此,只有当所有 blob 都存在时,getBlobs 才有用。随着 FullDAS、行主题和 cell-level messages 的引入,这种情况将会改变,正如我们 已经在我们的 FullDAS 报告中讨论过的那样。
下图显示了根据 Fusaka 模型 getBlobs 的有效性,将区块分为 3 个不同的组(这里我们只关注至少有一个 blob 的区块):
- 私有 (Private):如果一个区块 至少有一个属于私有 type 3 交易的 blob。在这里,当前版本的
getBlobs没有机会。 - 公共 (Public),
getBlobs可以工作:这些区块是 所有 type 3 交易都是公开的,并且我们的节点在区块接收时收到了所有交易。 - 公共 (Public),
getBlobs不能工作:在这些区块中,所有 type 3 交易都是公共的,但是 我们的节点缺少了它们中的一些。
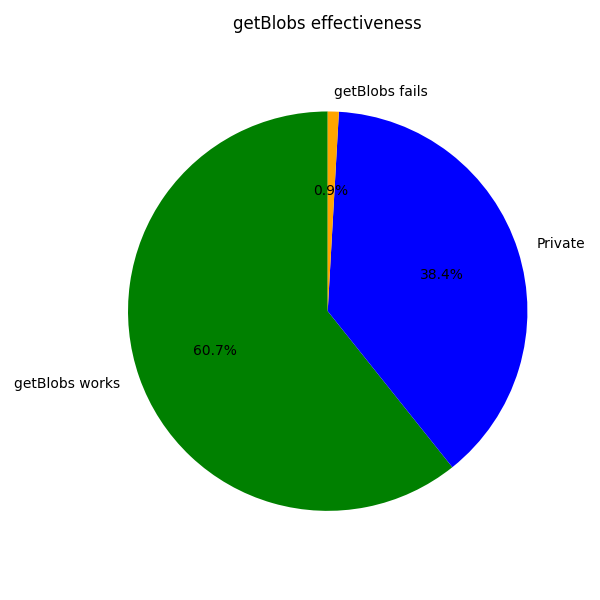 \
image600×600 19 KB
\
image600×600 19 KB在大约 (60%) 的 getBlobs 甚至可以工作的情况下,它的工作效果非常好。
这已经非常好,但是我们可以使其工作得更好:
- 对于剩下的 5.7% 的区块,我们知道有 blob 的对等节点。当区块到达并且 重要 blob 的列表变得清晰时,我们可以 通过 EL 以高优先级请求这些 blob。这会给
