Constantine 性能表现
- mratsim
- 发布于 2024-08-01 10:28
- 阅读 1518
本文主要介绍了Constantine在区块链和零知识证明等领域的性能优势,以及如何通过基准测试来衡量其性能。文章详细对比了不同编译器(如GCC和Clang)在优化大整数和密码学代码方面的差异,并强调了使用内联汇编以确保性能和避免分支的重要性,Constantine通过优化代码大小和栈使用量,以及避免堆分配,适用于资源受限的设备。
性能
高性能是一种备受追捧的特性。 请注意,安全性和侧信道抵抗优先于性能。
椭圆曲线密码学的新应用,如零知识证明或基于权益证明的区块链协议,都受到密码学的限制。
在区块链中
以太坊 2 客户端花费或者曾经花费其 30% 到 99% 的处理时间来验证研发测试网络上区块验证者的签名。 假设我们希望节点处理一千个对等节点,如果一个密码学配对需要 1 毫秒,那么每个区块的密码学计算需要 1 秒,而目标区块频率为每 6 秒一个。
在零知识证明中
根据 https://medium.com/loopring-protocol/zksnark-prover-optimizations-3e9a3e5578c0 一个 16 核 CPU 可以证明 20 个传输/秒 或 10 个交易/秒。 之前的实现速度慢 15 倍,其中一个关键的优化是 改变了椭圆曲线密码学后端。 这对硬件成本和/或所需的云计算资源有直接的影响。
