共享 Blob 压缩
- SpireLabs
- 发布于 2024-12-25 22:22
- 阅读 2022
本文介绍了appchain采用blob聚合和压缩的优势,包括更频繁地提交交易、更有效地使用blob空间、以及无需担心L1区块blob槽不足的问题。文章还探讨了定义DA层、压缩方案等参数的规范,并提出了一个blob聚合器架构的示例,以及共享blob压缩和聚合的细节。
介绍
随着 appchain 采用率的增长,越来越多的链需要选择将其 blob 与来自其他 appchain 的 blob 进行聚合和压缩。聚合具有以下优点:
-
appchain 可以更频繁地将其交易提交到其选择的 DA 层。他们不再需要等待有足够的交易数据来填充一个 blob 才能提交,或者支付提交未完全填充 blob 的成本。
-
appchain 可以更有效地使用 blobspace,特别是交易量较低的链。
-
appchain 不再需要担心 L1 区块耗尽可用 blob 插槽的情况,因为它们的 blob 将与其他 appchain 的 blob 聚合。
除了聚合 blob 之外,这将允许 appchain 指定其他参数,例如它们支持哪些 DA 层,它们使用哪些数据压缩方案,它们以哪个 L1 区块为目标,以及它们如何选择更新其状态。在这篇文章中,我们探讨了规范可能是什么样子的一些可能性。
实现
我们不打算将其作为所有 appchain 必须使用的单一实现。目标是创建一个中立的规范,以实现对共享 blob 压缩和聚合的通用访问。由于 Spire 大力支持 appchain 的增长,我们可能会为在 Spire 上运行的 appchain 提供此规范的实现。
功能声明
希望选择此设计的 Appchain 可以通过 json 定义它们支持的 DA 层、压缩方案和其他字段的列表。此格式非常灵活,json 可以根据需要转换为二进制或 uri 表示形式。
例如:
{
"chain_id": "123",
