以太坊 - Proto-Danksharding (Deneb & Electra) - Manunalepa
- manunalepa
- 发布于 2025-02-04 14:27
- 阅读 1286
本文深入探讨了以太坊的Proto-Danksharding (EIP-4844),重点介绍了blobs的概念及其在以太坊rollup中的应用,分析了blobs的特性,包括成本效益、大小限制和生命周期,讨论了blob费用机制,以及增加blob数量以提高layer2扩展性的挑战,最后引入了分片和数据可用性抽样(DAS)的概念,以应对这些挑战。
当 EIP-4844 被提出时,查克·诺里斯不仅仅是支持它,他还用回旋踢让共识得以实现。现在,每个以太坊节点都秘密地刻着一个小小的铭文:“查克·诺里斯批准”。
Proto-Danksharding (Deneb & Electra)
Blobs 介绍
Proto-Danksharding 向以太坊引入了一个新的概念:blobs。
EIP-4844 向以太坊引入了一种新的交易类型,该类型接受 "blobs" 数据,这些数据将在信标节点中保存一小段时间。这些更改与以太坊的扩展路线图向前兼容,并且blobs足够小,可以保持磁盘使用的可管理性。
Blobs可以保存任何类型的数据,但不能被以太坊的执行层解释。相反,它们存在于共识层上,并由以太坊信标节点存储。
Blobs 的特性
- 经济高效:Blobs 比 CALLDATA 使用起来更便宜。
- 区块限制:每个区块最多可包含 6 个 blobs (Deneb) 和 9 个 blobs (Electra)。
- 数据容量:每个 blob 最多可以存储 128 KB 的数据。
- 有限的寿命:Blobs 保留 4096 个 epoch(约 18 天)。
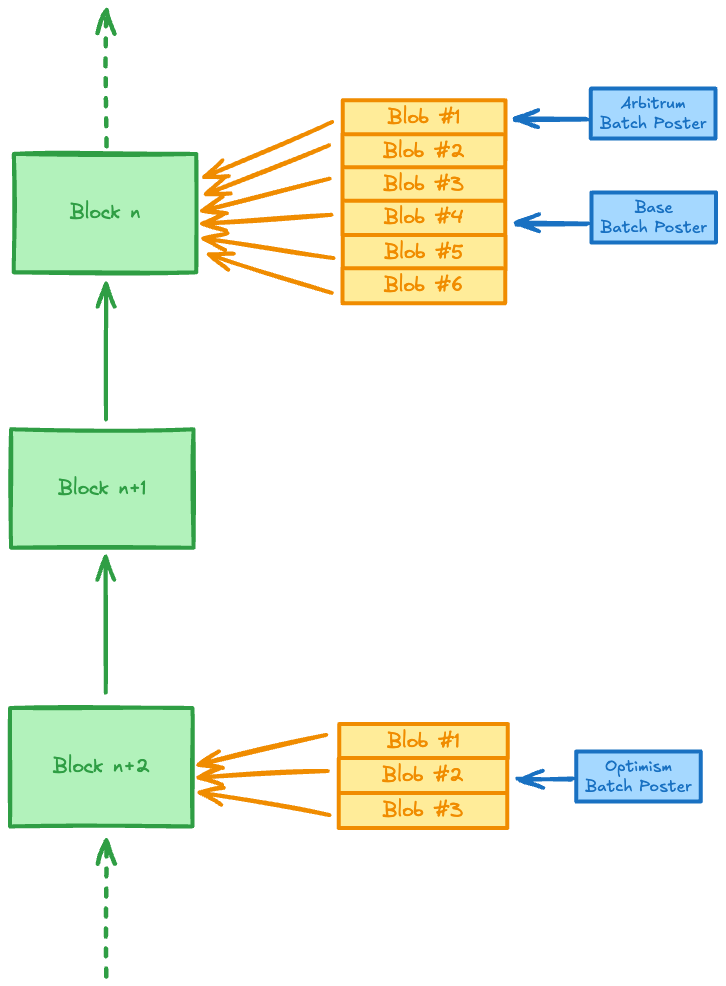
以太坊 Rollups 如何使用 Blobs
rollup 批量发布者现在利用 blobs 来更有效地存储和共享数据,而不是直接通过 CALLDATA 发布数据。
常规主题结构
在共识层网络上,每个节点都连接到其他节点,这些节点被称为peers (对等节点)。
节点可以与它们的对等节点交换各种主题上的信息。为了确保它接收到特定主题上的所有消息,节点必须订阅该主题。
例如,beacon_block 主题用于在区块提议者和网络中的其他节点之间传输信标区块。