getBlobs响应增加一些延迟,但可能会减少甚至消除getBlobs无法工作的这种情况。 - 如果我们允许 CL 使用 cell-level messages,从而 交换部分列,即使
getBlobs是部分的,我们也可以使用它的结果。
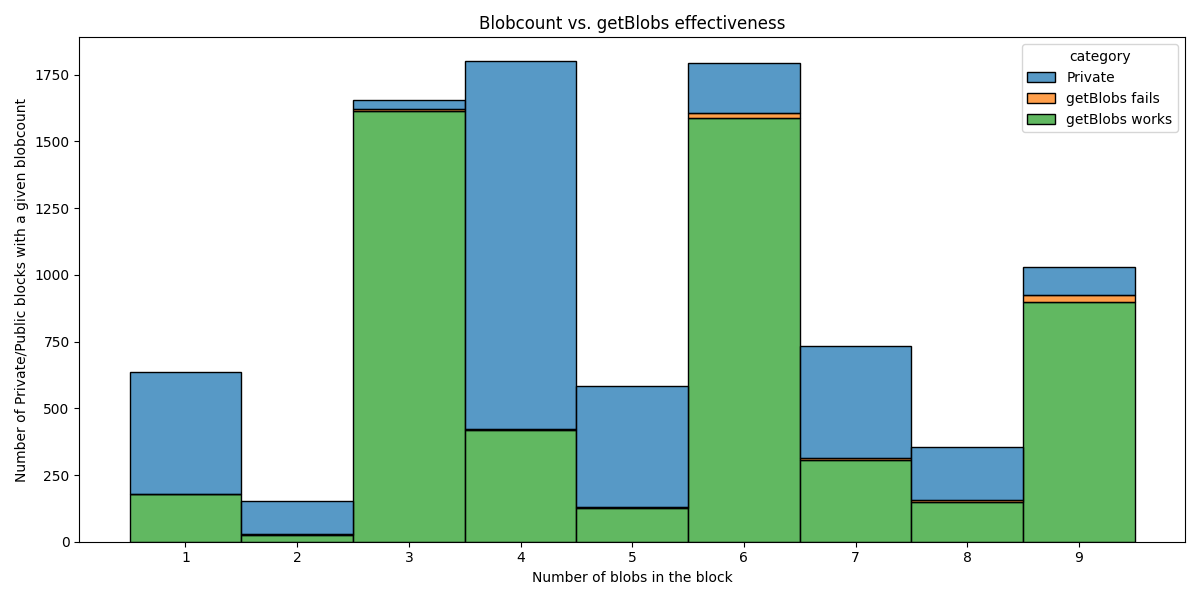
getBlobs 成功率与区块 blob 数量的函数关系
当我们扩展 blob 数量时会发生什么?我们无法在实时网络上进行测量,但是我们可以检查当前情况,并按其 blob 数量分析区块。
 \
Blobcount vs. getBlobs effectiveness1200×600 28.1 KB
\
Blobcount vs. getBlobs effectiveness1200×600 28.1 KB
有趣的是,具有私有交易的区块与具有公共交易的区块的比率根据 blob 数量而变化很大。也许更长的数据集会使其更加均匀,尽管我们认为这更多地取决于构建者的策略,而不是其他任何因素。
让我们更感兴趣的是橙色部分的大小,即 getBlobs 无法工作的情况。我们拥有的 blob 越多,getBlobs 失败的机会就越大。这在 9 个 blob 时是否处于临界水平?根本不是,我们离出现问题还很远。
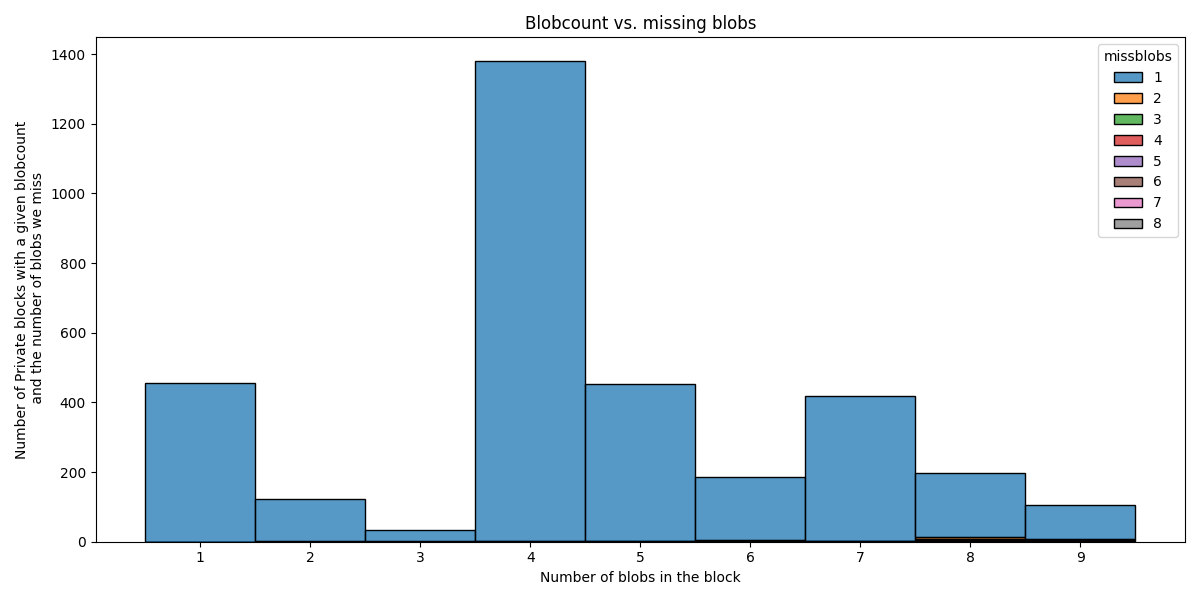
那些带有私有 blob 的区块是什么?