"capabilities": {
"da_layers": [\
"beacon", "altda1", "altda2"\
],
"compression_schemes": [\
"gzip"\
],
"shared_state": false, // 指示 appchain 是否将运行自己的节点和推导管道。
"uniform_blob": false, // 指示 appchain 是否希望位于其自己的 blob 或共享 blob 中
"target_block": 1234567, // appchain 的 blob 数据必须发布的 L1 插槽。 这可能需要在其他地方指定
"tip": 5 gwei // appchain 在高聚合请求时优先包含其 blob 的一种方式。
}
}
位置说明符
待定。 这是检索 blob 数据单元所需的信息。 字段可能包括:
-
目标 DA
-
压缩方案
-
数据长度
-
数据偏移量
-
chain_id/命名空间
Blob 布局
聚合 blob 的布局可以是命名空间默克尔树 (NMT),叶子节点是各个blob数据的块,以及作为命名空间的 rollup 标识符。 NMT 提供了一些保证,即 blob 的内容不会被伪造。
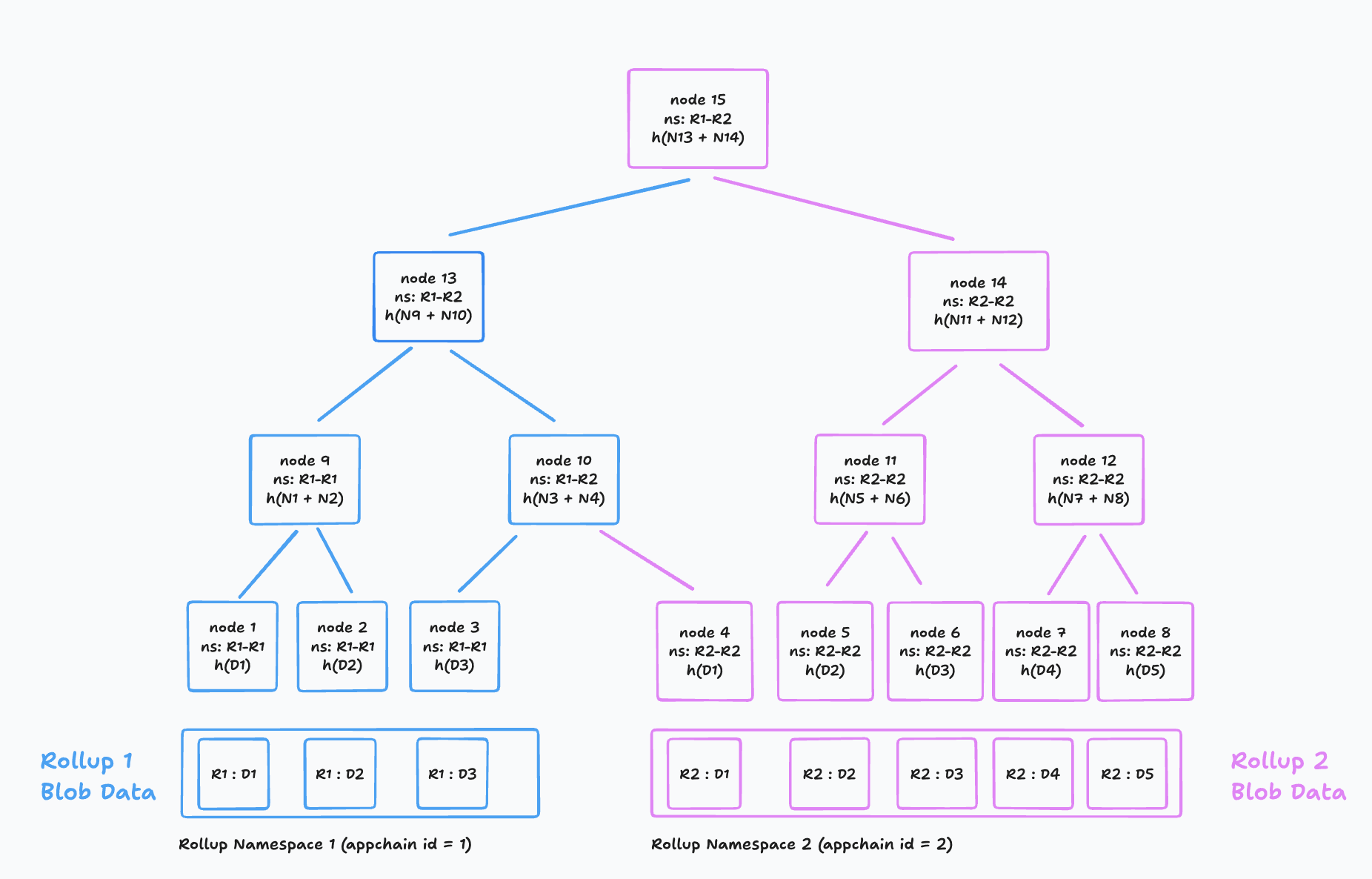
另一种方法可以使用带有长度和偏移量的平面结构。
Blob 聚合器架构示例
作为背景,以下是 blob 目前如何在 Optimism 等 rollup 中工作的一个简要概述。
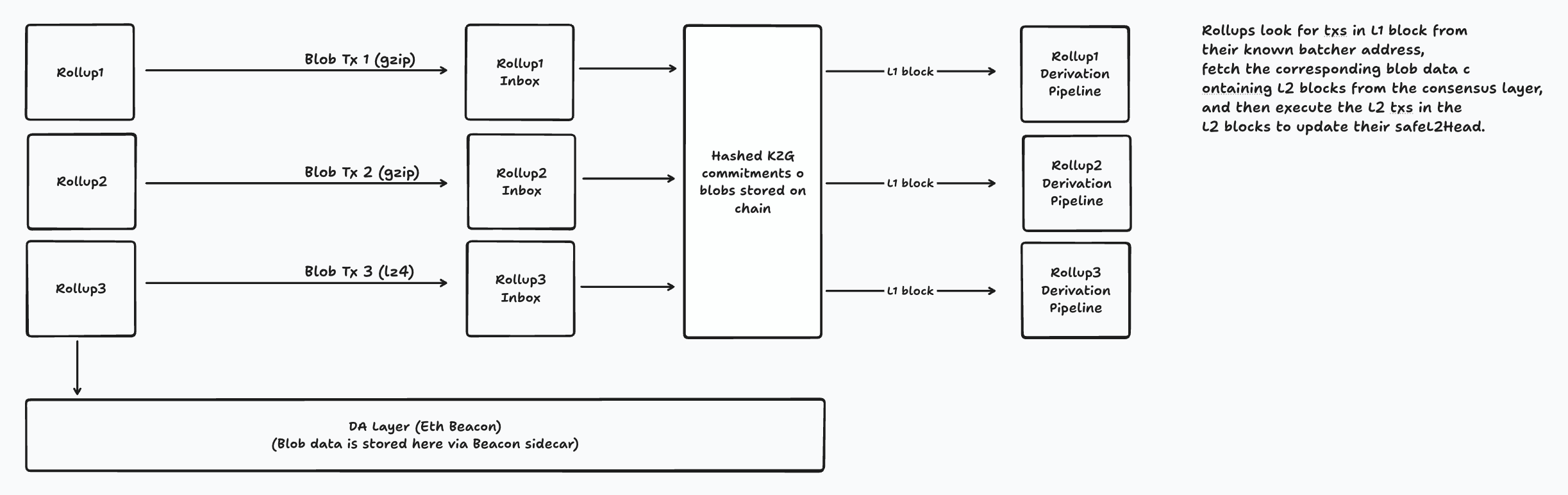
Blob 通过 L1 beacon 客户端的 GetBlobSidecars 方法,在每个 rollup 的推导步骤中从共识层获取。
接下来是一个假设的设计,说明 appchain/rollup 如何选择使用 blob 聚合器服务。 在最初通过发送上述 JSON 数据向服务注册并收到 rollup id 之后,blob 数据可以发送到聚合器:
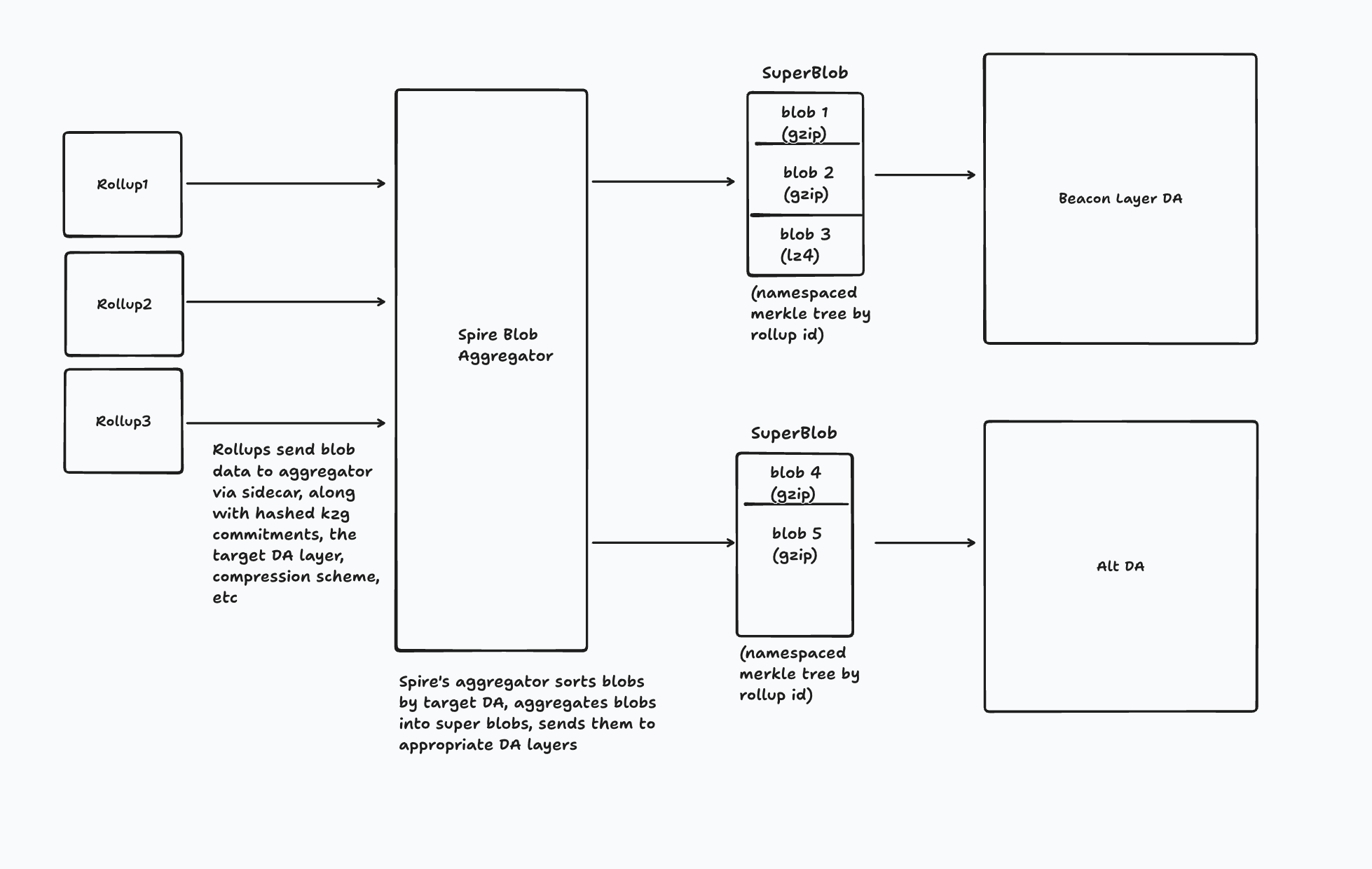
在此设计中,rollup 将:
-
将其 blob 数据连同每个 blob 的承诺、其 rollup/chain-id、支持的压缩方案、目标 DA 层、目标 L1 区块以及可能的一些其他字段发送到链下聚合器服务。
-
然后,聚合器服务将按大小、目标 DA、压缩方案等对传入的 blob 进行排序。实现细节可能会有所不同。
-
聚合器服务将针对同一 DA 的blob连接成一个“超级blob”,并生成和存储一个 NMT,以便 rollup 可以通过其 rollup-id 快速识别超级 blob 中的 blob。
-
超级 blob 通过 sidecar 发送到各自的 DA 层。 针对 Blob 聚合器的收件箱合约的 L1 交易(带有对超级 blob 的承诺)将发送到 L1。 请注意,如果 rollup 指定了目标 L1 区块,则聚合器可能需要在此时获得某种预确认。
-
Rollup 更新其状态(例如,推导管道等),以识别来自聚合器服务地址的批量交易或证明。 与 rollup 相关的 Blob 数据是从超级 blob 中获取的,可以由 rollup 本身获取,也可以使用聚合器服务提供的某个端点获取
-
Rollup 负责提供一种机制来确认检索到的 blob 与它们最初发送的 blob 相匹配。 例如,提供一个可以通过公钥验证的 blob 承诺。 可能需要额外的确认。 例如,Based Rollup 可能需要确认 blob 中原始 L2 数据是由 L1 区块的正确选举获胜者排序的,等等。
-
然后,Rollup 使用解压缩的数据来更新其状态并推进规范推导。
共享 Blob 压缩和聚合详细信息
支持的压缩算法
此规范对支持的压缩类型没有任何限制。 Appchain 可以自由选择文件和流压缩方案。
我们假设每个根 DA 规范地址使用一个压缩方案。