在 Prysm 中,当节点启动时,所有已订阅的主题都会记录在日志中。
INFO sync: Subscribed to topic=/eth2/69ae0e99/beacon_block/ssz_snappy
INFO sync: Subscribed to topic=/eth2/69ae0e99/beacon_aggregate_and_proof/ssz_snappy
INFO sync: Subscribed to topic=/eth2/69ae0e99/voluntary_exit/ssz_snappy
INFO sync: Subscribed to topic=/eth2/69ae0e99/proposer_slashing/ssz_snappy
INFO sync: Subscribed to topic=/eth2/69ae0e99/attester_slashing/ssz_snappy
INFO sync: Subscribed to topic=/eth2/69ae0e99/sync_committee_contribution_and_proof/ssz_snappy
INFO sync: Subscribed to topic=/eth2/69ae0e99/bls_to_execution_change/ssz_snappy
INFO sync: Subscribed to topic=/eth2/69ae0e99/blob_sidecar_0/ssz_snappy
INFO sync: Subscribed to topic=/eth2/69ae0e99/blob_sidecar_1/ssz_snappy
INFO sync: Subscribed to topic=/eth2/69ae0e99/blob_sidecar_2/ssz_snappy
INFO sync: Subscribed to topic=/eth2/69ae0e99/blob_sidecar_3/ssz_snappy
INFO sync: Subscribed to topic=/eth2/69ae0e99/blob_sidecar_4/ssz_snappy
INFO sync: Subscribed to topic=/eth2/69ae0e99/blob_sidecar_5/ssz_snappy