测量性能
要测量 Constantine 的性能
git clone https://github.com/mratsim/constantine
## 默认编译器。我们建议强制使用 CC=clang 以获得最佳性能。
nimble bench_fp
## 算术
CC=clang nimble bench_fp # 使用 Clang + 汇编 (推荐)
CC=clang nimble bench_fp2
CC=clang nimble bench_fp12
## 标量乘法和配对
CC=clang nimble bench_ec_g1_scalar_mul
CC=clang nimble bench_ec_g2_scalar_mul
CC=clang nimble bench_pairing_bls12_381
## 以及每个曲线的总结
CC=clang nimble bench_summary_bn254_nogami
CC=clang nimble bench_summary_bn254_snarks
CC=clang nimble bench_summary_bls12_377
CC=clang nimble bench_summary_bls12_381
## 以太坊 BLS 签名协议
CC=clang nimble bench_eth_bls_signatures
## 以太坊 KZG 承诺
CC=clang nimble bench_eth_eip4844_kzg
## Ethereum Virtual Machine (EVM) 预编译
CC=clang nimble bench_eth_evm_precompiles
## 多标量乘法
CC=clang nimble bench_ec_g1_msm_bls12_381
CC=clang nimble bench_ec_g1_msm_bn254_snarks完整的基准测试列表可以在 benchmarks 文件夹中找到。
确切的命令在 nimble tasks 中列出。
正如在 编译器注意事项 部分提到的,由于 GCC 对进位和寄存器使用的处理不当,GCC 比 Clang 慢 2 倍。
以太坊基准测试
Ethereum Virtual Machine (EVM) 预编译
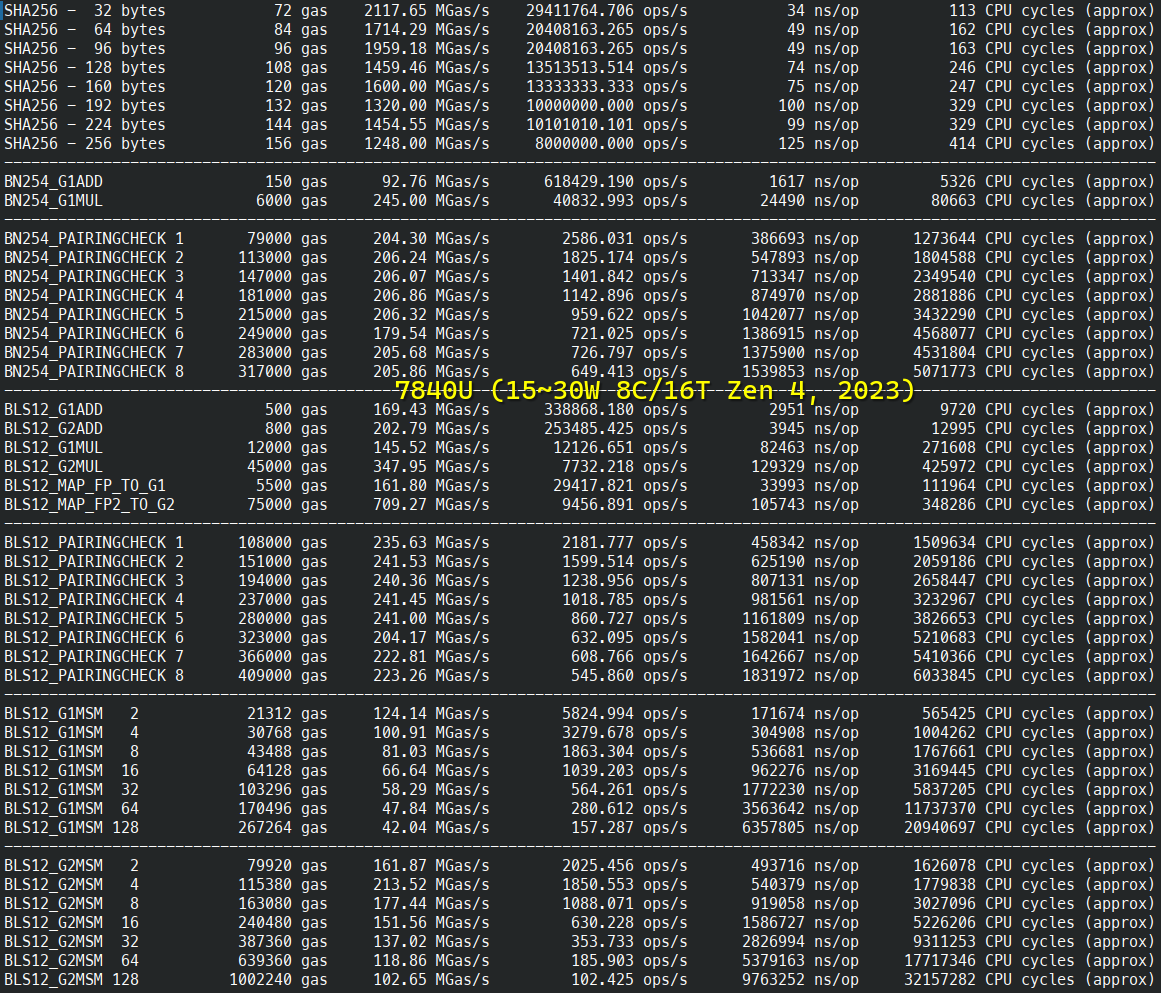
以太坊 KZG 承诺 (EIP-4844)
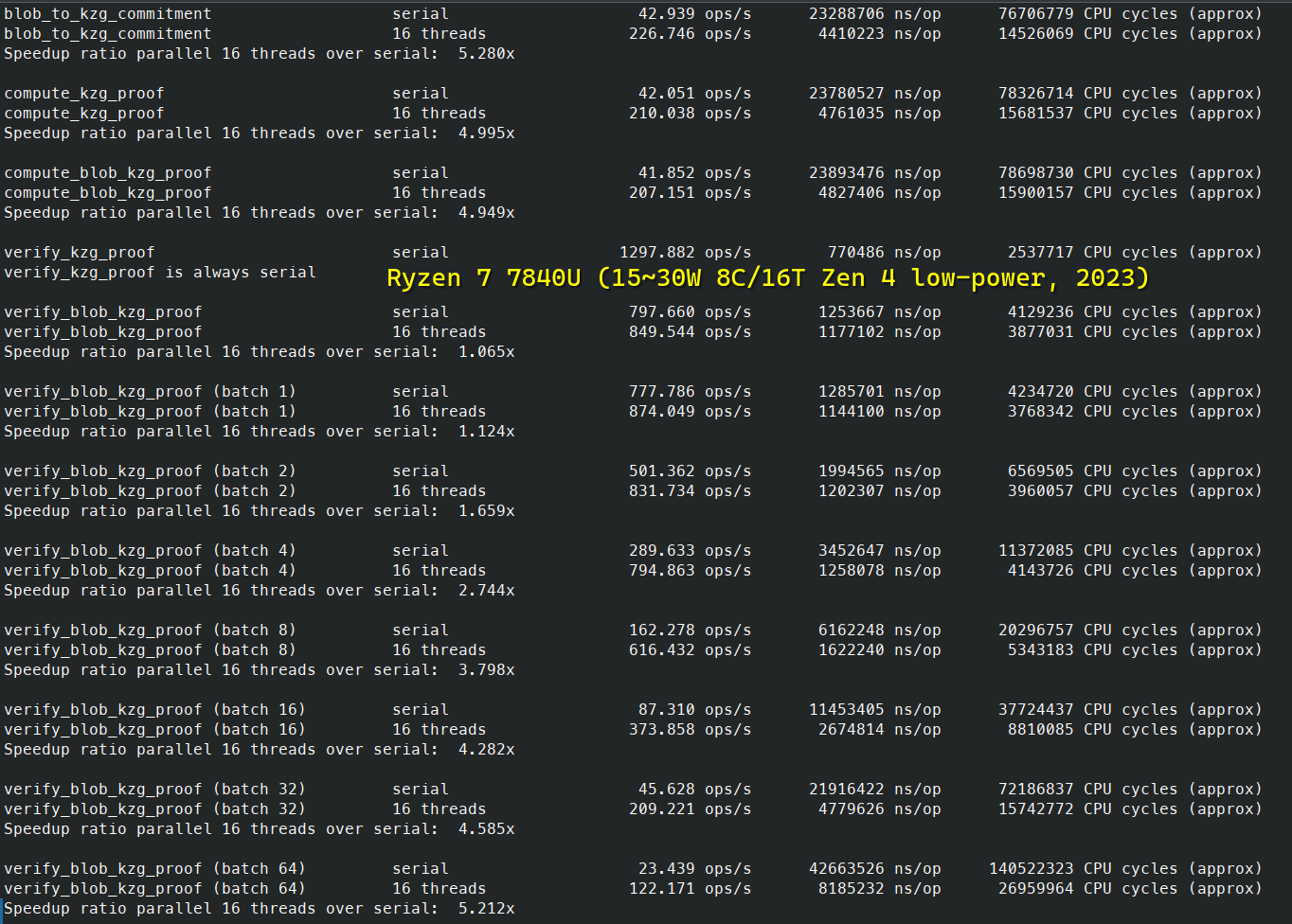
以太坊 BLS 签名 (基于 BLS12-381 𝔾₂)