Blob 串联
待定。 一种方法可能是简单地始终选择适合当前 blob 剩余空间的最大 blob。
高效的 Blob 检索
给定一个聚合 blob,appchain 能够使用命名空间默克尔树有效地验证和检索与它们相关的聚合 blob 部分。 Espresso 使用类似的方法,允许各个 rollup 轻松地从共享的 HotShot 区块流中推导出它们的区块 [ ref]。 每个 appchain 都有一个唯一的 appchain-id,用作命名空间标识符。
DA 的选择
此规范默认使用以太坊的信标层进行 blob DA。 但是,如果 rollup 需要支持更快、更便宜的 DA,而不受 L1 固定区块时间的约束,则可以自由选择替代 DA 层。
费用分配
待定。 费用可以根据 rollup 使用给定 blob 的百分比按比例分配给 rollup。
扩展
此规范旨在可扩展。 未来的扩展可能涉及发送加密 blob,以帮助解决预确认者的公平交换问题。
参考
-
来自 EthGlobal Istanbull 的 blob 聚合的示例实现 [ ref]
-
关于 blob 共享的 HackMD 论文 [ ref]
-
Dankrad 关于分片 blob 标头格式的论文 [ ref]
关注我们! 🗼
从 Spire 获取最新信息:
-
X(Twitter): https://x.com/Spire_Labs
-
Website: https://www.spire.dev/
-
Docs: https://docs.spire.dev/
- 原文链接: paragraph.com/@spire/sha...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~
- 翻译
- 学分: 0
- 分类: 以太坊
- 标签: Appchain Blob聚合 数据可用性 (DA) 压缩 命名空间默克尔树(NMT) Rollup