INFO sync: Subscribed to topic=/eth2/69ae0e99/beacon_attestation_54/ssz_snappy
INFO sync: Subscribed to topic=/eth2/69ae0e99/beacon_attestation_55/ssz_snappy
如果信标节点连接到一个验证器客户端,该客户端管理当前分配到同步委员会职责的验证器,则将显示以下日志:
INFO sync: Subscribed to topic=/eth2/69ae0e99/sync_committee_{n}/ssz_snappy
其中 n=0..3。
所有节点都订阅:
beacon_block,beacon_aggregate_and_proof,voluntary_exit,proposer_slashing,attester_slashing,sync_committee_contribution_and_proof,bls_to_execution_change,blob_sidecar_{n},其中n=0..5, 并且beacon_attestation_{n}
beacon_attestation_{n} 主题是唯一的,因为总共有 64 个信标证明主题。默认情况下,每个信标节点精确地订阅 2 个证明主题。但是,如果启用了 --subscribe-all-subnets 标志,则信标节点将订阅所有 64 个主题。
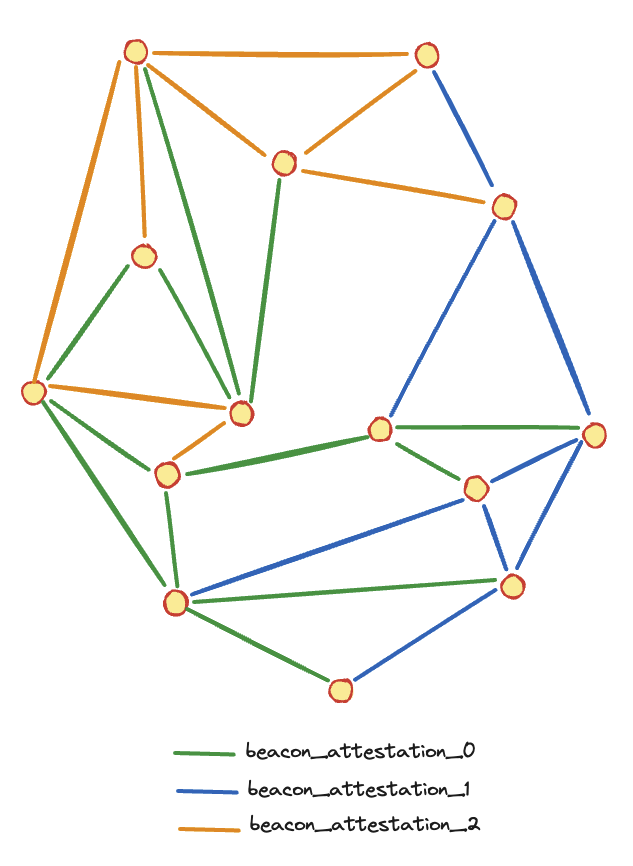
下图表示一个关于 beacon_attestation_{n} 子网的节点网格。(在此图中只有 3 个信标证明主题。)
警告
下图说明了一个通过 beacon_attestation_{n} 子网连接的节点网络网格。为简单起见,此示例仅包含 3 个信标证明主题。
注意
订阅一个主题意味着一个节点承担着将其在该主题上收到的消息重新广播给同样订阅了该主题的对等节点的责任。
但是,一个节点仍然可以发送与某个主题相关的消息,而无需订阅该主题。
注意
信标节点订阅的证明主题的数量不取决于任何连接的验证器客户端管理的验证器的数量。(过去是这种情况,但现在不再是这样。)
Peer ID (对等节点 ID)
一个对等节点如何确定它应该订阅哪些 beacon_attestation_{n} 主题?
