Ethrex 一周年纪念
- lambdaclass
- 发布于 2025-05-17 17:18
- 阅读 448
Ethrex 是一个由 LambdaClass 开发的以太坊 L1 执行客户端和 L2 客户端,从一开始就原生支持Based Rollup。Ethrex 注重简单性和最小化,致力于提供更易于维护和调试的代码库,并计划在 Devconnect 上展示其用例,目标是推进以太坊的发展。
自 2024 年 6 月以来,我们一直在 LambdaClass 从事一个名为 ethrex 的以太坊 L1 执行和 L2 客户端的开发工作。既然它已经成熟,并且最近被添加到 Hive 中,我们认为现在是时候谈谈它,并强调它与其他客户端的不同之处。
Ethrex 最初只是一个由三名团队成员组成的探索性项目,现已发展成为一个 40 人的项目——现在是 LambdaClass 的首要任务之一。它是第一个从一开始就原生集成 基于 rollups 的堆栈。我们正准备进入安全审计阶段,并将直接与 Rogue 一起投入生产,同时还有几家渴望部署自己的 L2 堆栈的机构和客户。
大多数驱动 ethrex 的想法都有一个核心原则:简单性。我们建议阅读 Vitalik 最近关于简化 L1 的文章;它分享了我们将在本文中讨论的许多相同想法,并且作为指导原则与我们产生了极大的共鸣。
为什么要构建另一个以太坊执行客户端?
目前,以太坊生态系统具有良好的客户端多样性:Geth、Besu、Erigon、Nethermind 和 Reth 都是生产级别的选择,尽管受欢迎程度各不相同。那么,为什么要编写一个新的客户端,并且在 Reth 存在的情况下,为什么要用 Rust 编写它呢?
我们越深入地参与到加密领域,并使用它的工具和代码库,我们就越意识到它们中的大多数都比我们愿意接受的更复杂;有时甚至积极地将其作为其开发过程的一部分来追求。拥有数十个模块的库,即使是最轻微的事情也要模块化,具有大量 traits 和 generics 的 APIs,旨在抽象每一个意外情况,用于(有争议地)节省代码行的宏,以牺牲可读性为代价,这些都是我们在与加密存储库集成时,我们和其他人必须不断处理的不便之处。
Ethrex 是我们解决这个问题的尝试。它的目标是成为我们希望在开始时拥有的基础设施、库和工具。与 LambdaClass 的工作理念 一致,我们的目标是始终保持简单和最小化。这体现在几个不同的方面。
我们跟踪项目的代码行数,确保我们永远不会超过限制。整个 repo 目前有 62k 行代码。这包括我们的 EVM 实现、我们的 L2 堆栈(以及 ZK prover 和 TEE 代码)和我们的 ethereum sdk 的代码。大多数其他客户端在其主 repos 上的平均值约为 200k,甚至不包括它们的依赖项,这些依赖项通常被拆分为其他 repos(EVM、sdk、provers)。包括这些可以很容易地超过 300k 甚至更多。我们的方法严重倾向于垂直集成和极简主义,确保我们控制整个堆栈,同时使其尽可能简单。
我们每天都会收到自动化的 slack 消息,以警惕我们项目中的代码行数,并定期寻找无用或不必要的代码以及重构机会以减少它们。
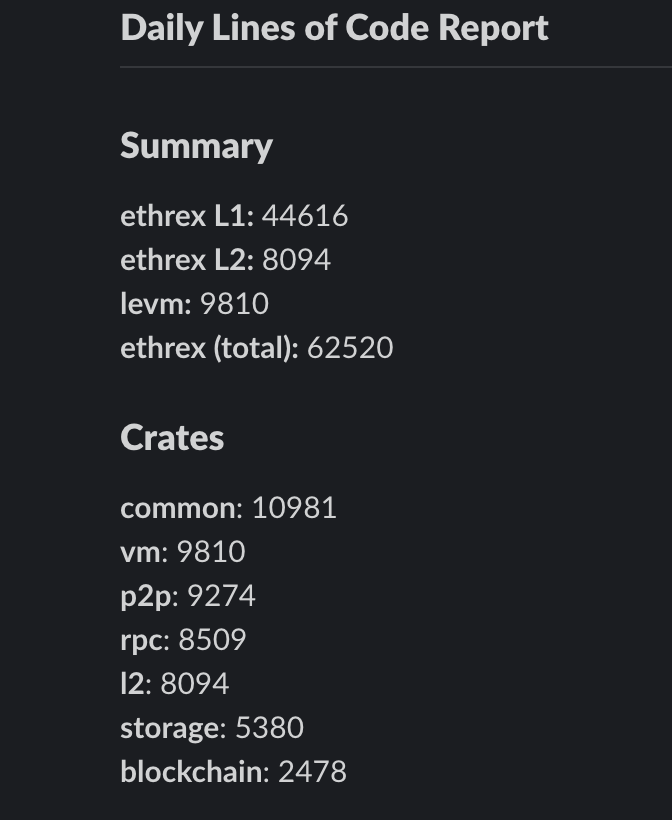 代码行数报告
