TFHE-rs v0.7:密文压缩、多 GPU 支持及更多
- ZamaFHE
- 发布于 2024-07-06 16:24
- 阅读 1297
TFHE-rs v0.7 版本发布,引入了密文压缩和多 GPU 支持等重要特性。密文压缩可将密文大小最多减少 1900 倍,而多 GPU 支持能够显著提升同态计算的性能,文章还介绍了新版本中参数集合的更新、新的向量和数组运算、优化的零知识证明以及优化的 GPU 密钥切换等额外功能。
TFHE-rs v0.7 现在支持压缩对同态计算结果进行加密的密文。这项新功能在提供的参数下,可将密文大小最多减少 1,900 倍! 此外,TFHE-rs v0.7 允许用户利用广泛部署在服务器上的多 GPU 架构,从而大幅提高计算性能。 与往常一样,此版本引入了大量新功能和改进,如下详述!
同态计算后压缩密文
FHE 实现的挑战之一是密文的大小。 默认情况下,明文的 1 位与其加密等效值之间的比率约为 8,200,这意味着密文中需要 8,200 位数据才能表示明文中的 1 位数据。 自 v0.2 以来,TFHE-rs 一直支持输入压缩; 但是,直到现在才有可能减小密文的后计算大小。 从 v0.7 此版本开始,现在可以在程序的任何时候压缩密文。
目前,后计算压缩仅适用于少数参数集,如下面的代码片段所示。 具有这些参数的压缩密文列表最多可以有 256 个槽,每个槽能够包含 2 位的加密数据。 例如,8 个 FheUint64 值可以最佳地存储在一个列表中。 表 1 提供了密文大小和压缩比的摘要。
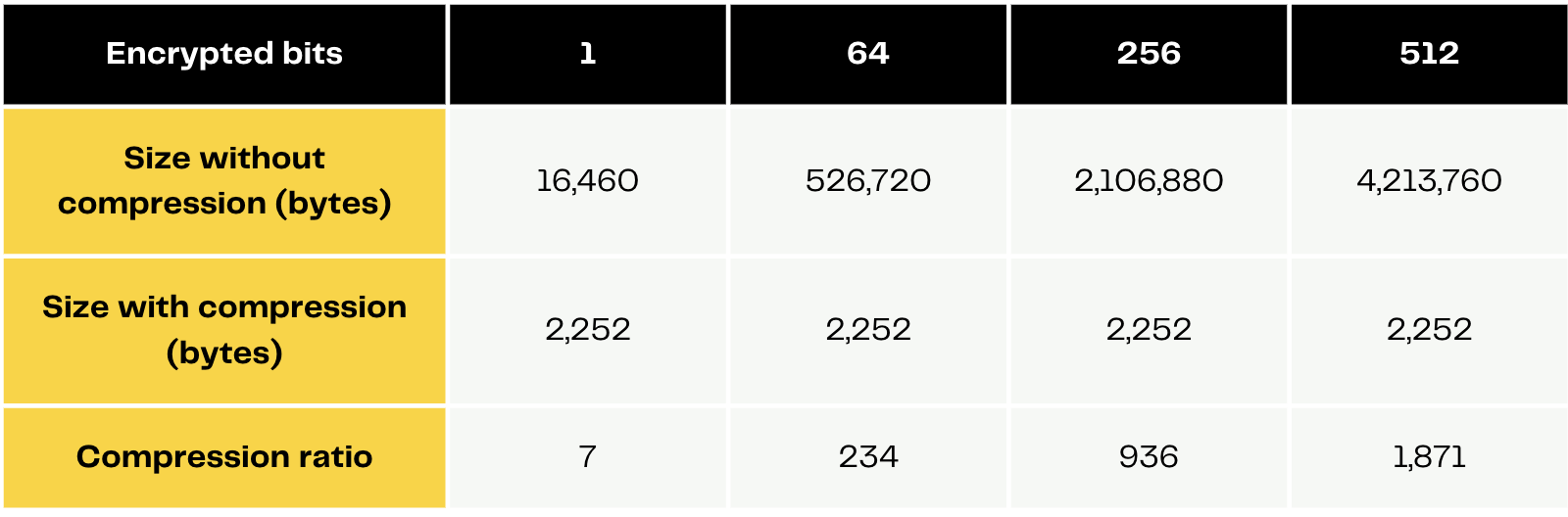
表 1:压缩密文的大小与明文位数的函数关系。
以下示例演示了如何使用 TFHE-rs 和新引入的 CompressedCiphertextList 压缩密文。 它是异构的,因此允许将任何类型的密文存储在一起,例如 FheUint32、FheUint16、FheBool 等。如果输入位数超过最大阈值,则列表会自动拆分为多个列表。
use tfhe::prelude::*;
use tfhe::shortint::parameters::{COMP_PARAM_MESSAGE_2_CARRY_2, PARAM_MESSAGE_2_CARRY_2};
use tfhe::{
set_server_key, CompressedCiphertextListBuilder, FheBool, FheInt64, FheUint2, FheUint32,
};
fn main() {
let config = tfhe::ConfigBuilder::with_custom_parameters(PARAM_MESSAGE_2_CARRY_2, None)
.enable_compression(COMP_PARAM_MESSAGE_2_CARRY_2)
.build();
let ck = tfhe::ClientKey::generate(config);
let sk = tfhe::ServerKey::new(&ck);
set_server_key(sk);
let ct1 = FheUint32::encrypt(17_u32, &ck);
let ct2 = FheInt64::encrypt(-1i64, &ck);
let ct3 = FheBool::encrypt(false, &ck);
let ct4 = FheUint2::encrypt(3u8, &ck);
let serialized_ct1 = bincode::serialize(&ct1).unwrap();
let serialized_ct2 = bincode::serialize(&ct2).unwrap();
let serialized_ct3 = bincode::serialize(&ct3).unwrap();
let serialized_ct4 = bincode::serialize(&ct4).unwrap();