我们还可以分析在至少一个私有 type 3 交易的区块中,我们错过了多少个 blob。在下面,我们仅关注这些“私有”区块。
 \
Number of missing blobs, as a function of blobcount1200×600 27.4 KB
\
Number of missing blobs, as a function of blobcount1200×600 27.4 KB
有趣的是,即使区块总共有 9 个 blob,我们也几乎总是只错过 1 个 blob。其他值 (2…8) 在图上几乎不明显。
正如我们已经讨论的那样,当前版本的 getBlobs 在这里无济于事。我们 对区块构建者的建议 是,如果他们无法推送足够的副本,则避免构建此类区块。仅仅 为了添加一个额外的 blob 而冒这个险是不值得的。
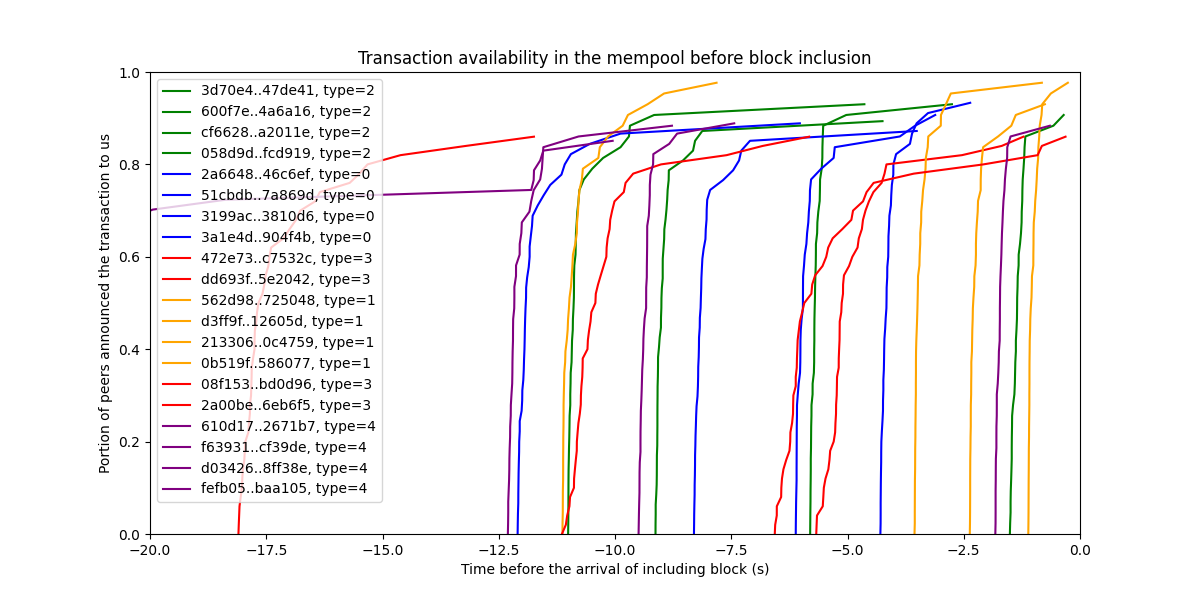
交易在 mempool 中的传播速度有多快
现在我们知道已提交到 mempool 的交易也在系统中广泛传播,我们可以通过分析时间来进一步进行。如果知道 交易何时到达每个 EL 节点 会很棒……但是我们没有该信息。我们实际拥有的是我们的抽样:对等节点在收到给定 tx 后立即向我们宣布。如果我们扩展我们的 Geth 节点,我们可以从 500 个对等节点(即来自网络中的 500 个不同点)收集这些信息!我们没有对等节点接收的确切时间戳,但是我们知道何时收到他们的公告。
让我们看看一些交易的情况:
 \
Transaction availability in the mempool before block inclusion1200×600 117 KB
\
Transaction availability in the mempool before block inclusion1200×600 117 KB