代码行数报告
如上图所示,ethrex repo 仅由六个不言自明的主 crate 组成:
- blockchain
- common
- l2
- networking(分为 p2p 和 rpc)
- storage
- vm
这很有目的性;其他客户端倾向于将代码过度模块化为不同的包,从而损害了可读性和简单性。
traits 的使用保持在最低限度,只有在绝对有必要引入它们时才使用。我们的代码库仅包含 12 个 traits,我们已经认为太多了,并且正在积极寻找减少它们的方法。它们用于以下目的:
- RLP 编码和解码。
- 数据签名。
- Trie 存储、常规存储和 L2 存储。
- RLPx 编码和 RPC 处理程序。
- EVM hooks。
在整个代码库中,不赞成使用宏。在 ethrex 中只有四个,其中三个仅用于测试,一个用于 Prometheus 指标收集。
依赖项也尽可能地保持在受控状态。Rust 代码库以堆积 crates 而闻名,虽然我们仍然认为我们依赖于太多的 crates,但我们会定期努力减少它们。
极简主义也体现在我们不实现历史功能的决定中;ethrex 仅支持合并后的 forks。我们认为以太坊应该具有前瞻性的加速主义态度,以赢得其在区块链领域的竞争对手,这意味着快速行动,拥抱变革,并通过不害怕快速放弃对旧功能的支持来保持精简。这也提高了项目的 ROI,因为它允许我们用一个较小的团队来开发和维护它。
我们对如何编写 Rust 代码有非常明确的看法。虽然我们喜欢这种语言,因为它融合了高性能、内存安全保证和高级语言结构,但我们认为很容易被它的特性冲昏头脑,并过度复杂化代码库;拥有丰富而富有表现力的类型系统并不意味着应该抓住每一个机会,通过 trait 将每一个问题具体化。这会使新手的代码变得晦涩难懂,并且会以很小的收益使其变得更加复杂。
对于开发人员来说,所有这些不仅对可读性和易用性产生影响,而且对编译时间也有影响。具有许多 traits 和宏的复杂代码架构会增加编译时间,从而损害开发人员的体验。在现代机器上,Rust 项目需要几分钟才能编译完成的情况并不少见,而代码复杂性在其中起着重要作用。
然而,简单性和极简主义不仅仅是为了让开发人员的体验更轻松。代码行数越少,维护代码、查找错误或漏洞以及发现可能的性能瓶颈和改进就越容易。它还减少了安全漏洞存在的攻击面。
Ethrex L2
从一开始,ethrex 的设想不仅仅是一个以太坊 L1 客户端,还是一个 L2(ZK Rollup)客户端。这意味着任何人都可以使用 ethrex 部署一个 EVM 等效的、多 prover(支持 SP1、RISC Zero 和 TEE)基于 rollup,只需一个命令。金融机构也可以使用它来部署自己的 L2,可以选择将其部署为 Validium、基于 Rollup 或常规 ZK Rollup。事实上,我们即将推出的无需许可的基于 L2 Rogue 使用 ethrex,任何人都可以通过克隆 repo 并运行一条命令来加入它。
ethrex L2 开发的关键是通用 ZK 虚拟机的可用性,该虚拟机使用 基于 哈希的证明系统,例如 SP1 和 RISC Zero,允许证明用 Rust 编写的任意代码。