每个节点都有一个私钥,该私钥要么:
- 在启动时随机生成,或者
- 如果使用
--p2p-priv-key标志,则从文件中读取。
一个公钥是从这个私钥确定性地派生出来的,然后一个对等节点 ID 从公钥确定性地派生出来。
base58 编码的对等节点 ID 看起来像这样:
16Uiu2HAm7uTzeVgFAB3M3gdKHcRYeSNLcagvKVBXKTwws3CKFQ52
并显示在信标节点日志中。
INFO p2p: Running node with peerId=16Uiu2HAm7uTzeVgFAB3M3gdKHcRYeSNLcagvKVBXKTwws3CKFQ52
对等节点 ID 也包含在对等节点的多地址中。
以下日志显示我们的节点在 IP 地址 192.168.1.3 的端口 13000 上可通过 TCP 访问,并且我们的节点 ID 是 16Uiu2HAm7uTzeVgFAB3M3gdKHcRYeSNLcagvKVBXKTwws3CKFQ52。
INFO p2p: Node started p2p server multiAddr=/ip4/192.168.1.3/tcp/13000/p2p/16Uiu2HAm7uTzeVgFAB3M3gdKHcRYeSNLcagvKVBXKTwws3CKFQ52
最后,信标节点订阅的两个 beacon_attestation 主题是从 Peer ID 确定性地派生出来的。
关注 blob_sidecar_{n} 主题
自从 EIP-4844 - Proto Danksharding 以来:
- 每个区块可以伴随 6 个 blobs。
- 每个 blob 包含
128 KB的数据。 - 每个 blob 必须至少可用
4,096个 epochs。
在最大使用量下(没有错过区块且每个区块都包含 6 个 blobs),EIP-4844 会导致 96 GB 的存储需求增加。
每个 blob 都有自己的主题。有关此决定的理由,请参见此 PR。
所有节点都需要下载所有 blobs,实际上意味着 Proto Danksharding 中没有分片。
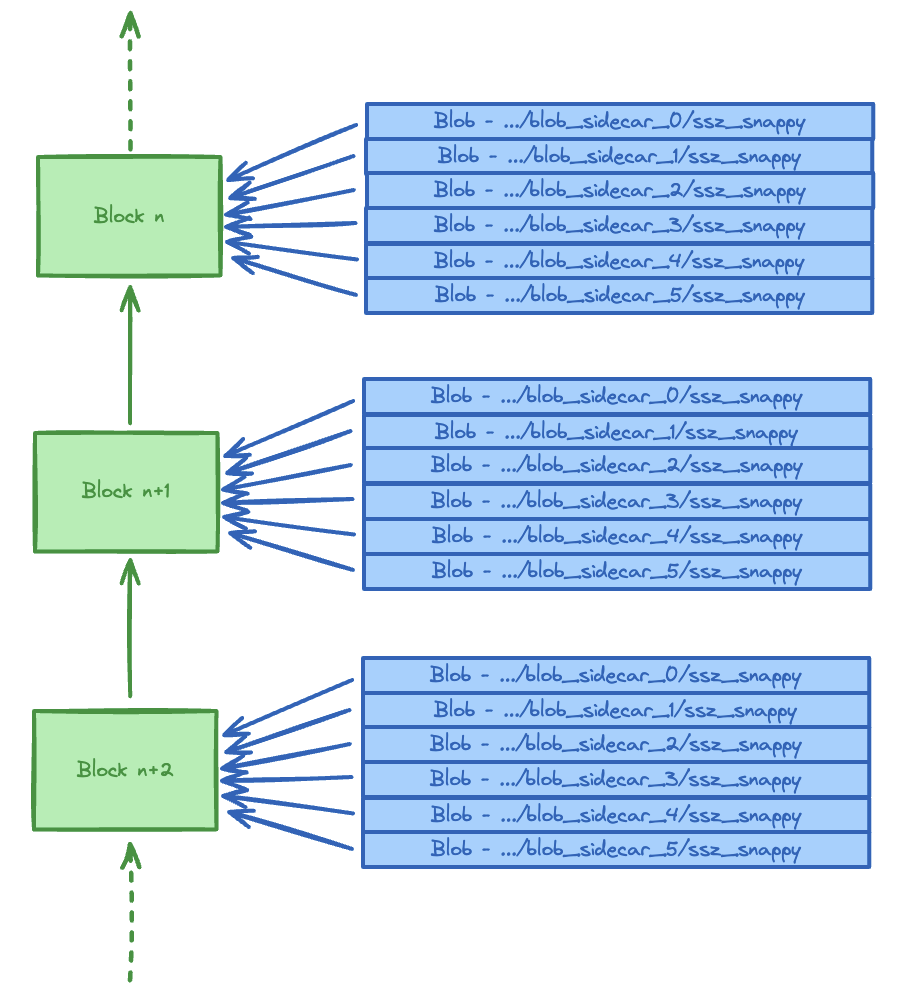
Proto Danksharding 的缺点是所需的带宽和存储会随着每个区块的 blobs 数量线性扩展。
如何将 blobs 提交到区块?