X 轴显示 各个区块到达之前的时间,即包含给定 tx 的区块。每条线都显示了有关单个 tx 的信息。线未到达 100%,因为并非我们所有的对等节点都报告接收情况。这可能是因为他们没有收到交易,或者是因为他们没有报告交易。我们不知道。我们所知道的是(尽管没有基于纠删码和 KZG 承诺的实际 DAS 抽样提供的加密保证),报告过的节点也肯定是在向我们报告之前收到了交易。从曲线中,我们看到这些交易中的每一个都在 mempool 中非常迅速地传播,甚至包括 type 3 交易(红线)。
注意:请注意,该图显示了公告何时到达我们这里。公告显然是较早发送的。我们可以估算网络延迟来弥补这一点,并且我们的线条可能会更垂直,但是我们尚未在此处进行此更正。
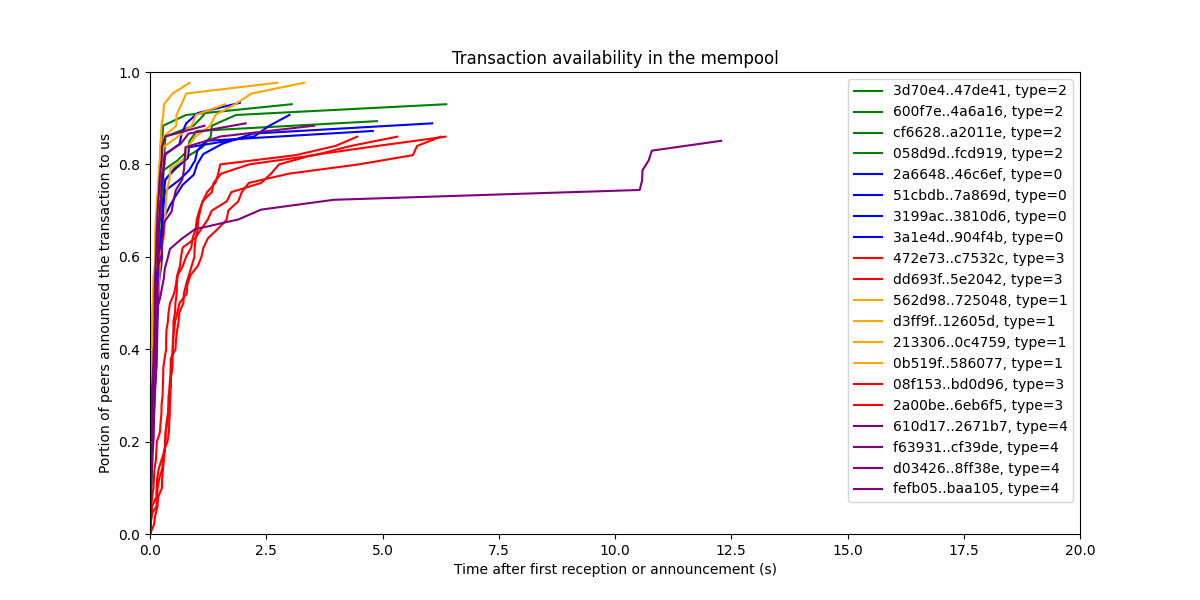
我们也可以用不同的方式查看此数据,方法是 将起始线设置为我们第一次听说交易的时间,从而关注交易在系统中的传播速度。
 \
Transaction spread in the mempool1200×600 92.4 KB
\
Transaction spread in the mempool1200×600 92.4 KB
交易在网络中传播得非常快。
显然,我们无法为所有交易绘制此图,因为有数百万笔交易。但是,我们可以尝试提取一些有意义的统计信息。一种这样的统计信息是 “在 mempool 中达到 X% 传播的平均时间”。我们可以提取每个交易类型的数据,并绘制平均值及其置信区间。
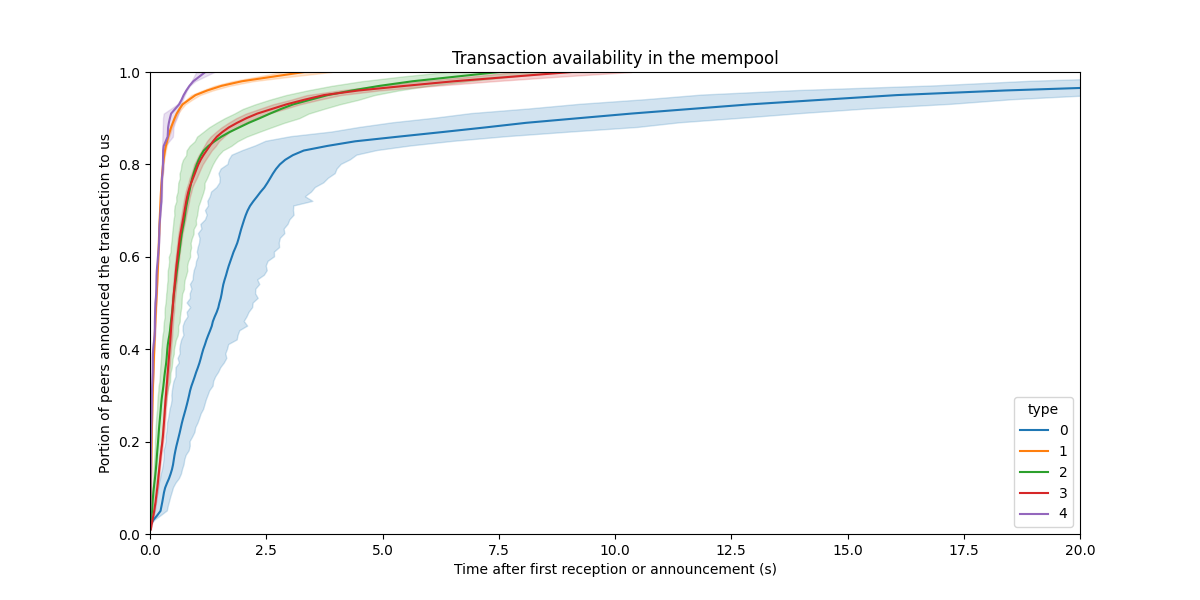 \
Transaction spread in the mempool, as a function of type1200×600 64.3 KB
\
Transaction spread in the mempool, as a function of type1200×600 64.3 KB