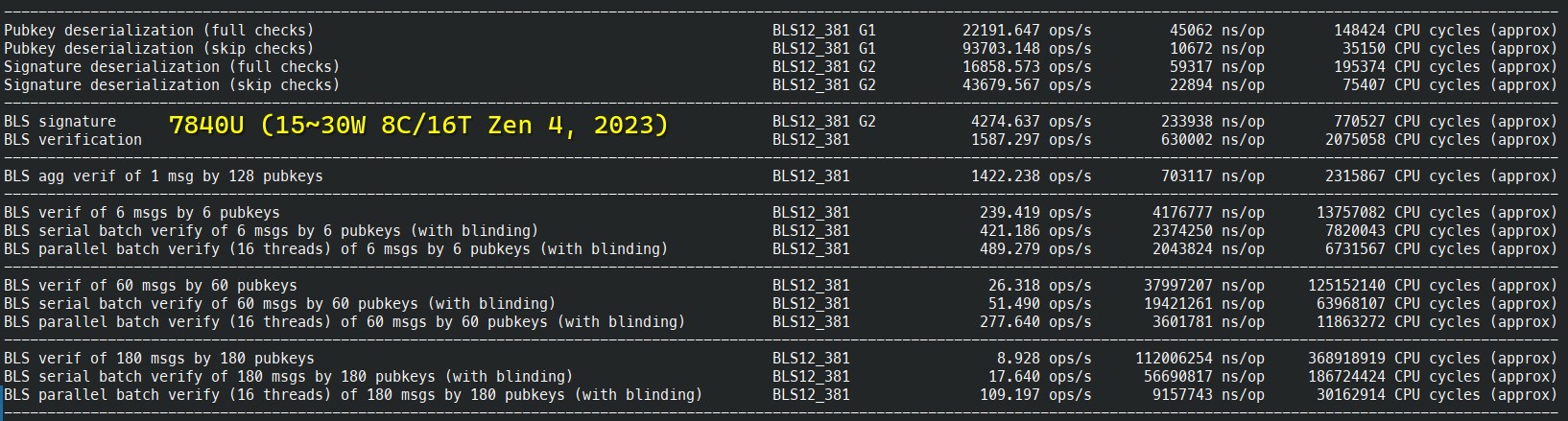
密码学原语基准测试
BLS12-381 详细基准测试
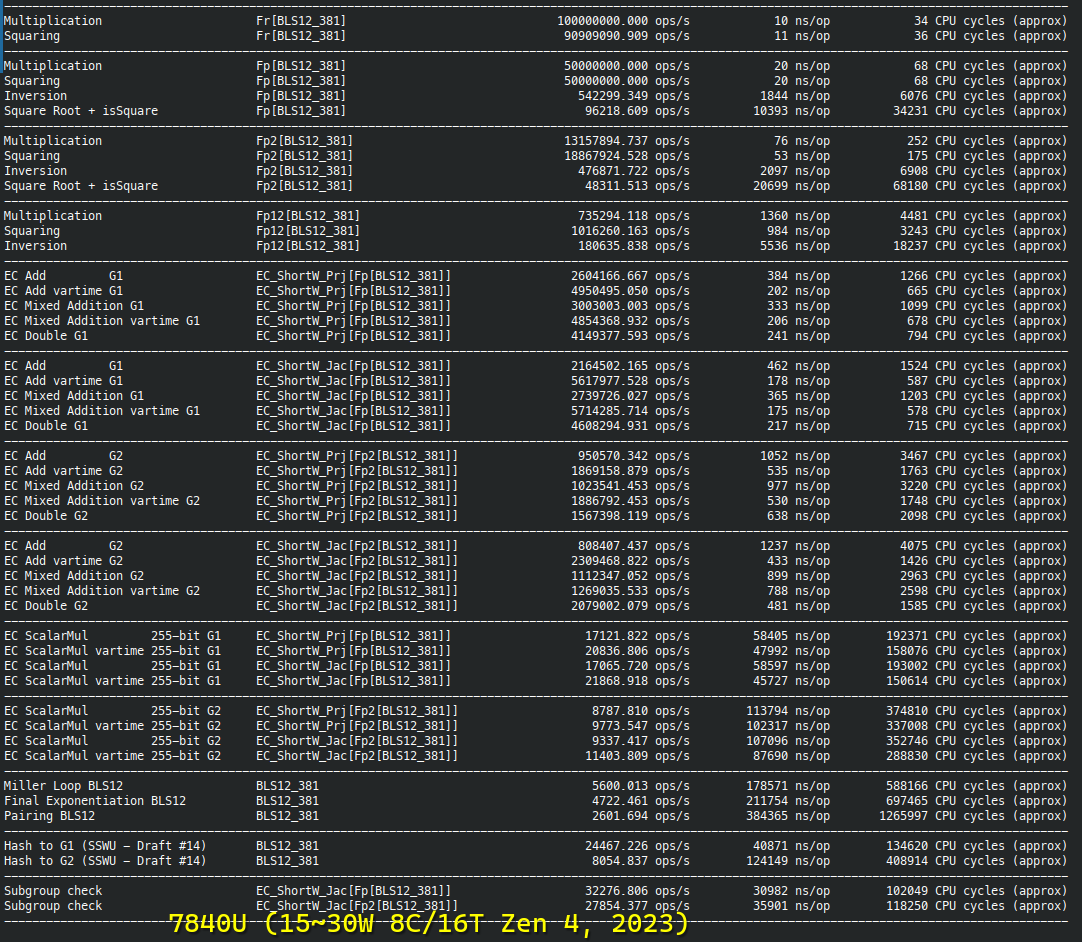
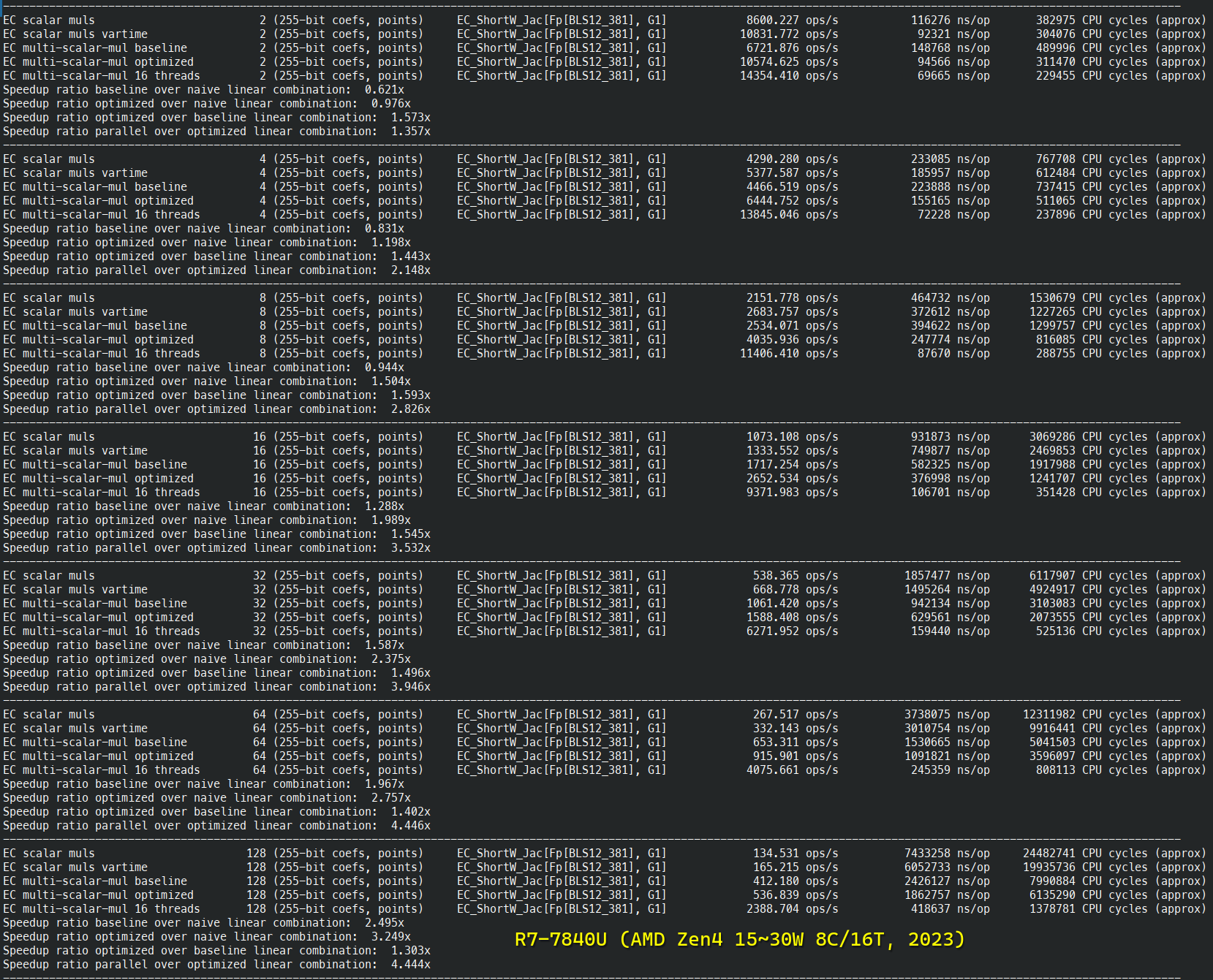
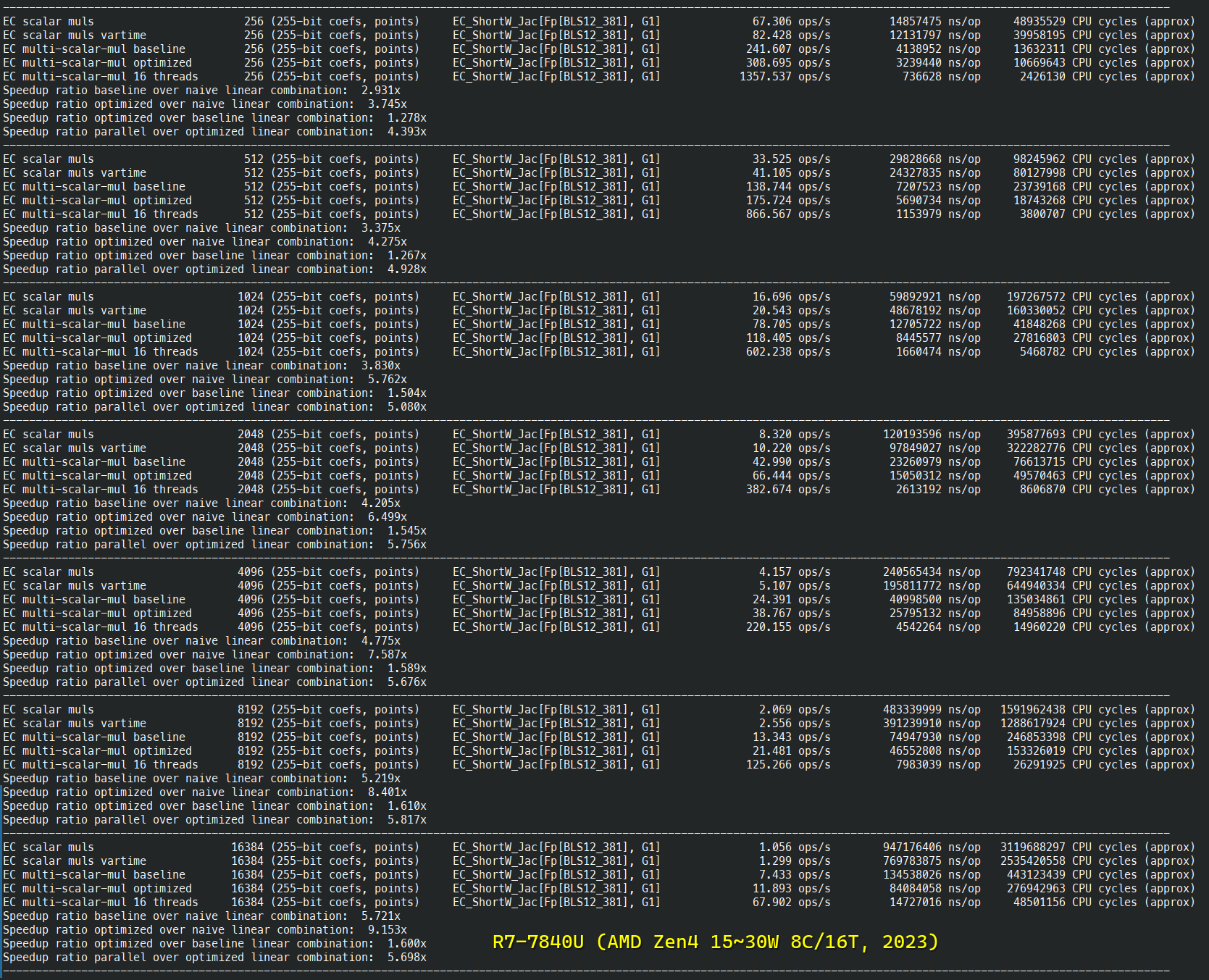
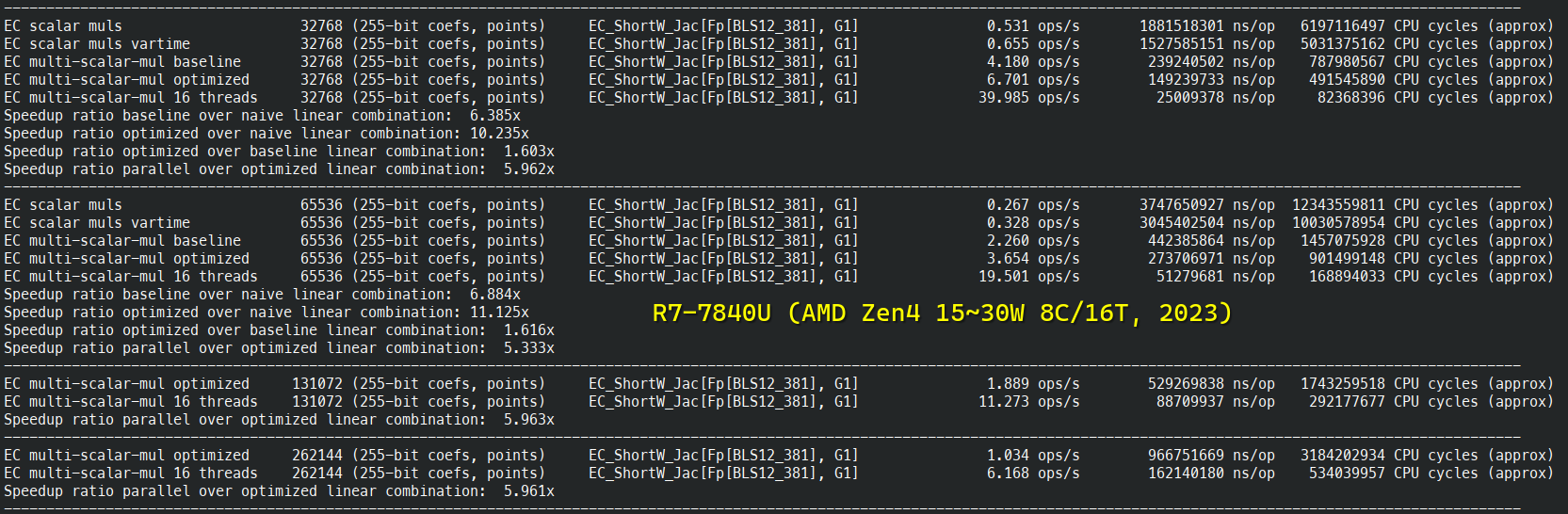
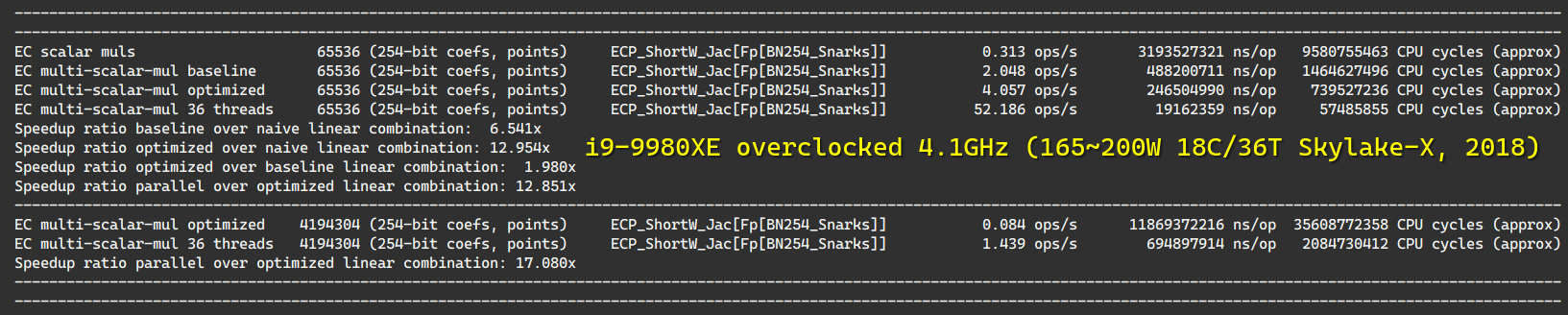
BN254-Snarks 多标量乘法基准测试
在 i9-9980XE 上 (18 核,水冷,超频,4.1GHz 全核睿频)
并行性
Constantine 的多线程原语由高度优化的线程池提供支持,并经过以下方面的压力测试:
- 调度器开销
- 具有极端不平衡的负载平衡
- 嵌套数据并行
- 争用
- 推测性/条件并行
并提供以下范例:
- 基于 Future 的任务并行
- 数据并行 (可嵌套和可等待的 for 循环)
- 包括任意并行归约
- 数据流并行 / 流并行 / 图并行 / 流水线并行
- 结构化并行
线程池的并行 for 循环使用惰性循环分割,并且完全适应于正在调度的 工作 负载,正在运行的线程负载和硬件速度,这与大多数(所有?)运行时不同,请参见:
- 取决于硬件和 工作 负载的 OpenMP 问题:https://github.com/zy97140/omp-benchmark-for-pytorch
- 光线追踪的理想运行时,适应像素计算负载:
 \
大多数(全部?)生产运行时使用调度 A(像 GCC OpenMP 一样在线程数上分割)或 B(像 LLVM/Intel OpenMP 或 Intel TBB 一样进行积极分割,无法适应实际 工作),而 Constantine 使用 C。
\
大多数(全部?)生产运行时使用调度 A(像 GCC OpenMP 一样在线程数上分割)或 B(像 LLVM/Intel OpenMP 或 Intel TBB 一样进行积极分割,无法适应实际 工作),而 Constantine 使用 C。
线程池提供有效的退避策略,以基于以下因素节省电力:
- eventcounts / futexes,用于低开销退避
- log-log 迭代退避,一种经过验证的最优退避策略,用于无线通信,以最小化并行 for 循环中的通信
Weave 仓库中提供了有关高性能多线程的研究论文:https://github.com/mratsim/weave/tree/7682784/research.\ 注意:线程池不是由 Weave 支持的,而是由一个受启发的运行时支持的,该运行时已大大简化以方便审计。特别是,它使用基于共享内存的 工作 窃取而不是基于通道的 工作 请求来进行负载平衡,因为分布式计算不是目标,但...。