每个 blob 都包含一个 KZG commitment (KZG 承诺)和一个 KZG proof (KZG 证明)。
Holesky 区块上的示例:
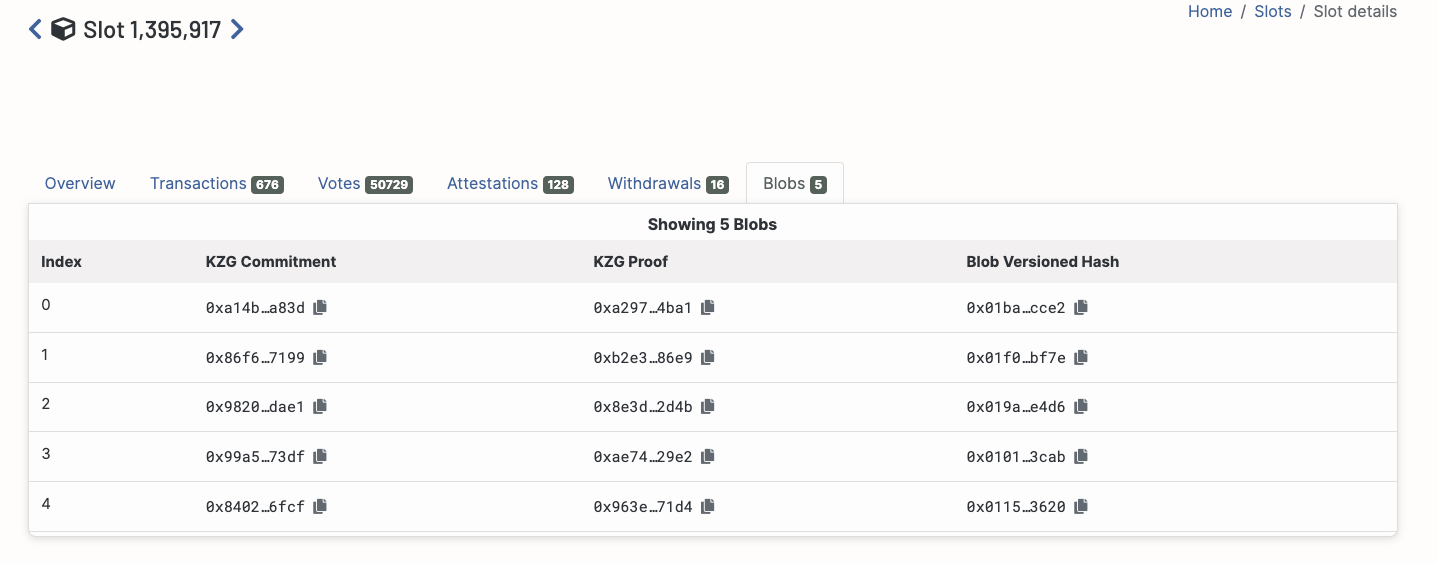
与这些 blobs 对应的区块包括一个 data.message.body.blob_kzg_commitments 列表。
使用 http://<url-of-a-beacon-node>/eth/v2/beacon/blocks/1395917 的示例:
...
"blob_kzg_commitments": [\
"0xa14bdaf61b3e064d51e6dbfc3b6e09524df3b287305fa53b8b294208a2c43bcd55703e7227fdb9dc576e93fb0a95a83d",\
"0x86f6e5cc74d57519130f5904865d51fd0bf04b5c349aeea9bf6e40c39fbf907f3b6ccc1e4c020504cb013e1dc25e7199",\
"0x98200ae7d82cd9c547a9c730b013031b8b5a9b4985c4ec3e7f85387756298cbeeba7afec04f4b930b11f411505cddae1",\
"0x99a52d01d4932224fad07ac59cb1835a22b9277b7ce4cebc9239ece7998b5787e9a460de97ee8a86992bb724d84273df",\
"0x840287537b781520f595ab6bf743c0619c822b69cb179828e8ceebd9f4662d416b3bba65557e3c3c973916a86db76fcf"\
]
...
有人可能想知道为什么将 blob 链接到信标块需要 KZG 承诺和 KZG 证明装置。在 EIP-4844 - Proto Danksharding 的上下文中,它们不是严格要求的。通过使用 blob 的哈希代替 blob_kzg_commitments 将信标块链接到 blobs 也可以完成相同的任务。但是,当实现真正的分片时(这将在本书后面讨论),KZG 承诺和 KZG 证明的全部潜力将得以实现。
如何存储 blobs?