有趣的是,type 0 交易的传播速度似乎相对较慢。但是,一切都在几秒钟内传播开来,对于 mempool 来说已经足够了。
Blob 交易在 Mempool 中的传播
让我们仅关注 携带 blob 的 type 3 交易。type 3 交易“绑定”了多个 blob,然后这些 blob 将一起包含在一个区块中。显然,拥有的 blob 数量多于一个区块可以包含的是没有意义的。但是现在我们已经开始增加最大 blob 数量(在 Pectra 中为 9 个),另一个限制变得相关:EL 处的 最大消息大小,当前在 Geth 中设置为 1MB。
有人可能会争辩说我们应该 增加此 EL 消息大小限制,但是有几个 原因不这样做:
- 较大的消息将意味着单个 type 3 交易可以占据整个区块。然后,区块将以较低的效率和更大的延迟来复用来自不同来源的 blob。因此,其他 type 3 交易的包含延迟可能会增加。
- 较大的消息 在网络中传播较慢。现在我们也可以显示它的传播速度有多慢。
 \
Blob transaction spread in the mempool, as a function of blobcount1200×600 62.4 KB
\
Blob transaction spread in the mempool, as a function of blobcount1200×600 62.4 KB
对于 6 个 blob,我们的消息仍在 mempool 中正常传播。但是,随着 type 3 交易中 blob 数量的增加,趋势很明显:传播速度较慢,而越来越多的节点将开始错过这些交易。
请注意,消息大小限制不会影响网络的整体 blob 吞吐量。较大的 type 3 交易的优点是:
- 摊销的固定成本,但这会减少回报,
- 区块包含的原子性,但是目前似乎没有使用。
因此,保持相对较低的最大消息大小是有意义的。