编译器注意事项
不幸的是,编译器,特别是 GCC,在优化大整数和/或密码学代码方面不是很出色,即使使用 addcarry_u64 等内在函数也是如此。
对 addcarry_u64 提供适当支持的编译器,如 Clang,MSVC 和 ICC
可能会生成比 GCC 快 20~25% 的代码。
这由 GMP 团队解释:https://gmplib.org/manual/Assembly-Carry-Propagation.html 并且可以使用以下 C 代码重现。
参见 https://gcc.godbolt.org/z/2h768y
##include <stdint.h>
##include <x86intrin.h>
void add256(uint64_t a[4], uint64_t b[4]){
uint8_t carry = 0;
for (int i = 0; i < 4; ++i)
carry = _addcarry_u64(carry, a[i], b[i], &a[i]);
}GCC
add256:
movq (%rsi), %rax
addq (%rdi), %rax
setc %dl
movq %rax, (%rdi)
movq 8(%rdi), %rax
addb $-1, %dl
adcq 8(%rsi), %rax
setc %dl
movq %rax, 8(%rdi)
movq 16(%rdi), %rax
addb $-1, %dl
adcq 16(%rsi), %rax
setc %dl
movq %rax, 16(%rdi)
movq 24(%rsi), %rax
addb $-1, %dl
adcq %rax, 24(%rdi)
retClang
add256:
movq (%rsi), %rax
addq %rax, (%rdi)
movq 8(%rsi), %rax
adcq %rax, 8(%rdi)
movq 16(%rsi), %rax
adcq %rax, 16(%rdi)
movq 24(%rsi), %rax
adcq %rax, 24(%rdi)
retq内联汇编
虽然使用内在函数可以显着提高代码的可读性,可移植性,可审计性和可维护性, 但 Constantine 在 x86-64 上使用内联汇编,以确保在优化不佳(对于 GCC)的情况下仍具有性能可移植性, 并且还使用编译器无法生成的专用大整数指令 MULX,ADCX,ADOX。
在 BLS12-381(6 limbs)上,使用 MULX,ADCX,ADOX 可以将有限域算法的速度提高多达 60%。
最后,汇编是确保恒定时间属性并避免编译器将精心设计的 无分支代码转换为分支的必要条件,请参见 与编译器作斗争 (wiki)。
总而言之,纯 C/C++/Nim 意味着:
- 一个聪明的编译器可能会揭示恒定时间位操作并重新引入分支。
- 使用 GCC 会产生显着的性能成本(比 Clang 慢约 50%)。
- 错过了对支持 MULX/ADCX/ADOX 指令的最新 CPU 的机会(比 Clang 快约 60%)。
- 使用纯 GCC 与使用带有内联汇编的 GCC 之间的性能比为 2.4 倍。
大小:代码大小,堆栈使用量
由于对于与 RSA 相同的安全级别而言,密钥大小小 10 倍,因此椭圆曲线密码学 已广泛用于资源受限的设备上。
Constantine 正在积极优化代码大小和堆栈使用量。 Constantine 不使用堆分配。
目前,Constantine 针对 32 位和 64 位 CPU 进行了优化。
当性能和代码大小发生冲突时,会选择一个经过仔细考虑和知情的默认值。
将来,可能会提供一个超出编译器 -Os 的编译时标志。
- 原文链接: github.com/mratsim/const...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