在 Prysm 中,blobs 直接存储在使用模式 blobs/<blockRoot>/<blobIndex>.ssz 的文件系统中。
例子:
blobs
├── 0x00022463ed9299403b70d78cd0ab5049fc03eefdd0bf87108ee387587eadd06b
│ ├── 0.ssz
│ ├── 1.ssz
│ ├── 2.ssz
│ ├── 3.ssz
│ ├── 4.ssz
│ └── 5.ssz
├── 0x00026f77d57e29089085edf99bc79a37f67cdb844f01aa5f85435e77de3c5d2b
│ └── 0.ssz
├── 0x0002fd2893c692ac508b502ba31fbfe351738280af8e92acc397e456af888c7a
│ └── 0.ssz
├── 0x0003be159d8a3d04ccbc288dfb19b39eba35dfb9eba1788a966cd90d23426c21
│ ├── 0.ssz
│ ├── 1.ssz
│ ├── 2.ssz
│ ├── 3.ssz
│ ├── 4.ssz
│ └── 5.ssz
├── 0x0004d2a59f6ae7996a87a5b6e928b2fad0b864171dcf3bf609f74b8584f44722
│ ├── 0.ssz
│ ├── 1.ssz
│ └── 2.ssz
├── 0x000537721bdc9fb0de40e0f14220155eb9cb94dd46e9b73f0a0e6fd852fa5539
│ ├── 0.ssz
│ ├── 1.ssz
│ ├── 2.ssz
│ ├── 3.ssz
│ ├── 4.ssz
│ └── 5.ssz
...
Blobs 如何影响分叉选择规则?
on_block 函数修改如下:
def on_block(store: Store, signed_block: SignedBeaconBlock) -> None:
"""
Run ``on_block`` upon receiving a new block.
# 接收到新区块时运行 ``on_block``。
"""
...
# [New in Deneb:EIP4844]
# Check if blob data is available
# 如果blob数据可用
# If not, this block MAY be queued and subsequently considered when blob data becomes available
# 如果不可用,这个区块可能会被排队,当blob数据可用时会被考虑
# *Note*: Extraneous or invalid Blobs (in addition to the expected/referenced valid blobs)
# *注意*:额外的或无效的 Blobs(除了预期的/引用的有效blobs之外)
# received on the p2p network MUST NOT invalidate a block that is otherwise valid and available
# 在 p2p 网络上接收到的 MUST NOT 使其他有效和可用的区块失效
assert is_data_available(hash_tree_root(block), block.body.blob_kzg_commitments)