在加密货币领域已经有几年了,我们亲身经历了使用 Circom、Bellman、Arkworks 或 Gnark 等库编写算术电路的痛苦。这样做需要深入了解 zk-SNARKs 的内部结构,而大多数工程师并不关心也不应该关心。此外,需要不同的 API 或 DSL 来编写电路意味着你最终会得到相同事物的两个实现:一个在电路外,一个在电路内。这是一个巨大的问题来源,因为每次代码更改都可能导致正在执行的代码和正在证明的代码之间存在差异,而解决这些类型的错误可能具有挑战性且耗时。
使用 RISC-V zkVM,这些问题就会消失;工程师可以轻松地编写要证明的代码,而无需了解任何内部结构,并且出现差异的可能性很小,因为几乎所有代码都可以在“电路外”和“电路内”版本之间共享。
Scroll 和 ZKsync 等 ZK-rollup 将其证明系统与其 VM 紧密结合。虽然这可行,但这意味着拥有一个非 EVM 架构,并且需要经过很多环节才能支持 EVM 等效性。这也意味着拥有一个由专家密码学家组成的内部团队来设计和开发证明其执行所需的所有复杂电路。在 LambdaClass,我们认为底层密码学应该留给像 Starkware 的 Stwo、Lita 的 Valida、Polygon 的 PetraVM、Succinct 的 SP1 或 a16z 的 Jolt 等项目。我们的工作是将他们的工作插入到我们的工作中,将密码学与代码库的其余部分分离,从而大大简化了开发。这就是使我们成为从一开始就被设计成 L1、L2 和 基于 rollup 的唯一客户端的原因。
所有这些好处都可以非常清楚地看到:所有相关代码所在的整个 l2/prover 目录只有 1.3k 行代码,即使这也可以进一步减少,因为我们还没有将某些行为移动到通用函数中。在我们使用和合作过的其他项目中,ZK 相关代码非常庞大,有时甚至与常规的非 ZK 代码相匹配或超过。
还剩下什么
在过去的一年里,我们取得了很大的进展,从一个空存储库到一个成熟的 L1 和 L2 客户端,但要使 ethrex 达到生产就绪状态,还有很多工作要做。目前的主要重点是性能。我们目前的速率约为 0.3 gigagas/s,我们的目标是在未来几周内达到至少 1 gigagas/s,其中大部分来自对 trie/数据库访问的改进。之后是安全审计和 基于 rollup 支持。我们还计划在此基础上添加额外的功能,包括对 validiums 的替代 DA 支持以及自定义本机Token模式,这两者都适用于 ethrex L2。
今年的 Devconnect 将在我们的家乡布宜诺斯艾利斯举行。届时,我们的目标是拥有一个功能完整的 ethrex 版本在生产中运行,准备展示其最令人兴奋的一些用例。正如提到的,越来越多的公司和机构表示对 ethrex 及其潜力感兴趣。我们的使命是通过构建解决现实世界挑战的基础设施和应用程序来帮助推进以太坊的发展。
我们邀请你跟随我们一起进步,因为我们在公开场合进行构建并亲自尝试:
Telegram: https://t.me/ethrex_client
Github: https://github.com/lambdaclass/ethrex
- 原文链接: blog.lambdaclass.com/cel...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