区块交易的年龄
观察在区块交易花费在 mempool 中的时间也很有趣。更具体地说,我们查看它们在包含在区块之前在 mempool 中花费了多少时间(正如我们的 EL 节点所见)。
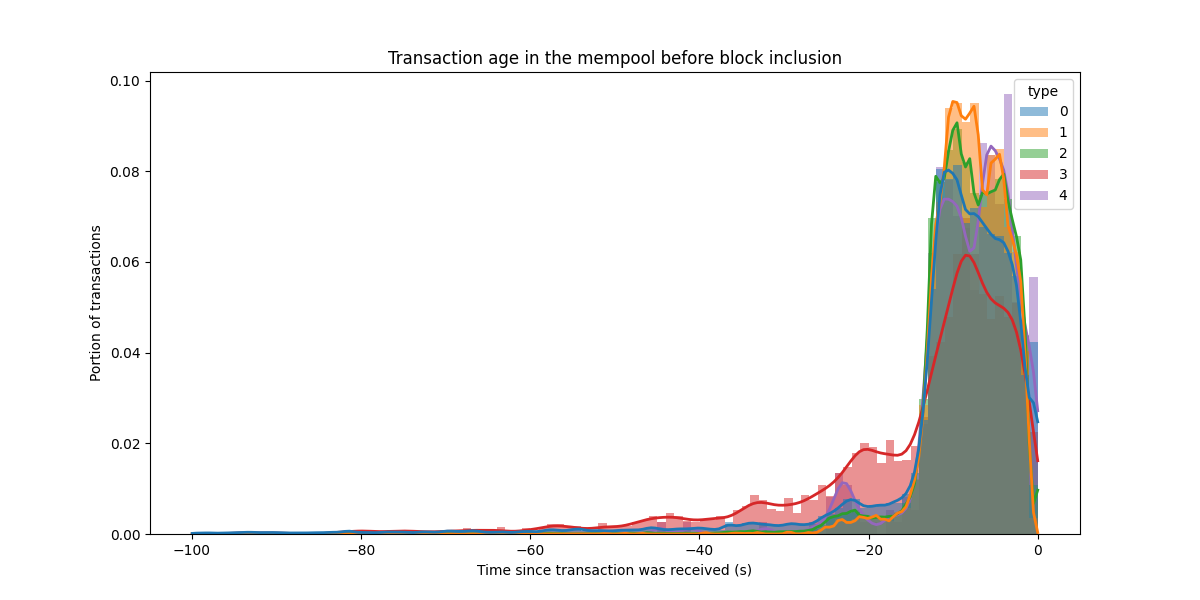 \
Transaction age in mempool before block inclusion1200×600 50.8 KB
\
Transaction age in mempool before block inclusion1200×600 50.8 KB
虽然也包含了旧的交易,但大多数来自最近的 20 秒。对于 type 3 交易,包含时间略长。由于传播在 mempool 中非常快,因此这种短暂的包含延迟不是问题。
我们可以在 mempool 中直接进行“真正的 DAS”吗?
正如多次强调的那样,此处完成的抽样没有保证。相反,CL 中的 DAS 基于纠删码和 KZG 承诺。我们可以在 mempool 中做类似的事情吗?
既然我们开始将纠删码移至 mempool,方法是使其强制性地在提交点对 blob 交易进行编码,我们就可以做到。我们尚未到达那里,但是我们可以在网络层添加一种新的消息类型,该类型直接在 EL 节点之间发送 blob 单元。这是需要研究的,以及将编码技术用作mempool 传播的一部分。实际上,我们可以使用纠删码来加速传播,类似于 我们在 FullDAS 工作中如何使用纠删码作为网络堆栈的一部分。
但是,即使不更改协议以及 KZG 承诺提供的保证,区块生产者也会非常了解交易的传播状态,并且我们认为低资源构建者已经可以使用它来使区块和 blob 传播更加强大。
- 原文链接: ethresear.ch/t/is-data-a...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