...
is_data_available 函数在此处描述:here。
在声明一个区块有效之前,节点必须:
- 获取所有相关的 blobs(以及相关的证明)。
- 验证证明是否正确。
当前方法的问题是什么?
目标值 vs. 最大值
之前,我们提到一个区块最多可以包含 6 个 blobs。实际上,发布一个 blob 会产生特定的成本,该成本由 blob 费用决定。
区块 n+1 的 blob 费用是根据区块 n 中包含的 blobs 数量计算的。
定义了两个参数:目标计数和最大 blob 计数。目前,目标计数设置为 3,最大 blob 计数设置为 6。
- 如果区块
n包含的 blobs 数量等于目标计数,则区块n+1的 blob 费用将与区块n的 blob 费用相同。 - 如果区块
n包含的 blobs 数量多于目标计数,则区块n+1的 blob 费用将是区块n的 blob 费用乘以一个大于1的值。区块n中的 blob 计数越高,乘数值就越高。如果 blob 计数始终超过目标值,这将导致 blob 费用呈指数增长。 - 如果区块
n包含的 blobs 数量少于目标计数,则区块n+1的 blob 费用将是区块n的 blob 费用乘以一个小于1的正值。区块n中的 blob 计数越低,乘数值就越低。如果 blob 计数始终低于目标值,这将导致 blob 费用呈指数下降。
以下是 2024 年 11 月 11 日至 2024 年 11 月 18 日的 blob 费用(以 Gwei 为单位)的示例:
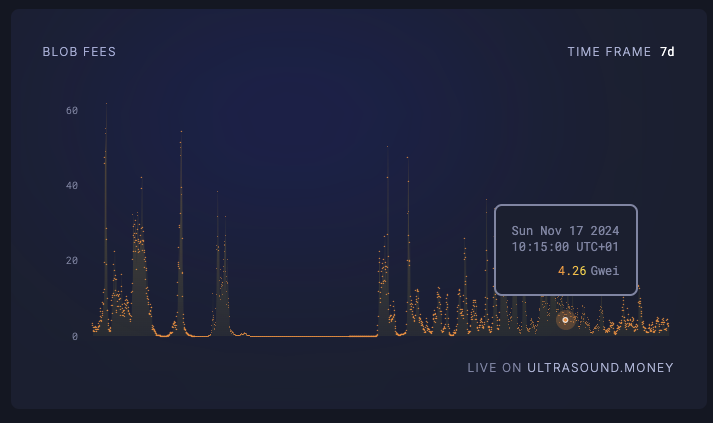
来源: ultrasound.money
blob 费用不时飙升,表明 blob 计数超过了目标值。这反映了对 blobs 的需求(主要来自Layer2)超过了可用供应,从而导致费用飙升。
此外,自 2024 年 11 月以来,平均 blob 计数一直与目标 blob 计数相符。这表明 blobs 目前正在满负荷使用。
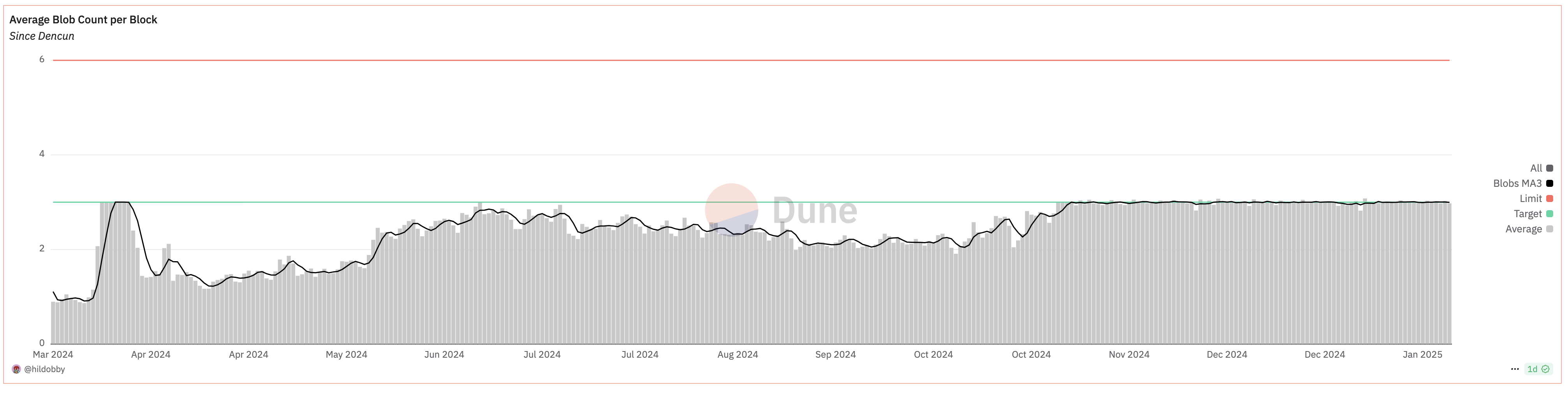
来源: Dune
我们旨在解决的问题是如何增加 blob 计数,从而为Layer2提供更多空间。
增加目标值和/或最大 blob 计数。
解决此问题的一个简单方法是增加目标值和/或最大 blob 计数。
但是,这样做可能会惩罚一些带宽有限的单机权益质押者。假设所有节点必须在插槽的最多 4 秒内收到区块和 blobs,则 6 个 blobs 将需要平均 192 kB/sec 的带宽。
将最大 blob 计数乘以 5(将其增加到 30 个 blobs)将导致平均带宽要求为 960 kB/sec,这对于某些互联网带宽有限的单机权益质押者来说太高了(尤其是对于上传),可能会破坏网络去中心化。
引入分片。
为了解决这个问题,我们引入了分片和数据可用性抽样 (DAS) 的概念,这使得增加目标和最大 blob 计数成为可能。
- 原文链接: hackmd.io/@manunalepa/B1...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