let uncompressed_serialized_size =
serialized_ct1.len() + serialized_ct2.len() + serialized_ct3.len() + serialized_ct4.len();
println!(
"Uncompressed serialized size: {} bytes",
uncompressed_serialized_size
);
let compressed_list = CompressedCiphertextListBuilder::new()
.push(ct1)
.push(ct2)
.push(ct3)
.push(ct4)
.build()
.unwrap();
let serialized = bincode::serialize(&compressed_list).unwrap();
let compressed_serialized_size = serialized.len();
println!(
"Compressed serialized size: {} bytes",
compressed_serialized_size
);
println!(
"Compression ratio for 105 bits {}",
uncompressed_serialized_size as f64 / compressed_serialized_size as f64
);
}
使用多个 GPU 加速同态计算
TFHE-rs v0.7 首次实现了使用多个 GPU 进行同态计算,标志着性能的显著提升。无需更改代码即可在多个 GPU 上执行。为了尽可能保持 API 的用户友好性,配置是自动设置的; 用户无法对 GPU 的选择进行细粒度控制。
但是,存在某些限制:只有通过 NVLink 对 GPU 0 具有对等访问权限的 GPU 才用于计算。 根据平台的不同,这可能会限制 TFHE-rs 可以有效利用的 GPU 数量。
多 GPU 支持以及此版本中引入的一些优化,为整数运算带来了前所未有的性能。
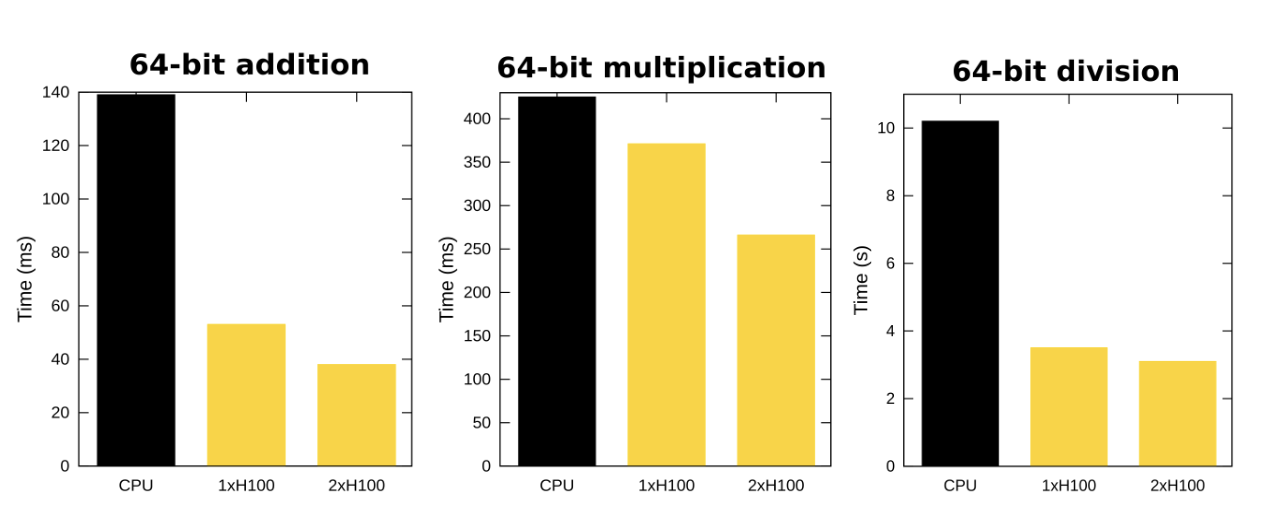
图 1:64 位加法、乘法和除法的耗时,其中两个输入已加密,在 CPU(来自 AWS 的 hpc7a.96xlarge)与一个和两个 H100 GPU 上运行。 这些参数对应于两位消息和两位进位,使用分组因子等于 3 的多位 PBS。
每个操作的最佳 GPU 数量因操作本身和用户指定的整数精度而异。 在文档中提供了所有指定精度下单 GPU 和多 GPU 的综合基准测试结果数组。
其他功能和改进
TFHE-rs v0.7 还包括一些其他新功能和性能改进:
- 更新了密码参数集: 以前,可编程自举的默认失败概率小于 2^−40。 为了降低长时间运行中出错的概率,新的参数集现在默认为 2^−64。 对性能的影响可以忽略不计。
- 新的向量和数组运算: TFHE-rs 现在包括对密文向量的运算。 例如,现在可以计算两个密文向量之间的相等性,或者检查一个向量是否包含在另一个向量中。
- 改进的零知识证明: 通过优化和用于紧凑公钥加密的专用参数集,承诺大小以及证明和验证时间都已减少。 更多详细信息和基准测试可在文档中找到。
- 优化了 GPU 上的密钥切换: 对于默认参数,密钥切换的时间已从 5.3 毫秒减少到 123 微秒,从而使可编程自举的总体延迟(包括上述密钥切换)降至 4.3 毫秒(而 TFHE-rs 的先前版本中为 9.5 毫秒)。
TFHE-rs 的下一个版本将侧重于增强多 GPU 性能,同时扩展可用操作集。
其他链接
- 收藏 TFHE-rs Github 存储库 以支持我们的工作。
- 查看 TFHE-rs 文档。
- 原文链接: zama.ai/post/tfhe-rs-v0-...
- 登链社区 AI 助手,为大家转译优秀英文文章,如有翻译不通的地方,还请包涵~





